JS高级-ES6+
[TOC]
ECMA新描述概念
新的ECMA代码执行描述
在执行学习JavaScript代码执行过程中,我们学习了很多ECMA文档的术语:
执行上下文栈:Execution Context Stack,用于执行上下文的栈结构;
执行上下文:Execution Context,代码在执行之前会先创建对应的执行上下文;
变量对象:Variable Object,上下文关联的VO对象,用于记录函数和变量声明;
全局对象:Global Object,全局执行上下文关联的VO对象;
激活对象:Activation Object,函数执行上下文关联的VO对象;
作用域链:scope chain,作用域链,用于关联指向上下文的变量查找;
在新的ECMA代码执行描述中(ES5以及之上),对于代码的执行流程描述改成了另外的一些词汇:
基本思路是相同的,只是对于一些词汇的描述发生了改变;
执行上下文栈和执行上下文也是相同的;
新ECMA中代码执行流程描述:
- 词法环境:Lexical Environments
- 环境记录:Environment Record
- 声明式环境记录:declarative Environment Record
- 对象式环境记录:object Environment Record。就是window
- 外部词法环境:outer Lexical Environment
- 环境记录:Environment Record
- 变量环境:VariableEnvironment
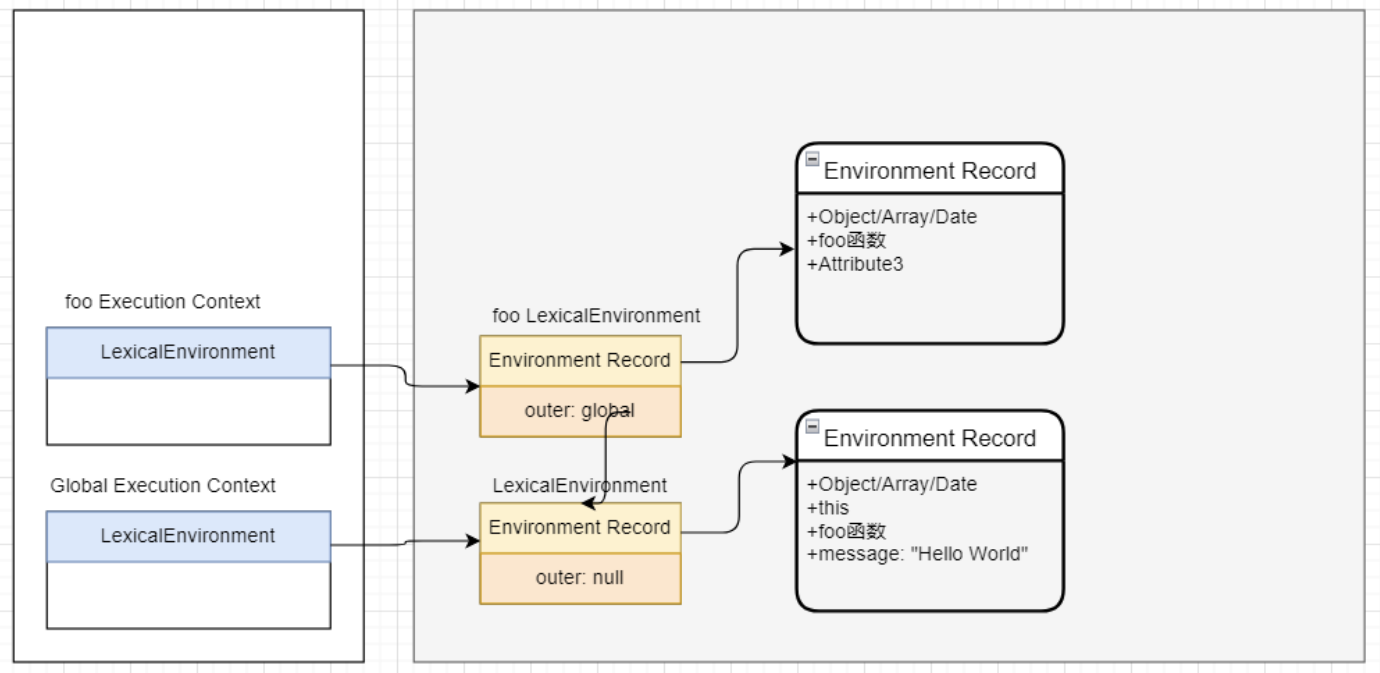
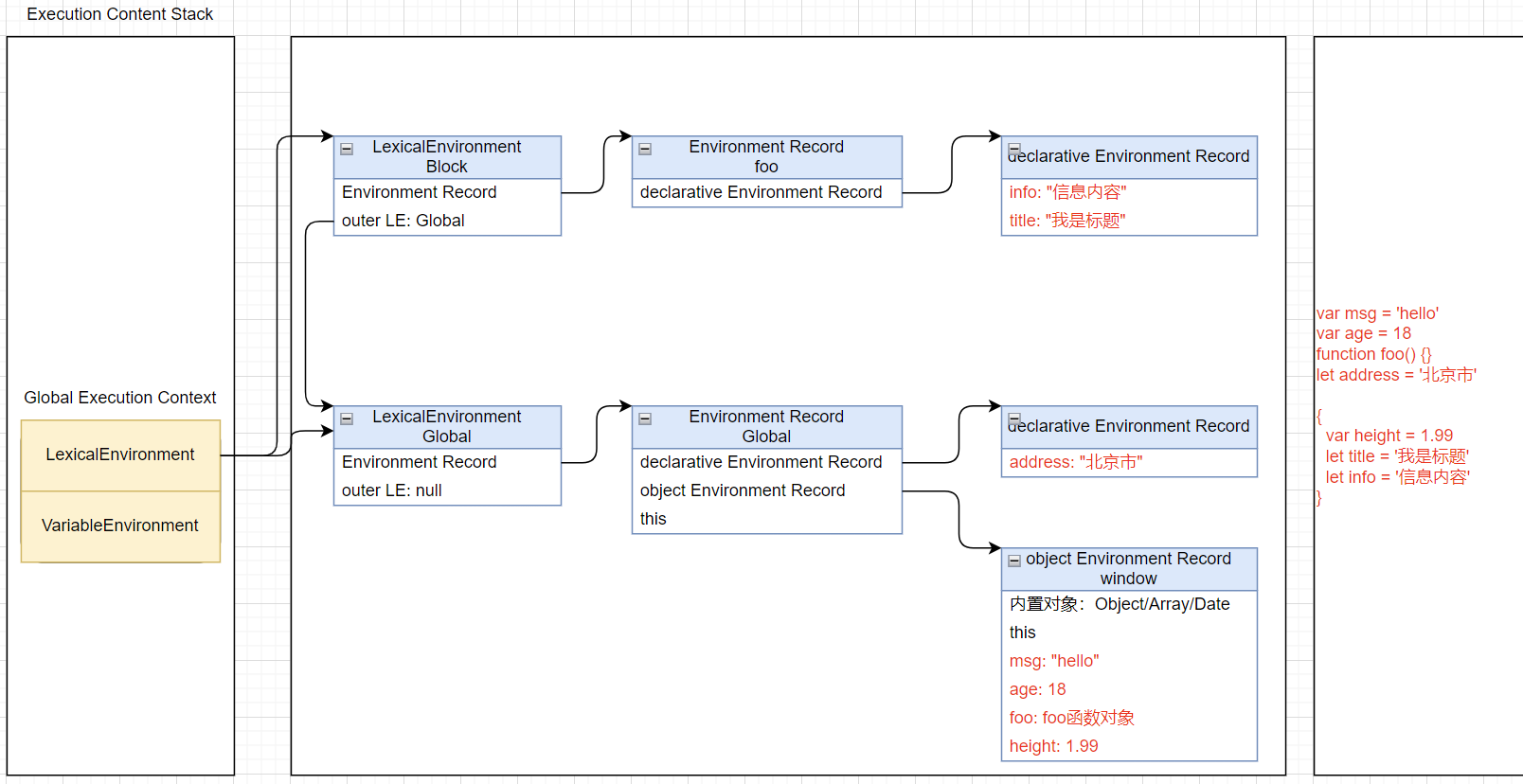
词法环境(Lexical Environments)
词法环境是一种规范类型,用于在词法嵌套结构中定义关联的变量、函数等标识符;
一个词法环境是由环境记录(Environment Record)和一个外部词法环境(outer Lexical Environment)组成;
一个词法环境经常用于关联一个函数声明、代码块语句、try-catch语句,当它们的代码被执行时,词法环境被创建出来;

也就是在ES5之后,执行一个代码,通常会关联对应的词法环境;
- 那么执行上下文会关联哪些词法环境呢?

LexicalEnvironment和VariableEnvironment
LexicalEnvironment用于处理let、const声明的标识符:

VariableEnvironment用于处理var和function声明的标识符:

环境记录(Environment Record)
在这个规范中有两种主要的环境记录值:声明式环境记录和对象环境记录。
声明式环境记录:声明性环境记录用于定义ECMAScript语言语法元素的效果,如函数声明、变量声明和直接将标识符绑定与ECMAScript语言值关联起来的Catch子句。
对象式环境记录:对象环境记录用于定义ECMAScript元素的效果,例如WithStatement,它将标识符绑定与某些对象的属性关联起来。

新ECMA描述内存图
let、const
let/const基本使用
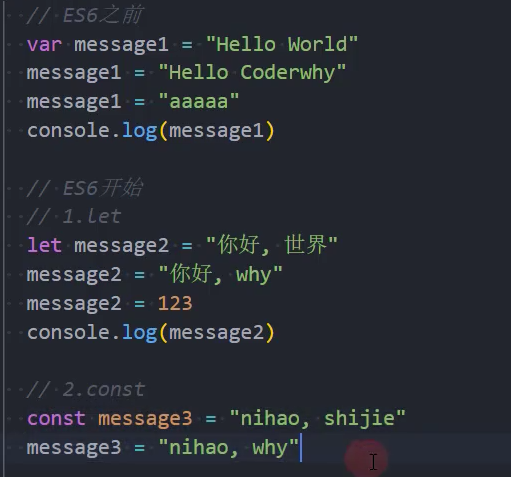
在ES5中我们声明变量都是使用的var关键字,从ES6开始新增了两个关键字可以声明变量:let、const
let、const在其他编程语言中都是有的,所以也并不是新鲜的关键字;
但是let、const确确实实给JavaScript带来一些不一样的东西;
let关键字:
- 从直观的角度来说,let和var是没有太大的区别的,都是用于声明一个变量;
const关键字:
const关键字是constant的单词的缩写,表示常量、衡量的意思;
它表示保存的数据一旦被赋值,就不能被修改;
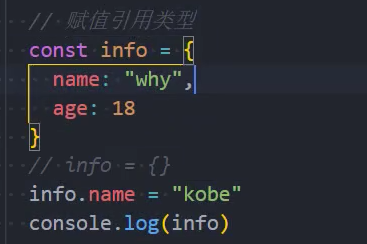
但是如果赋值的是引用类型,那么可以通过引用找到对应的对象,修改对象的内容;
注意:
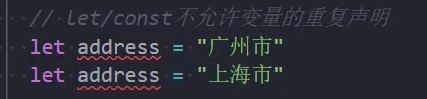
- 另外let、const不允许重复声明变量;
示例: 基本使用
示例: 如果赋值的是引用类型,可以修改引用对象内部的内容
示例: let、const不允许重复声明变量

面试:let/const有作用域提升吗?
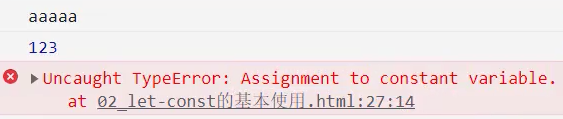
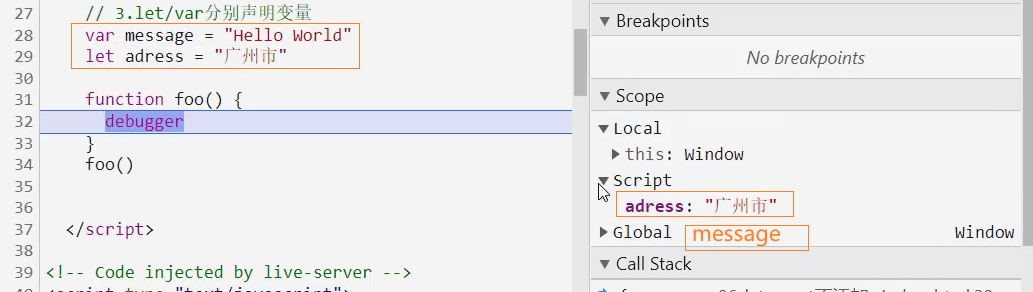
let、const和var的另一个重要区别是作用域提升:
- 我们知道var声明的变量是会进行作用域提升的;
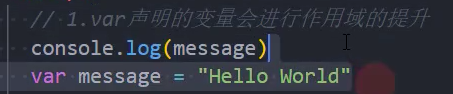
- 但是如果我们使用let声明的变量,在声明之前访问会报错;

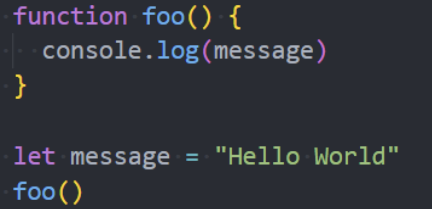
那么是不是意味着foo变量只有在代码执行阶段才会创建的呢?
事实上并不是这样的,我们可以看一下ECMA262对let和const的描述;
这些变量会被创建在包含他们的词法环境被实例化时,但是此时是不可以访问它们的,直到词法绑定被求值;

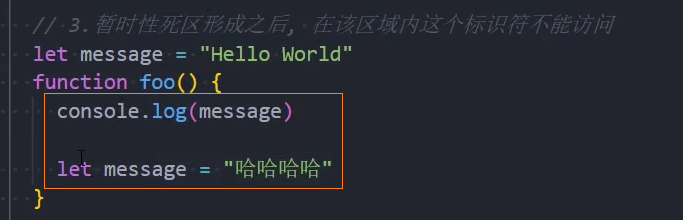
暂时性死区 (TDZ)
我们知道,在let、const定义的标识符真正执行到声明的代码之前,是不能被访问的
- 从块作用域的顶部一直到变量声明完成之前,这个变量处在暂时性死区(TDZ,temporal dead zone)

使用术语 “temporal” 是因为区域取决于执行顺序(时间),而不是编写代码的位置;
let/const有没有作用域提升呢?
从上面我们可以看出,在执行上下文的词法环境创建出来的时候,变量事实上已经被创建了,只是这个变量是不能被访问的。
- 那么变量已经有了,但是不能被访问,是不是一种作用域的提升呢?
事实上维基百科并没有对作用域提升有严格的概念解释,那么我们自己从字面量上理解;
*作用域提升:*在声明变量的作用域中,如果这个变量可以在声明之前被访问,那么我们可以称之为作用域提升;
在这里,它虽然被创建出来了,但是不能被访问,我认为不能称之为作用域提升;
所以我的观点是let、const没有进行作用域提升,但是会在解析阶段被创建出来。
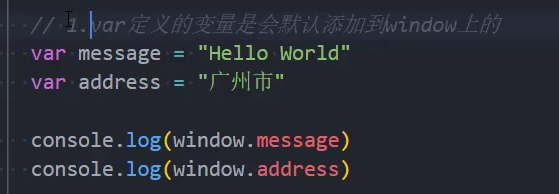
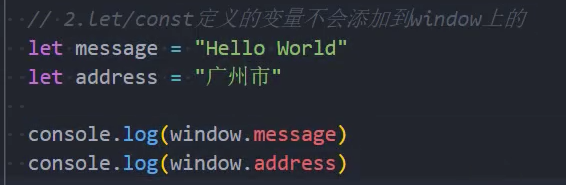
Window对象添加属性
我们知道,在全局通过var来声明一个变量,事实上会在window上添加一个属性:
- 但是let、const是不会给window上添加任何属性的。
那么我们可能会想这个变量是保存在哪里呢?

示例:
块级作用域
var的块级作用域
在我们前面ES5的学习中,JavaScript只会形成两个作用域:全局作用域和函数作用域。

ES5中放到一个代码中定义的变量,外面是可以访问的:


let/const的块级作用域
在ES6中新增了块级作用域,并且通过let、const、function、class声明的标识符是具备块级作用域的限制的:
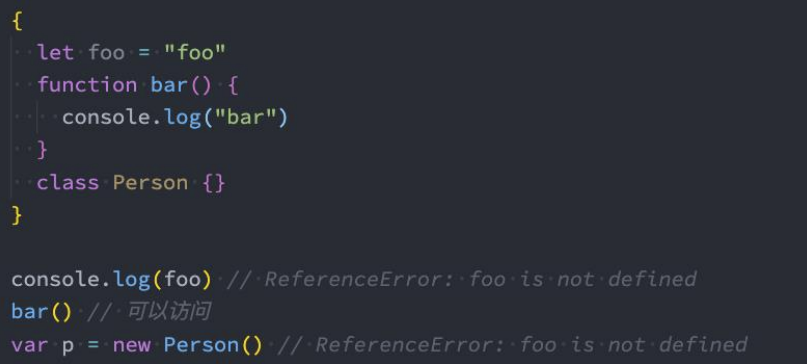

注意:但是我们会发现函数拥有块级作用域,但是外面依然是可以访问的:
- 这是因为引擎会对函数的声明进行特殊的处理,允许像var一样在外界后面直接访问;
块级作用域的应用
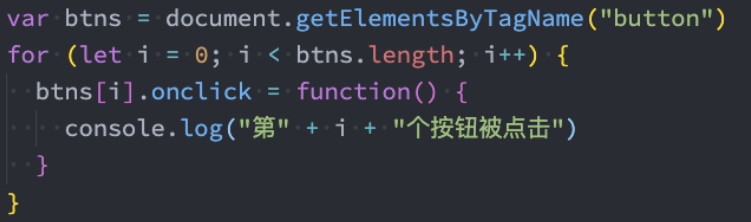
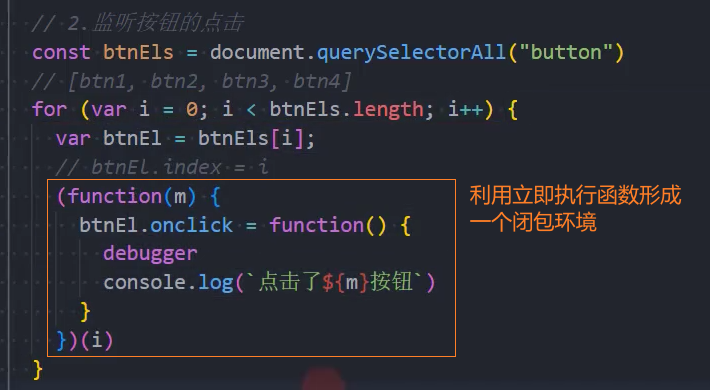
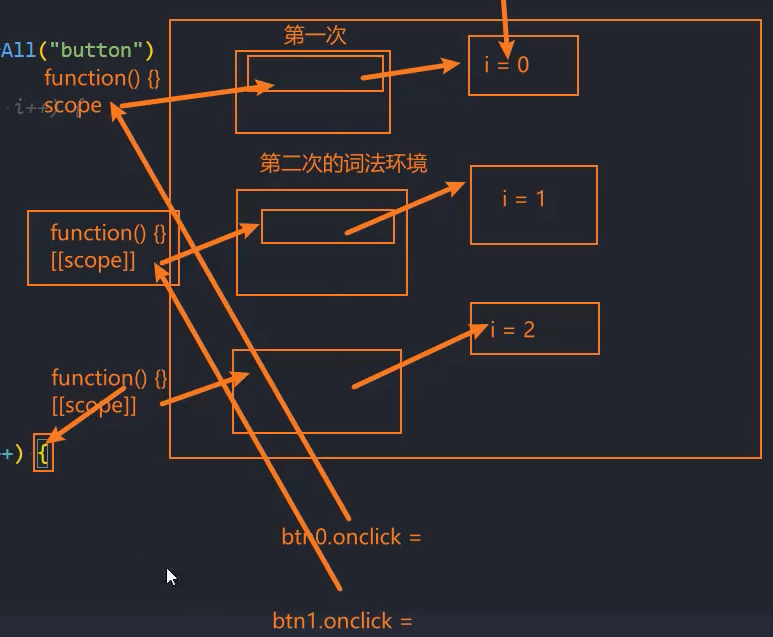
我来看一个实际的案例:获取多个按钮监听点击
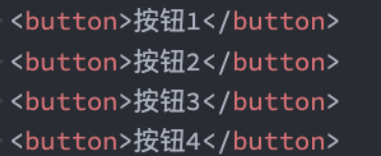
使用let或者const来实现:
var、let、const的选择
那么在开发中,我们到底应该选择使用哪一种方式来定义我们的变量呢?
对于var的使用:
我们需要明白一个事实,var所表现出来的特殊性:比如作用域提升、window全局对象、没有块级作用域等都是一些历史遗留问题;
其实是JavaScript在设计之初的一种语言缺陷;
当然目前市场上也在利用这种缺陷出一系列的面试题,来考察大家对JavaScript语言本身以及底层的理解;
但是在实际工作中,我们可以使用最新的规范来编写,也就是不再使用var来定义变量了;
对于let、const:
对于let和const来说,是目前开发中推荐使用的;
我们会优先推荐使用const,这样可以保证数据的安全性不会被随意的篡改;
只有当我们明确知道一个变量后续会需要被重新赋值时,这个时候再使用let;
这种在很多其他语言里面也都是一种约定俗成的规范,尽量我们也遵守这种规范;
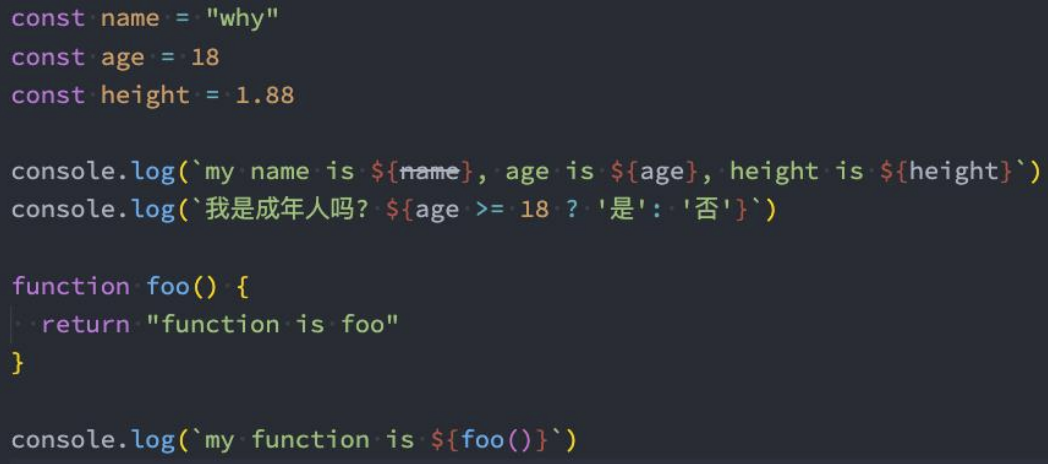
模板字符串
模板字符串-基本使用
在ES6之前,如果我们想要将字符串和一些动态的变量(标识符)拼接到一起,是非常麻烦和丑陋的(ugly)。
ES6允许我们使用模板字符串来嵌入JS的变量或者表达式来进行拼接:
首先,我们会使用 `` 符号来编写字符串,称之为模板字符串;
其次,在模板字符串中,我们可以通过 ${expression} 来嵌入动态的内容;
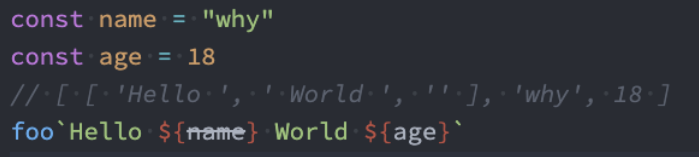
标签模板字符串-基本使用
模板字符串还有另外一种用法:标签模板字符串(Tagged Template Literals)。
我们一起来看一个普通的JavaScript的函数:
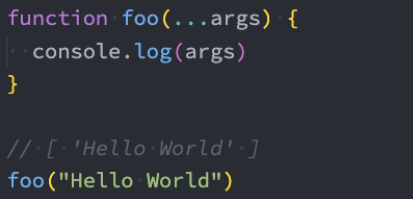
如果我们使用标签模板字符串,并且在调用的时候插入其他的变量
模板字符串被拆分了;
第一个元素是数组,是被模块字符串拆分的字符串组合;
后面的元素是一个个模块字符串传入的内容;
应用: React的styled-components库
ES6函数用法增强
函数的默认参数
在ES6之前,我们编写的函数参数是没有默认值的,所以我们在编写函数时,如果有下面的需求:
传入了参数,那么使用传入的参数;
没有传入参数,那么使用一个默认值;
而在ES6中,我们允许给函数一个默认值:
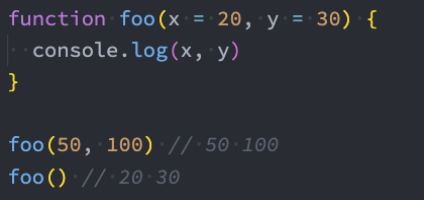
严谨的默认值写法

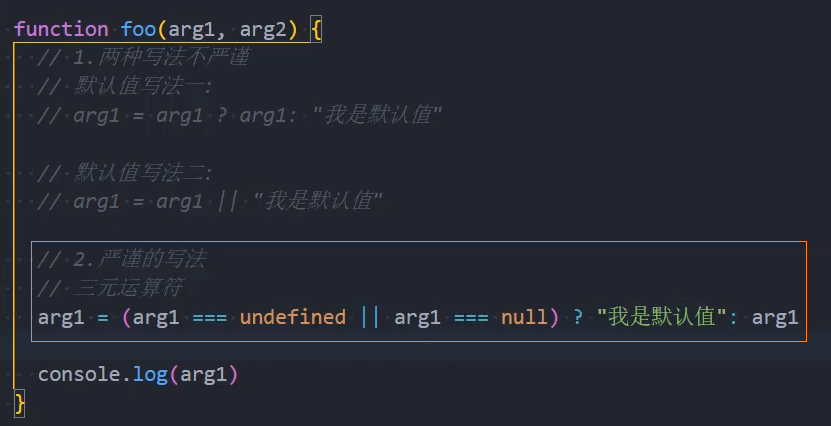

函数默认值的注意事项
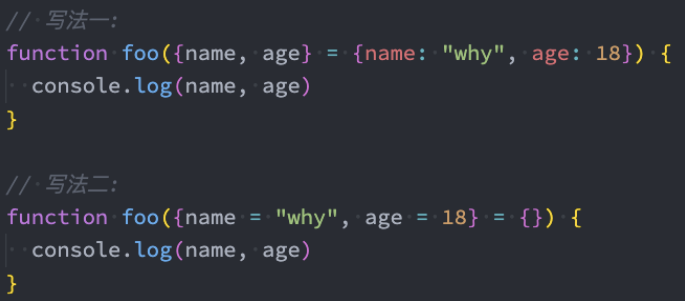
1、默认值也可以和解构一起来使用:
2、另外参数的默认值我们通常会将其放到最后(在很多语言中,如果不放到最后其实会报错的):
- 但是JavaScript允许不将其放到最后,但是意味着还是会按照顺序来匹配;
3、另外默认值会改变函数的length的个数,默认值以及后面的参数都不计算在length之内了。
函数的剩余参数(已经学习)
ES6中引用了rest parameter,可以将不定数量的参数放入到一个数组中:
- 如果最后一个参数是 ... 为前缀的,那么它会将剩余的参数放到该参数中,并且作为一个数组;
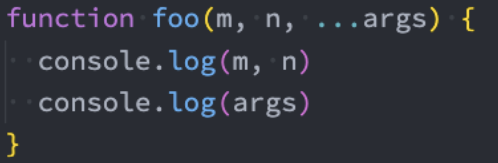
那么剩余参数和arguments有什么区别呢?
剩余参数只包含那些没有对应形参的实参,而 arguments 对象包含了传给函数的所有实参;
arguments对象不是一个真正的数组,而rest参数是一个真正的数组,可以进行数组的所有操作;
arguments是早期的ECMAScript中为了方便去获取所有的参数提供的一个数据结构,而rest参数是ES6中提供并且希望以此来替代arguments的;
注意:剩余参数必须放到最后一个位置,否则会报错。
函数箭头函数的补充
在前面我们已经学习了箭头函数的用法,这里进行一些补充:
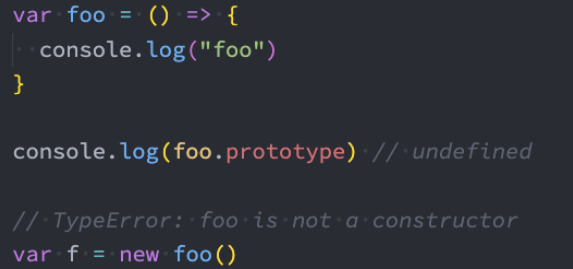
箭头函数是没有显式原型prototype的,所以不能作为构造函数,使用new来创建对象;
箭头函数也不绑定this、arguments、super参数;

展开语法
展开语法(Spread syntax):
可以在函数调用/数组构造时,将数组表达式或者string在语法层面展开;
还可以在构造字面量对象时, 将对象表达式按key-value的方式展开;
展开语法的场景:
在函数调用时使用;
在数组构造时使用;
在构建对象字面量时,也可以使用展开运算符,这个是在ES2018(ES9)中添加的新特性;
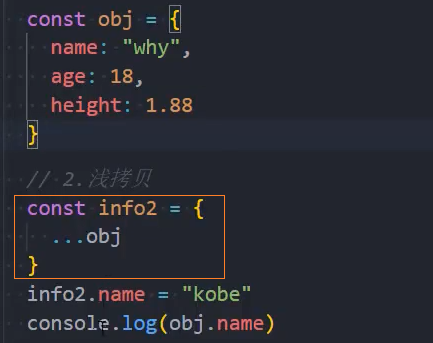
注意:展开运算符其实是一种浅拷贝;
引用赋值、浅拷贝、深拷贝
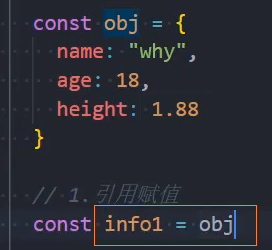
引用赋值
浅拷贝
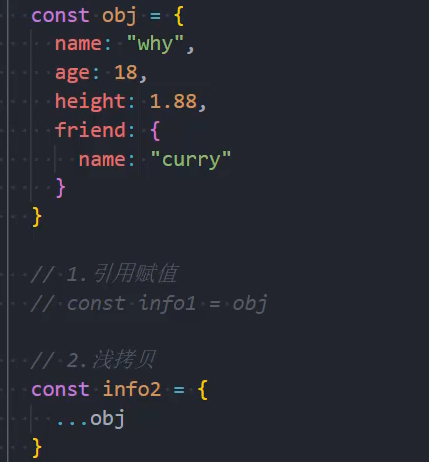
深拷贝
数值的表示
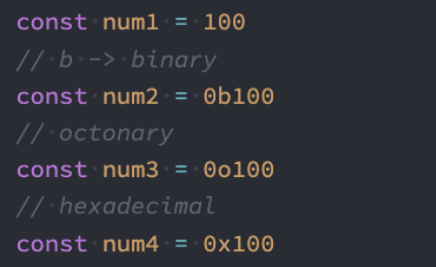
在ES6中规范了二进制和八进制的写法:
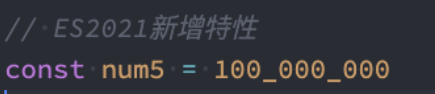
另外在ES2021新增特性:数字过长时,可以使用_作为连接符
Symbol
基本使用
Symbol是什么呢?Symbol是ES6中新增的一个基本数据类型,翻译为符号。
那么为什么需要Symbol呢?
在ES6之前,对象的属性名都是字符串形式,那么很容易造成属性名的冲突;
比如原来有一个对象,我们希望在其中添加一个新的属性和值,但是我们在不确定它原来内部有什么内容的情况下,很容易造成冲突,从而覆盖掉它内部的某个属性;
比如我们前面在讲apply、call、bind实现时,我们有给其中添加一个fn属性,那么如果它内部原来已经有了fn属性了呢?
比如开发中我们使用混入,那么混入中出现了同名的属性,必然有一个会被覆盖掉;
Symbol就是为了解决上面的问题,用来生成一个独一无二的值。
Symbol值是通过Symbol()函数来生成的,生成后可以作为属性名;
也就是在ES6中,对象的属性名可以使用字符串,也可以使用Symbol值;
*Symbol即使多次创建值,它们也是不同的:*Symbol函数执行后每次创建出来的值都是独一无二的;
我们也可以在创建Symbol值的时候传入一个描述description:这个是ES2019(ES10)新增的特性;
语法
const s1 = Symbol(desc?)Symbol作为属性名
我们通常会使用Symbol在对象中表示唯一的属性名:

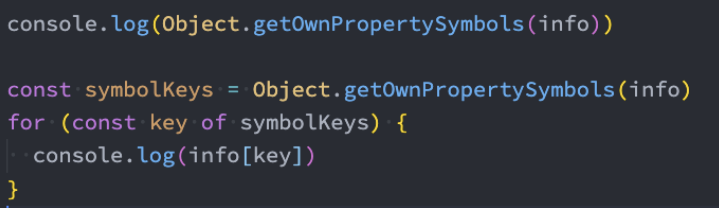
获取对象中的所有Symbol的key
创建相同值的Symbol
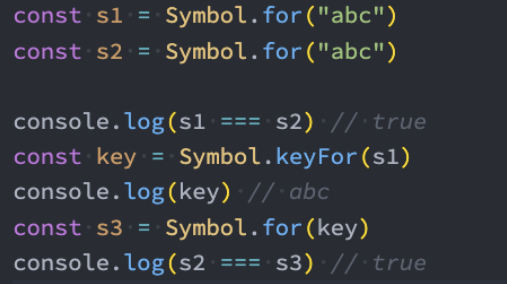
前面我们讲Symbol的目的是为了创建一个独一无二的值,那么如果我们现在就是想创建相同的Symbol应该怎么来做呢?
我们可以使用Symbol.for方法来做到这一点;
并且我们可以通过Symbol.keyFor方法来获取对应的description;
Set
基本使用
在ES6之前,我们存储数据的结构主要有两种:数组、对象。
在ES6中新增了另外两种数据结构:Set、Map,以及它们的另外形式WeakSet、WeakMap。
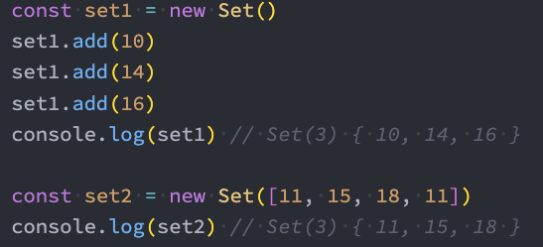
Set是一个新增的数据结构,可以用来保存数据,类似于数组,但是和数组的区别是元素不能重复。
- 创建Set我们需要通过Set构造函数(暂时没有字面量创建的方式):
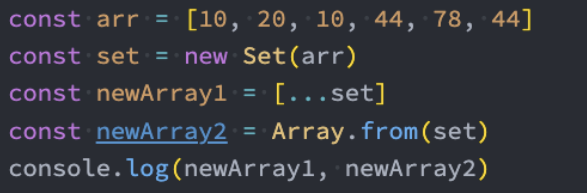
我们可以发现Set中存放的元素是不会重复的,那么Set有一个非常常用的功能就是给数组去重。
语法:
const s1 = new Set(iterable?)参数:
- iterable: 可迭代对象
特性: set中的元素不能重复
应用: 利用set对数组进行去重
Set的常见方法
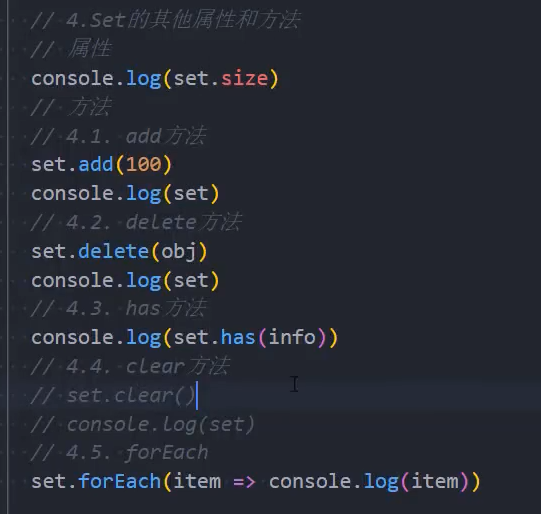
Set常见的属性:
- size:返回Set中元素的个数;
Set常用的方法:
add(value):添加某个元素,返回Set对象本身;
delete(value):从set中删除和这个值相等的元素,返回boolean类型;
has(value):判断set中是否存在某个元素,返回boolean类型;
clear():清空set中所有的元素,没有返回值;
forEach(callback, [, thisArg]):通过forEach遍历set;
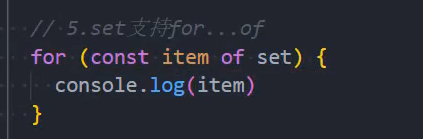
另外Set是支持for of的遍历的。
示例
WeakSet
基本使用
和Set类似的另外一个数据结构称之为WeakSet,也是内部元素不能重复的数据结构。
语法
const ws = new WeakSet(iterable?)参数:
- iterable: 可迭代对象
特性:
- WeakSet内部的元素不能重复
WeakSet和Set的区别:
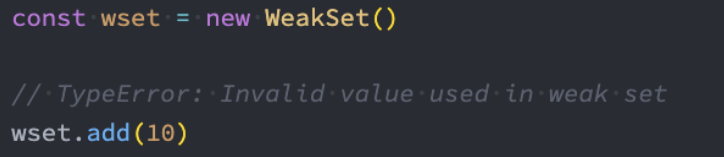
区别一:WeakSet中只能存放对象类型,不能存放基本数据类型;
区别二:WeakSet对元素的引用是弱引用,如果没有其他引用对某个对象进行引用,那么GC可以对该对象进行回收;
WeakSet常见的方法:
add(value):添加某个元素,返回WeakSet对象本身;
delete(value):从WeakSet中删除和这个值相等的元素,返回boolean类型;
has(value):判断WeakSet中是否存在某个元素,返回boolean类型;
示例: WeakSet中只能存放对象类型,不能存放基本数据类型
示例: 强引用
对于保存在数组中的对象,虽然后面被重新赋值为null,切断了引用关系,但是依然被数组中的元素所引用,所以这些对象是不会别GC回收的
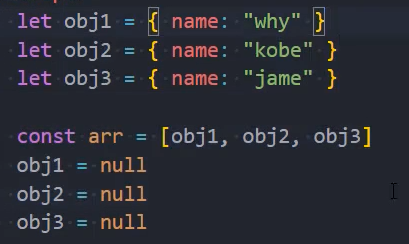
WeakSet的应用
注意:WeakSet不能遍历
因为WeakSet只是对对象的弱引用,如果我们遍历获取到其中的元素,那么有可能造成对象不能正常的销毁。
所以存储到WeakSet中的对象是没办法获取的;
应用:
那么这个东西有什么用呢?
- 事实上这个问题并不好回答,我们来使用一个Stack Overflow上的答案;
限制不能通过其他对象调用类中的方法
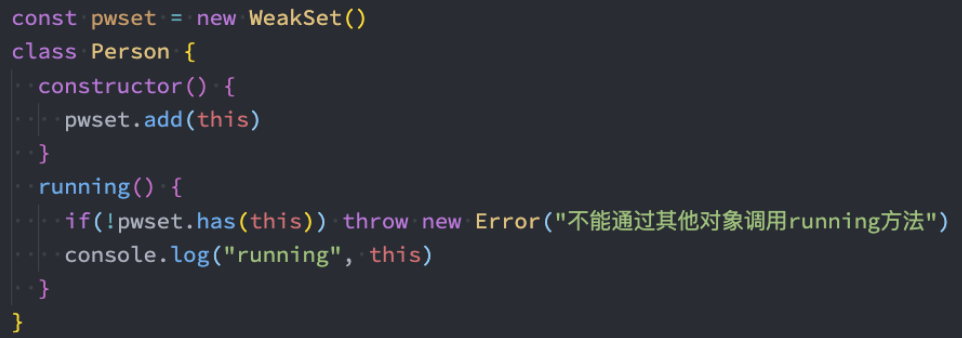
这个案例中使用WeakSet而不是Set的好处是:创建的实例如果不需要了,可以被销毁,而Set由于始终保持了对实例的引用而无法销毁实例对象
Map
Map的基本使用
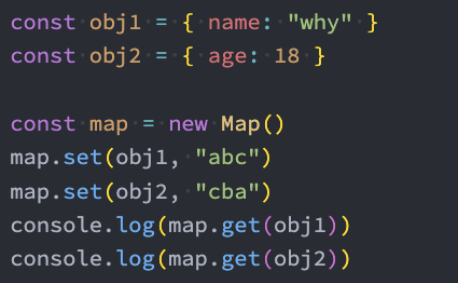
另外一个新增的数据结构是Map,用于存储映射关系。
但是我们可能会想,在之前我们可以使用对象来存储映射关系,他们有什么区别呢?
事实上我们对象存储映射关系只能用字符串(ES6新增了Symbol)作为属性名(key);
某些情况下我们可能希望通过其他类型作为key,比如对象,这个时候会自动将对象转成字符串来作为key;
那么我们就可以使用Map:
语法
const m = new Map(iterable?)参数:
- iterable:可迭代对象
Map和对象的区别
- 属性名: 对象存储时只能使用字符串和Symbol作为属性名;而Map可以使用任何值(包括对象和基本类型)作为属性名
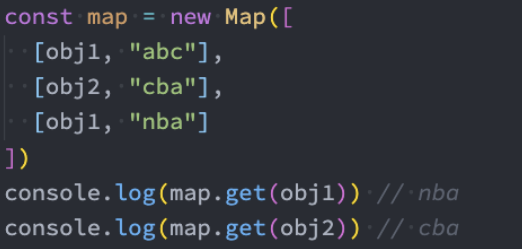
特性: Map中不能存储包含相同键的元素,可以存储包含相同值得元素
const m4 = new Map([
[1, "tom"],
[1, "jack"],
["name", "jerry"],
["nick", "jerry"],
]);
console.log("m4: ", m4); // => {1 => 'jack', 'name' => 'jerry', 'nick' => 'jerry'}Map的常用方法
Map常见的属性:
- size:返回Map中元素的个数;
Map常见的方法:
set(key, value):在Map中添加key、value,并且返回整个Map对象;
get(key):根据key获取Map中的value;
has(key):判断是否包括某一个key,返回Boolean类型;
delete(key):根据key删除一个键值对,返回Boolean类型;
clear():清空所有的元素;
forEach(callback, [, thisArg]):通过forEach遍历Map;
Map也可以通过for of进行遍历。
示例:
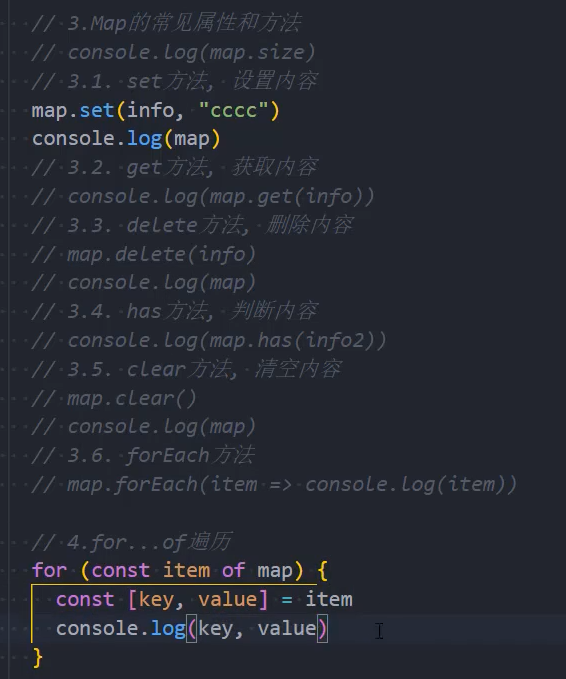
WeakMap
WeakMap的使用
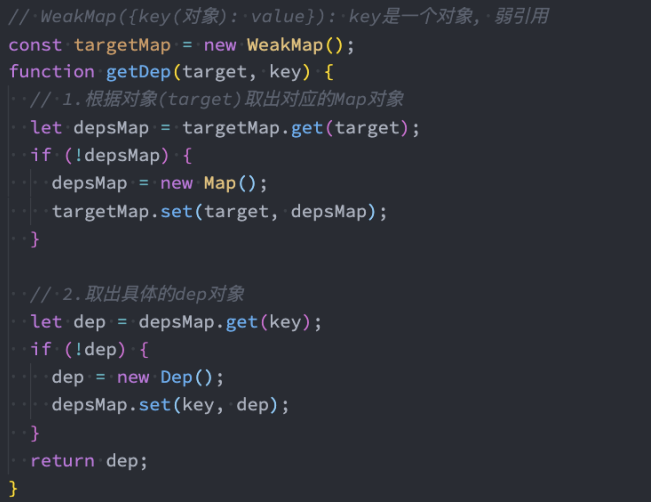
和Map类型的另外一个数据结构称之为WeakMap,也是以键值对的形式存在的。
语法:
const wm = new WeakMap(iterable?)参数:
- iterable:可迭代对象
WeakMap和Map的区别:
区别一:WeakMap的key只能使用对象,不接受其他的类型作为key;
区别二:WeakMap的key对对象的引用是弱引用,如果没有其他引用引用这个对象,那么GC可以回收该对象;

WeakMap的常见方法:
set(key, value):在Map中添加key、value,并且返回整个Map对象;
get(key):根据key获取Map中的value;
has(key):判断是否包括某一个key,返回Boolean类型;
delete(key):根据key删除一个键值对,返回Boolean类型;
WeakMap的应用
注意:WeakMap也是不能遍历的
- 没有forEach方法,也不支持通过for of的方式进行遍历;
那么我们的WeakMap有什么作用呢?(后续专门讲解)
ES6其他知识点说明
事实上ES6(ES2015)是一次非常大的版本更新,所以里面重要的特性非常多:
- 除了前面讲到的特性外还有很多其他特性;
Proxy、Reflect,我们会在后续专门进行学习。
- 并且会利用Proxy、Reflect来讲解Vue3的响应式原理;
Promise,用于处理异步的解决方案
后续会详细学习;
并且会学习如何手写Promise;
ES Module模块化开发:
从ES6开发,JavaScript可以进行原生的模块化开发;
这部分内容会在工程化部分学习;
包括其他模块化方案:CommonJS、AMD、CMD等方案;
ES7
ES7 - includes
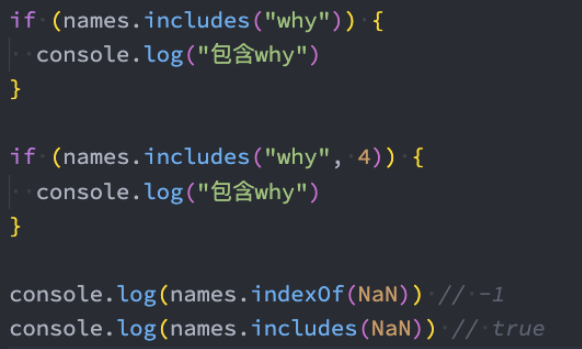
在ES7之前,如果我们想判断一个数组中是否包含某个元素,需要通过 indexOf 获取结果,并且判断是否为 -1。
在ES7中,我们可以通过includes来判断一个数组中是否包含一个指定的元素,根据情况,如果包含则返回 true,否则返回false。

ES7 –指数运算符
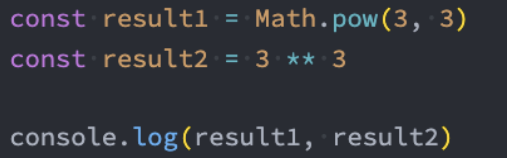
在ES7之前,计算数字的乘方需要通过 Math.pow 方法来完成。
在ES7中,增加了 ** 运算符,可以对数字来计算乘方。
ES8
Object.values
之前我们可以通过 Object.keys 获取一个对象所有的key
在ES8中提供了 Object.values 来获取所有的value值:

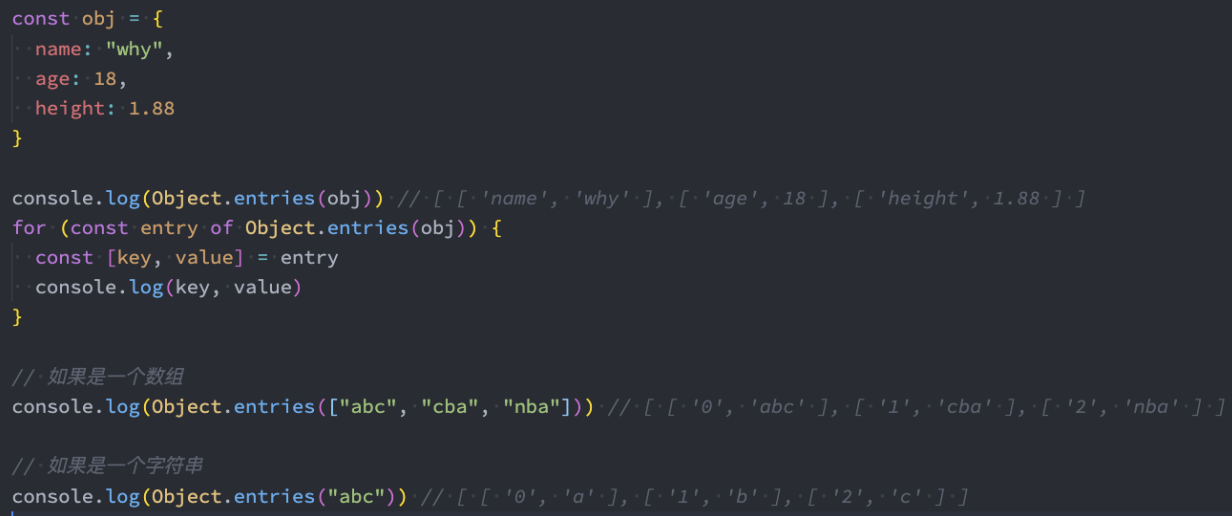
Object.entries
通过 Object.entries 可以获取到一个数组,数组中会存放可枚举属性的键值对数组。
- 可以针对对象、数组、字符串进行操作;
padStart,padEnd
某些字符串我们需要对其进行前后的填充,来实现某种格式化效果,ES8中增加了 padStart 和 padEnd 方法,分别是对字符串的首尾进行填充的。

应用: 对身份证、银行卡的前面位数进行隐藏:

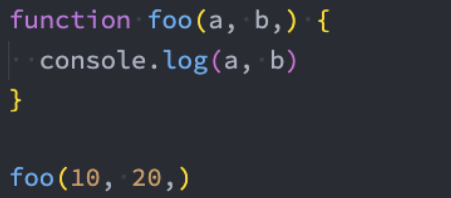
尾部逗号
在ES8中,我们允许在函数定义和调用时多加一个逗号:
Object Descriptors
Object.getOwnPropertyDescriptors
- 这个在之前已经讲过了,这里不再重复。
Async Function:async、await
- 后续讲完Promise讲解
ES9
ES9新增知识点
Async iterators:后续迭代器讲解
Object spread operators:前面讲过了
Promise finally:后续讲Promise讲解
ES10
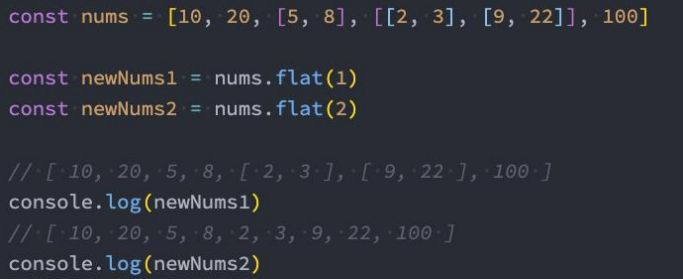
flat、flatMap
flat() 方法会按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
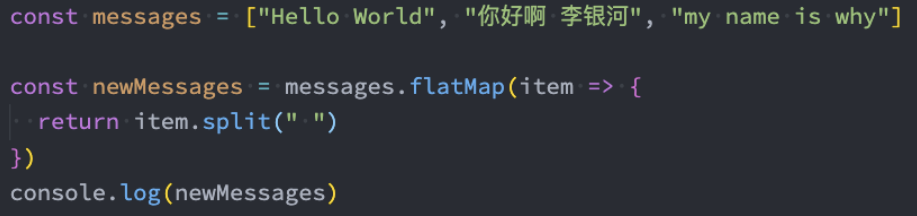
flatMap() 方法首先使用映射函数映射每个元素,然后将结果压缩成一个新数组。
注意一:flatMap是先进行map操作,再做flat的操作;
注意二:flatMap中的flat相当于深度为1;
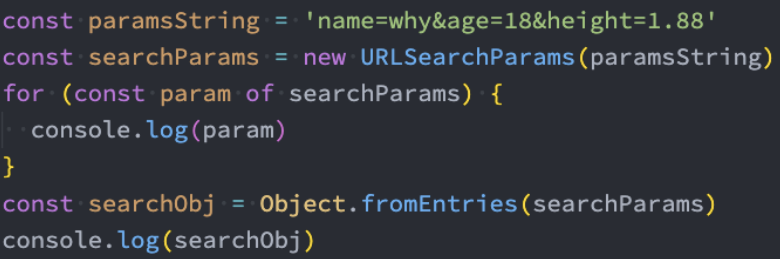
Object.fromEntries
在前面,我们可以通过 Object.entries 将一个对象转换成 entries
那么如果我们有一个entries了,如何将其转换成对象呢?
- ES10提供了 Object.formEntries来完成转换:
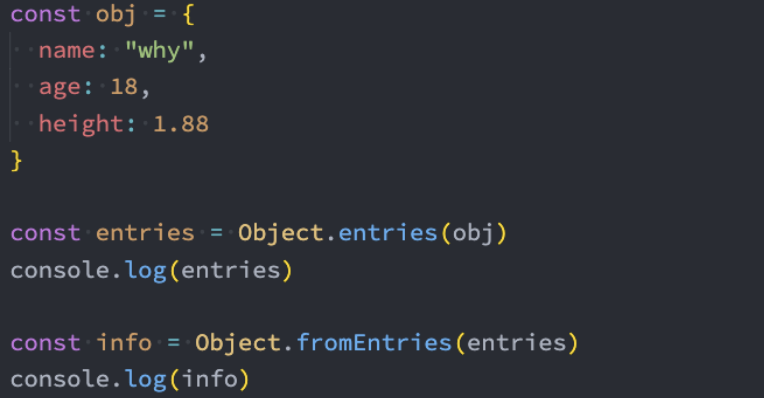
应用: 那么这个方法有什么应用场景呢?
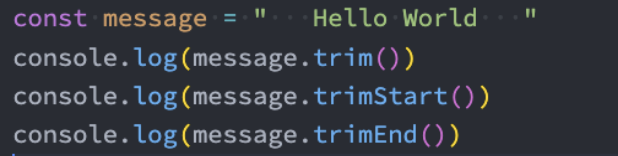
trimStart、trimEnd
去除一个字符串首尾的空格,我们可以通过trim方法,如果单独去除前面或者后面呢?
- ES10中给我们提供了trimStart和trimEnd;
ES10 其他知识点
Symbol description:已经讲过了
Optional catch binding:后面讲解try cach讲解
ES11
BigInt
在早期的JavaScript中,我们不能正确的表示过大的数字:
- 大于MAX_SAFE_INTEGER的数值,表示的可能是不正确的。
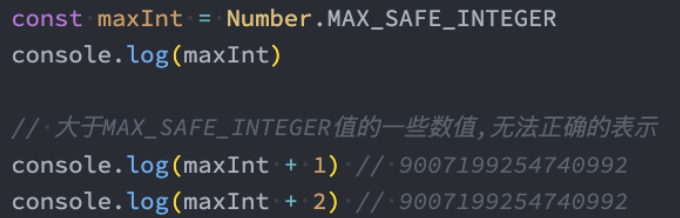
那么ES11中,引入了新的数据类型BigInt,用于表示大整数:
- BigInt的表示方法是在数值的后面加上n

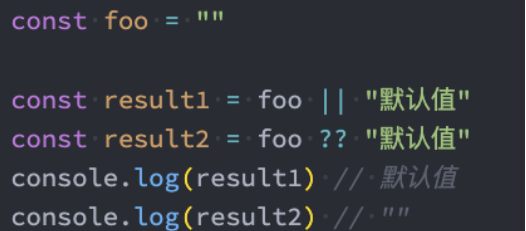
空值合并运算符
ES11,Nullish Coalescing Operator增加了空值合并运算符(??):
当foo是undefined或null时,取默认值
可选链
可选链(?.)也是ES11中新增一个特性,主要作用是让我们的代码在进行null和undefined判断时更加清晰和简洁:
语法
obj.val?.prop // 示例:obj.friend?.name
obj.val?.[expr] // 示例:obj.friends?.[0]
obj.func?.(args) // 示例:obj.friend?.running?.()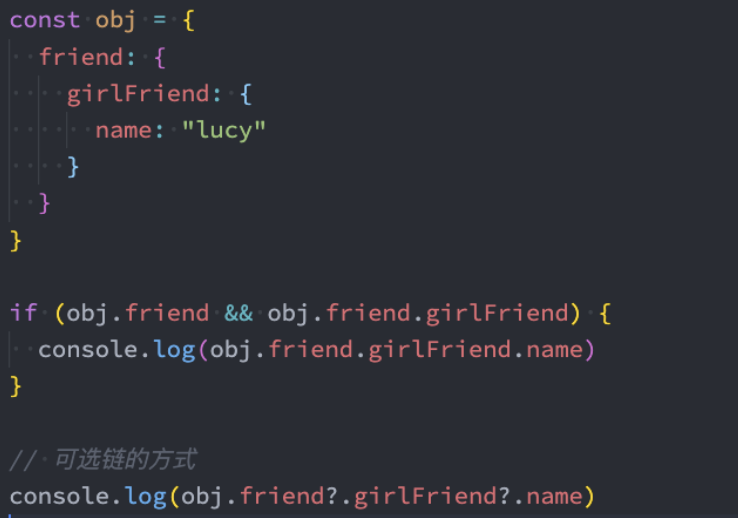
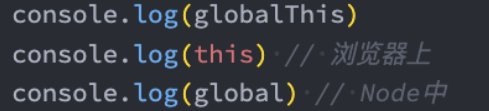
globalThis
在之前我们希望获取JavaScript环境的全局对象,不同的环境获取的方式是不一样的
比如在浏览器中可以通过this、window来获取;
比如在Node中我们需要通过global来获取;
在ES11中对获取全局对象进行了统一的规范:globalThis
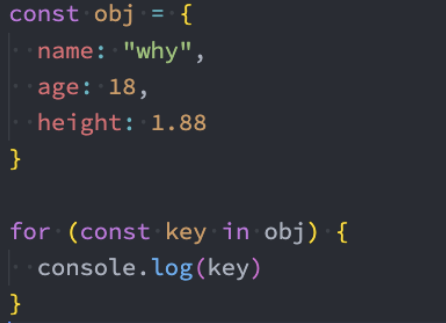
for..in标准化
在ES11之前,虽然很多浏览器支持for...in来遍历对象类型,但是并没有被ECMA标准化。
在ES11中,对其进行了ECMA标准化,for...in是用于遍历对象的key的:
ES11其他知识点
Dynamic Import:后续ES Module模块化中讲解。
Promise.allSettled:后续讲Promise的时候讲解。
import meta:后续ES Module模块化中讲解。
ES12
FinalizationRegistry
FinalizationRegistry 对象可以让你在对象被垃圾回收时请求一个回调。
FinalizationRegistry 提供了这样的一种方法:当一个在注册表中注册的对象被回收时,请求在某个时间点上调用一个清理回调。(清理回调有时被称为 finalizer );
你可以通过调用register方法,注册任何你想要清理回调的对象,传入该对象和所含的值;
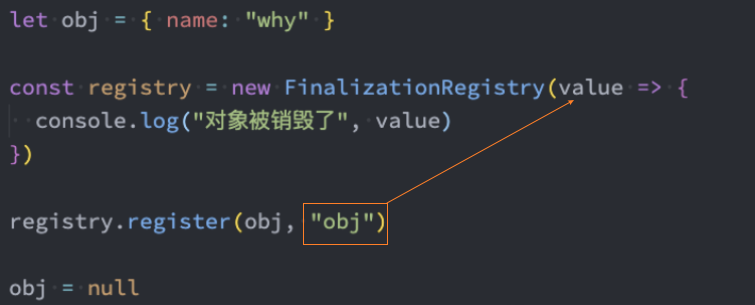
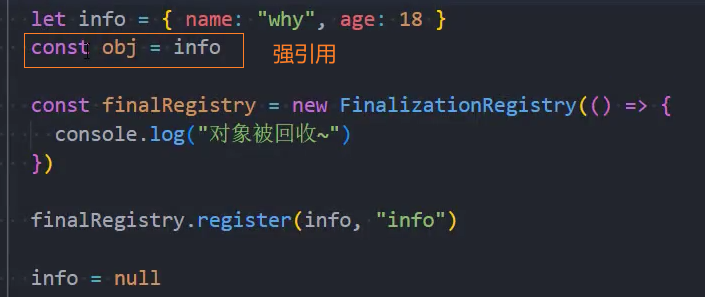
WeakRef
如果我们默认将一个对象赋值给另外一个引用,那么这个引用是一个强引用:
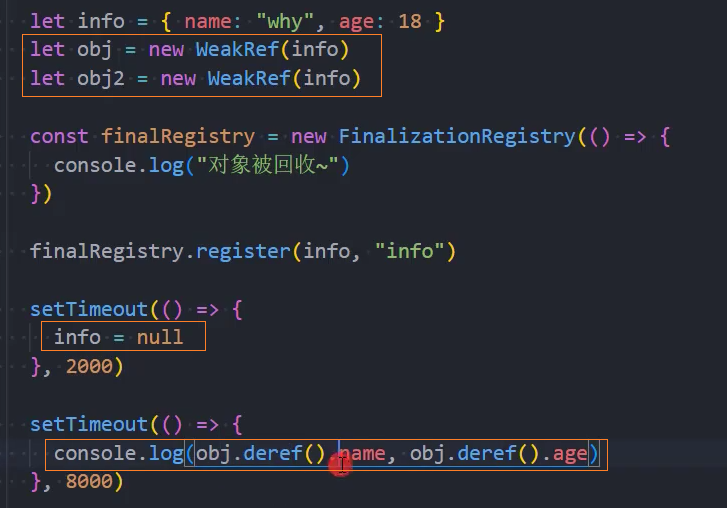
如果我们希望是一个弱引用的话,可以使用WeakRef;
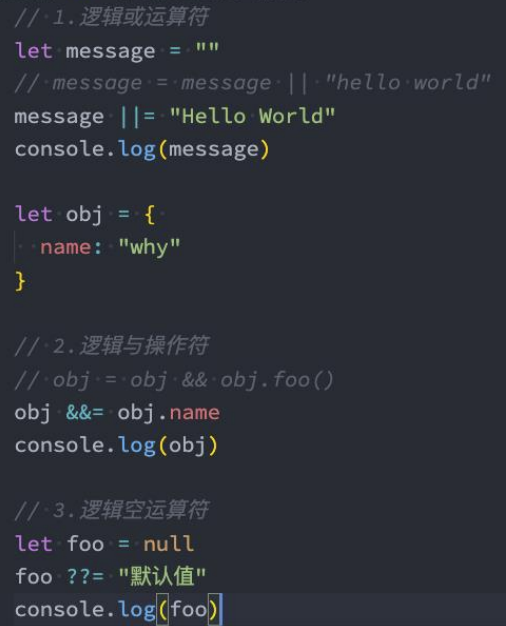
逻辑赋值运算符
x &&= y:逻辑与赋值。仅在x为真值时为其赋值x ||= y:逻辑或赋值。仅在x为假值时为其赋值x ??= y:逻辑空赋值。仅在x为*空值(null或undefined)*时为其赋值
ES12其他知识点
Numeric Separator:讲过了;
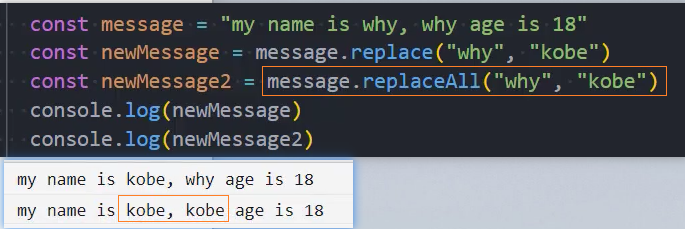
String.prototype.replaceAll:字符串替换;
ES13
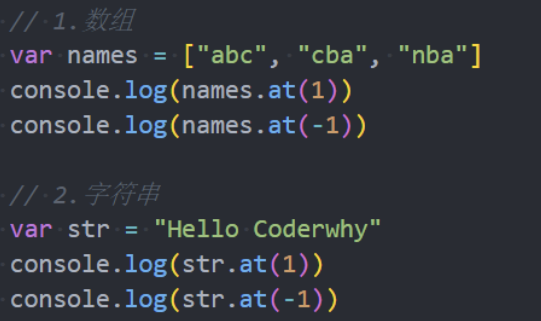
at()
前面我们有学过字符串、数组的at方法,它们是作为ES13中的新特性加入的:
Object.hasOwn()
Object中新增了一个静态方法(类方法): Object.hasOwn(obj, propKey)
- 该方法用于判断一个对象中是否有某个自己的属性;
Object.hasOwn和Object.prototype.hasOwnProperty的区别:

- 区别一:防止对象内部有重写hasOwnProperty
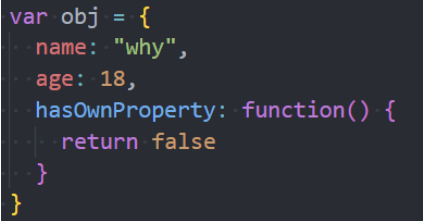
- 区别二:对于隐式原型指向null的对象, hasOwnProperty无法进行判断

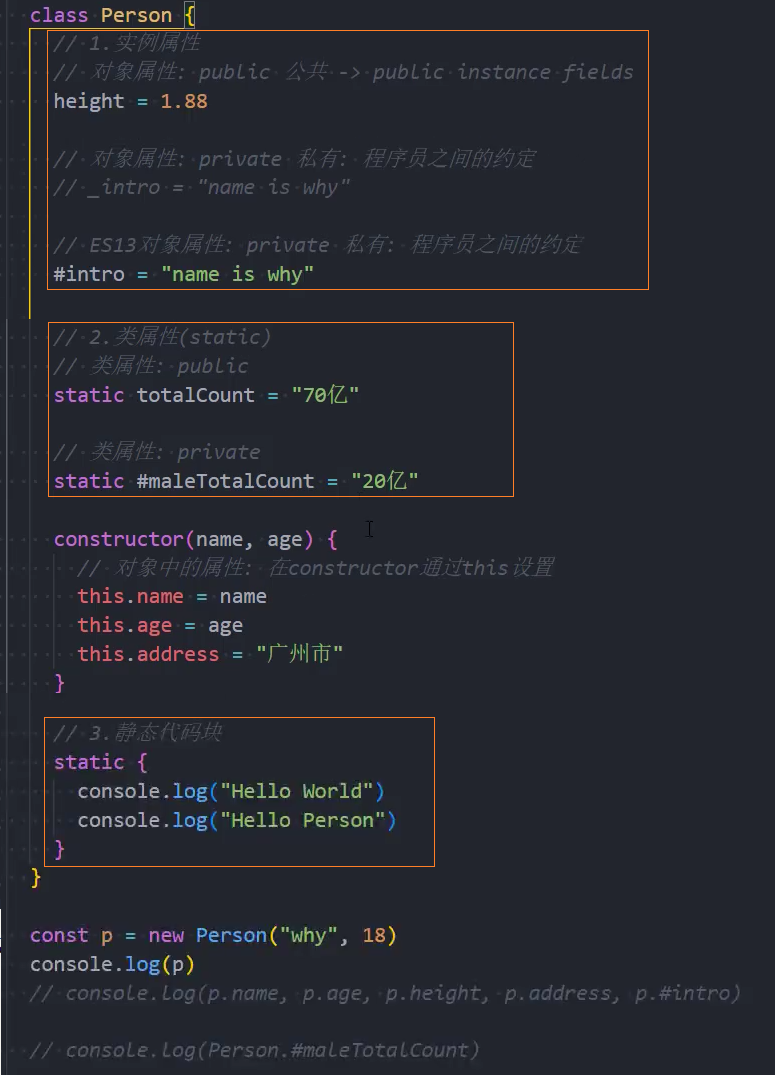
类中的新成员
在ES13中,新增了定义class类中成员字段(field)的其他方式:
- 实例属性:public / private
- 类属性(静态属性):public / private
- 静态代码块:先执行静态代码块,再执行构造方法
Proxy
监听对象属性的操作
需求: 有一个对象,我们希望监听这个对象中的属性被设置或获取的过程
- 通过我们前面所学的知识,能不能做到这一点呢?
思路: 我们可以通过之前的属性描述符中的存储属性描述符来做到;

上边这段代码就利用了前面讲过的 Object.defineProperty 的存储属性描述符来对属性的操作进行监听。
缺点:
但是这样做有什么缺点呢?
首先,Object.defineProperty的设计初衷,不是为了去监听截止一个对象中所有的属性的。
- 我们在定义某些属性的时候,初衷其实是定义普通的属性,但是后面我们强行将它变成了数据属性描述符。
其次,如果我们想监听更加丰富的操作,比如新增属性、删除属性,那么Object.defineProperty是无能为力的。
所以我们要知道,存储数据描述符设计的初衷并不是为了去监听一个完整的对象。
Proxy基本使用
在ES6中,新增了一个Proxy类,这个类从名字就可以看出来,是用于帮助我们创建一个代理的:
也就是说,如果我们希望监听一个对象的相关操作,那么我们可以先创建一个代理对象(Proxy对象);
之后对该对象的所有操作,都通过代理对象来完成,代理对象可以监听我们想要对原对象进行哪些操作;
我们可以将上面的案例用Proxy来实现一次:
首先,我们需要new Proxy对象,并且传入需要侦听的对象以及一个处理对象,可以称之为handler;
其次,我们之后的操作都是直接对Proxy的操作,而不是原有的对象,因为我们需要在handler里面进行侦听;
语法:
const p= new Proxy(target, handler)参数:
- target:
,要使用Proxy包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理) - handler:
,一个通常以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理p的行为
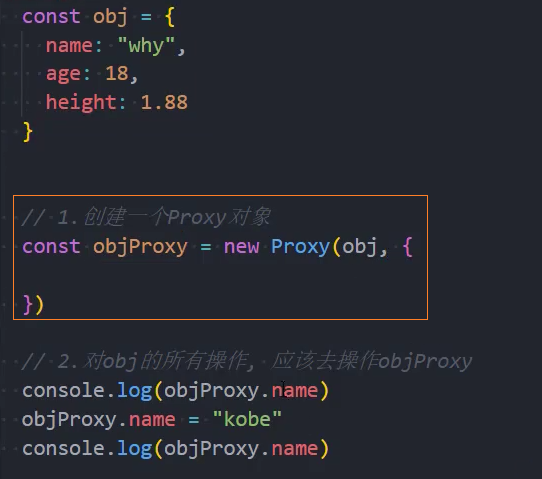
示例: 基本使用
Proxy的set和get捕获器
如果我们想要侦听某些具体的操作,那么就可以在handler中添加对应的捕获器(Trap):
set和get分别对应的是函数类型;
set函数有四个参数:
- target:目标对象(侦听的对象);
- property:将被设置的属性key;
- value:新属性值;
- receiver:调用的代理对象;
get函数有三个参数:
- target:目标对象(侦听的对象);
- property:被获取的属性key;
- receiver:调用的代理对象;
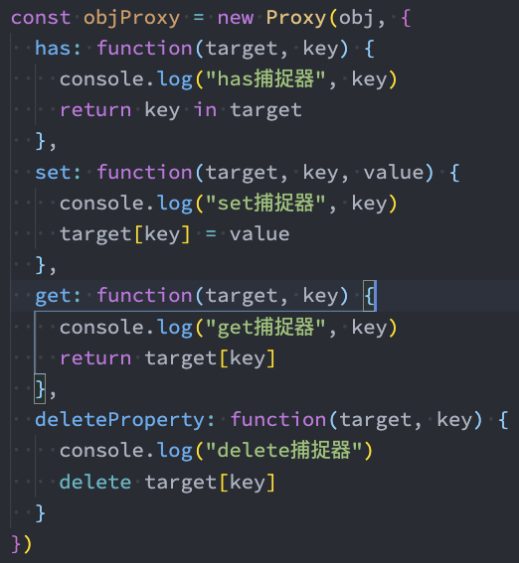
Proxy所有捕获器
13个捕获器分别是做什么的呢?
- 监听普通对象
- handler.get(target, prop, receiver?):
obj.name,获取属性值 - handler.set(target, prop, newValue, receiver?):
obj.name = 'mr',设置属性值 - handler.has(target, prop):
in, 判断是否存在某属性 - handler.defineProperty(target, prop, descriptor):
Object.defineProperty, 设置属性描述符 - handler.deleteProperty(target, prop):
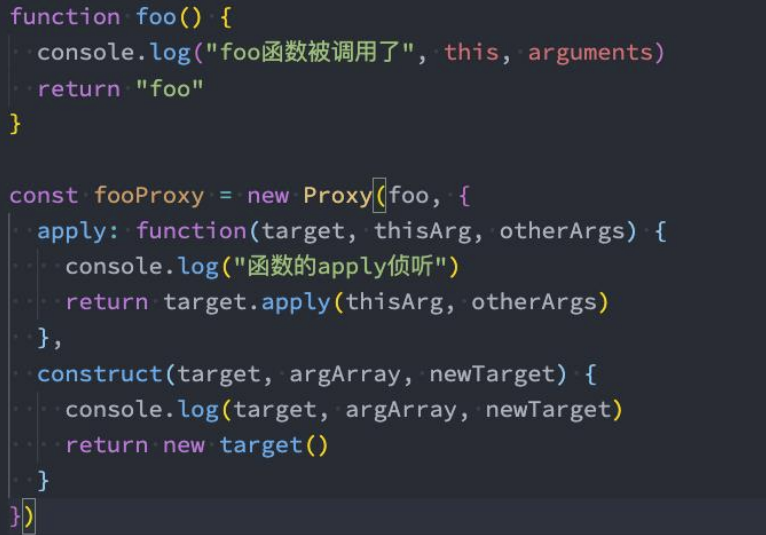
delete,删除属性 - 监听函数对象
- handler.apply(target, thisArg, args):
Object.prototype.apply,函数调用 - handler.construct(target, args, newTarget?):
new,调用构造函数 - handler.getPrototypeOf(target):
Object.getPrototypeOf, 获取对象的原型 - handler.setPrototypeOf(target, prototype):
Object.setPrototypeOf, 设置对象的原型 - handler.isExtensible(target):
Object.isExtensible, 判断是否可以新增属性 - handler.preventExtensions(target):
Object.preventExtensions, 阻止对象扩展 - handler.ownKeys(target):
Object.getOwnPropertyNames,Object.getOwnPropertySymbols,获取自身上的所有属性 - handler.getOwnPropertyDescriptor(target, prop):
Object.getOwnPropertyDescriptor, 获取自身上的属性描述符
示例:
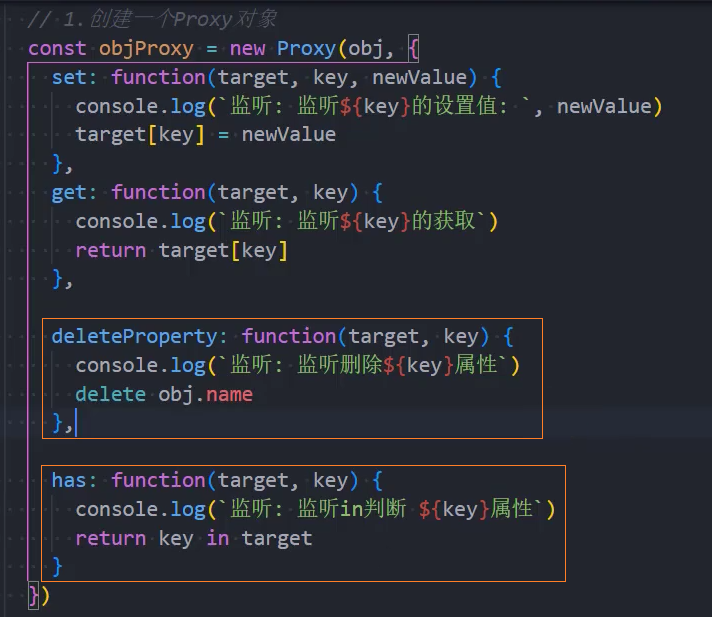
Proxy监听函数对象
当然,我们还会看到捕捉器中还有construct和apply,它们是应用于监听函数对象的:
Reflect
Reflect的作用
Reflect也是ES6新增的一个API,它是一个对象,字面的意思是反射。
作用:
那么这个Reflect有什么用呢?
它主要提供了很多操作JavaScript对象的方法,有点像Object中操作对象的方法;
比如Reflect.getPrototypeOf(target)类似于 Object.getPrototypeOf();
比如Reflect.defineProperty(target, propertyKey, attributes)类似于Object.defineProperty() ;
如果我们有Object可以做这些操作,那么为什么还需要有Reflect这样的新增对象呢?
这是因为在早期的ECMA规范中没有考虑到这种对 对象本身 的操作如何设计会更加规范,所以将这些API放到了Object上面;
但是Object作为一个构造函数,这些操作实际上放到它身上并不合适;
另外还包含一些类似于 in、delete操作符,让JS看起来是会有一些奇怪的;
所以在ES6中新增了Reflect,让我们这些操作都集中到了Reflect对象上;
另外在使用Proxy时,可以做到不操作原对象;
那么Object和Reflect对象之间的API关系,可以参考MDN文档:
Reflect的常见方法
Reflect中有哪些常见的方法呢?它和Proxy是一一对应的,也是13个:
- 监听普通对象
- Reflect.get(target, prop, receiver?):
obj.name,获取属性值 - Reflect.set(target, prop, newValue, receiver?):
obj.name = 'mr',设置属性值 - Reflect.has(target, prop):
in, 判断是否存在某属性 - Reflect.defineProperty(target, prop, descriptor):
Object.defineProperty, 设置属性描述符 - Reflect.deleteProperty(target, prop):
delete,删除属性 - 监听函数对象
- Reflect.apply(target, thisArg, args):
Object.prototype.apply,函数调用 - Reflect.construct(target, args, newTarget?):
new,调用构造函数 - Reflect.getPrototypeOf(target):
Object.getPrototypeOf, 获取对象的原型 - Reflect.setPrototypeOf(target, prototype):
Object.setPrototypeOf, 设置对象的原型 - Reflect.isExtensible(target):
Object.isExtensible, 判断是否可以新增属性 - Reflect.preventExtensions(target):
Object.preventExtensions, 阻止对象扩展 - Reflect.ownKeys(target):
Object.getOwnPropertyNames,Object.getOwnPropertySymbols,获取自身上的所有属性 - Reflect.getOwnPropertyDescriptor(target, prop):
Object.getOwnPropertyDescriptor, 获取自身上的属性描述符
Reflect的使用
那么我们可以将之前Proxy案例中对原对象的操作,都修改为Reflect来操作:

优点: 使用Reflect结合Proxy代理对象的优点
- 优点一:代理对象的目的:实现不再直接操作原对象
- 优点二:Reflect.set方法有返回布尔值,可以判断本次操作是否成功
- 优点三:receiver就是外层Proxy对象。Reflect.set/get的最后一个参数receiver可以决定对象访问器settter/getter的this指向
Receiver的作用
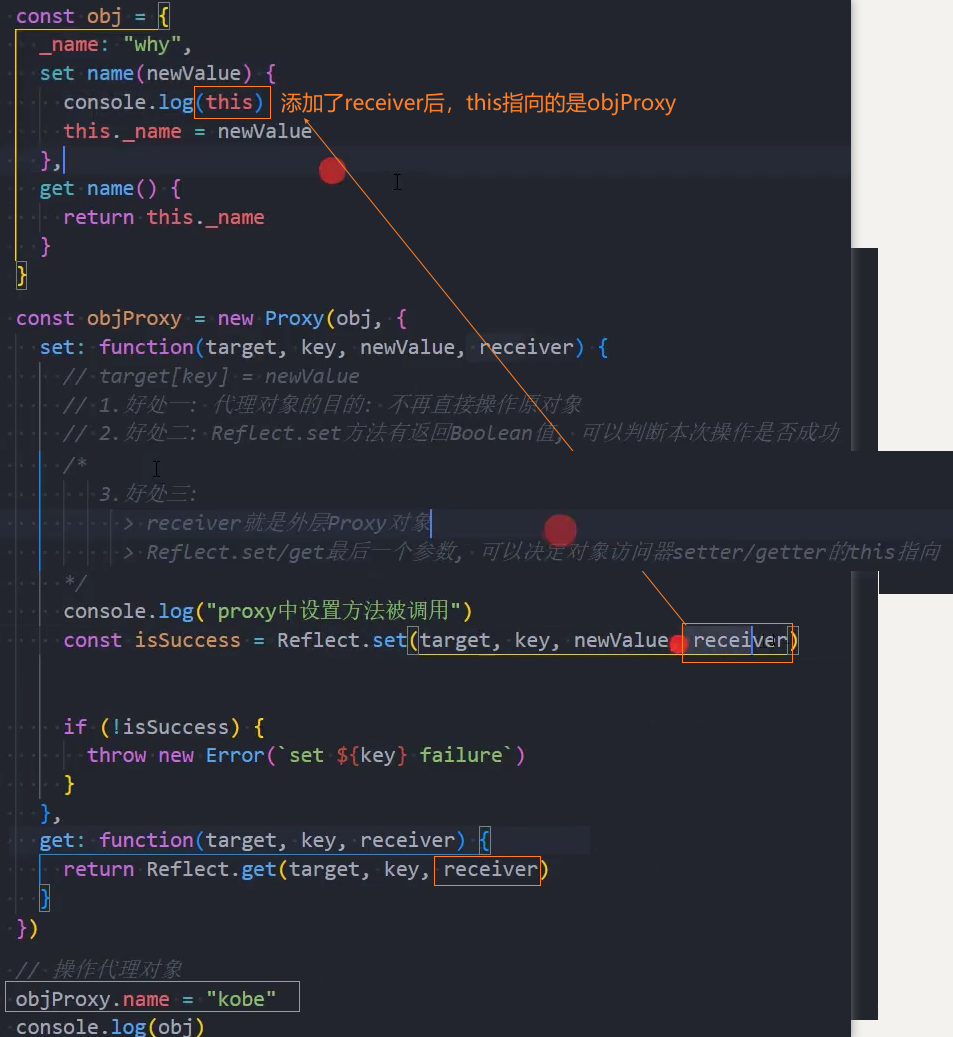
我们发现在使用getter、setter的时候有一个receiver的参数,它的作用是什么呢?
- 如果我们的源对象(obj)有setter、getter的访问器属性,那么可以通过receiver来改变里面的this;
我们来看这样的一个对象:

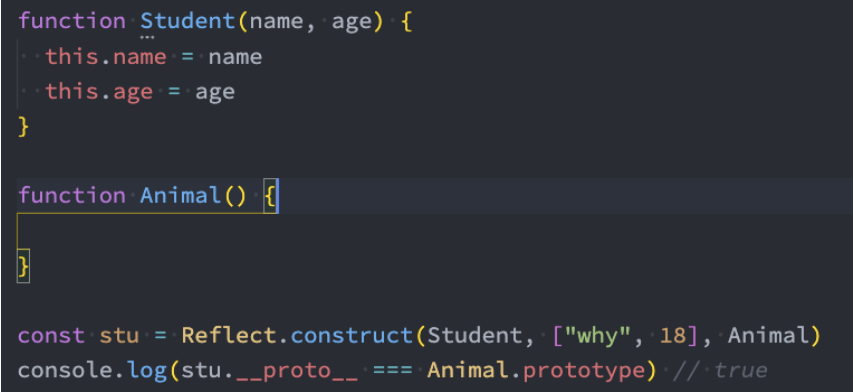
Reflect的construct
Promise
异步任务的处理
在ES6出来之后,有很多关于Promise的讲解、文章,也有很多经典的书籍讲解Promise
虽然等你学会Promise之后,会觉得Promise不过如此;
但是在初次接触的时候都会觉得这个东西不好理解;
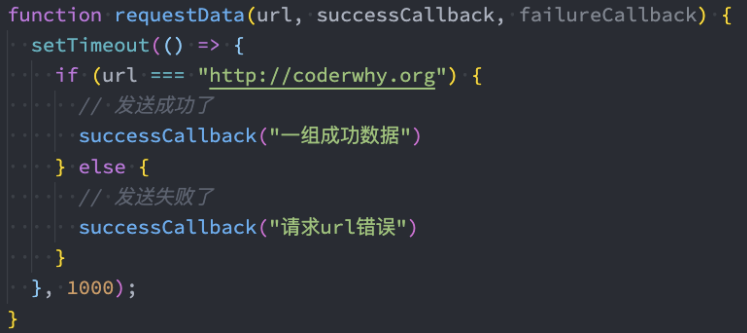
那么这里我从一个实际的例子来作为切入点:
我们调用一个函数,这个函数中发送网络请求(我们可以用定时器来模拟);
如果发送网络请求成功了,那么告知调用者发送成功,并且将相关数据返回过去;
如果发送网络请求失败了,那么告知调用者发送失败,并且告知错误信息;
什么是Promise
在上面的解决方案中,我们确确实实可以解决请求函数得到结果之后,获取到对应的回调,但是它存在两个主要的问题:
第一,我们需要自己来设计回调函数、回调函数的名称、回调函数的使用等;
第二,对于不同的人、不同的框架设计出来的方案是不同的,那么我们必须耐心去看别人的源码或者文档,以便可以理解它这个函数到底怎么用;
我们来看一下Promise的API是怎么样的:
Promise是一个类,可以翻译成 承诺、许诺 、期约;
当我们需要的时候,给予调用者一个承诺:待会儿我会给你回调数据时,就可以创建一个Promise的对象;
在通过new创建Promise对象时,我们需要传入一个回调函数,我们称之为executor
- 这个回调函数会被立即执行,并且给它传入另外两个回调函数resolve、reject;
- 当我们调用resolve回调函数时,会执行Promise对象的then方法传入的回调函数;
- 当我们调用reject回调函数时,会执行Promise对象的catch方法传入的回调函数;
语法
1、定义
const p = new Promise(executor)
cosnt p = new Promise((resolve, reject) => {
if(成功) {
// 调用resolve,then传入的回调会被执行
resolve('成功结果')
} else {
// 调用reject,catch传入的回调会被执行
reject('错误信息')
}
})2、使用
new Promise(executor).then(onResoledCallback, onRejectedCallback)
new Promise(executor).then((res) => {
console.log('成功:', res)
},(err) => {
console.log('失败:', err)
})
new Promise(executor)
.then(onResoledCallback)
.catch(onRejectedCallback)
new Promise(executor)
.then(onResoledCallback)
.catch(onRejectedCallback)
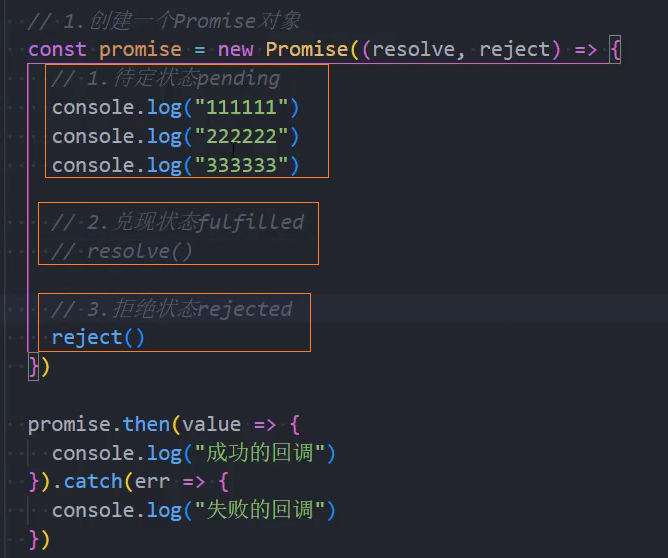
.finally(onFinallyCallback)Promise三种状态
上面Promise使用过程,我们可以将它划分成三个状态:
待定(pending): 初始状态,既没有被兑现,也没有被拒绝;
- 当执行executor中的代码时,处于该状态;
已兑现(fulfilled): 意味着操作成功完成;
- 执行了resolve时,处于该状态,Promise已经被兑现;
已拒绝(rejected): 意味着操作失败;
- 执行了reject时,处于该状态,Promise已经被拒绝;
注意: Promise的状态一旦被确定下来,就不能再执行某个回调函数更改状态
通过Promise重构之前的异步请求
那么有了Promise,我们就可以将之前的代码进行重构了:
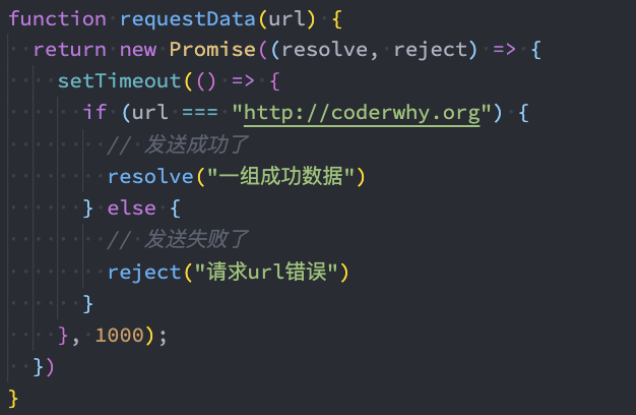
executor
executor是在创建Promise时需要传入的一个回调函数,这个回调函数会被立即执行,并且传入两个参数:
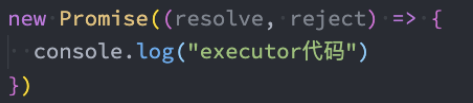
通常我们会在Executor中确定我们的Promise状态:
通过resolve,可以兑现(fulfilled)Promise的状态,我们也可以称之为已决议(resolved);
通过reject,可以拒绝(rejected)Promise的状态;
这里需要注意:一旦状态被确定下来,Promise的状态会被锁死,该Promise的状态是不可更改的
在我们调用resolve的时候,如果resolve传入的值本身不是一个Promise,那么会将该Promise的状态变成兑现(fulfilled);
在之后我们去调用reject时,已经不会有任何的响应了(并不是这行代码不会执行,而是无法改变Promise状态);
resolve参数类型
resolve不同参数值的区别:
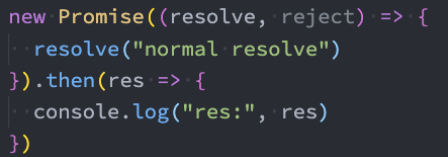
情况一:如果resolve传入一个普通的值或者对象,那么这个值会作为then回调的参数;
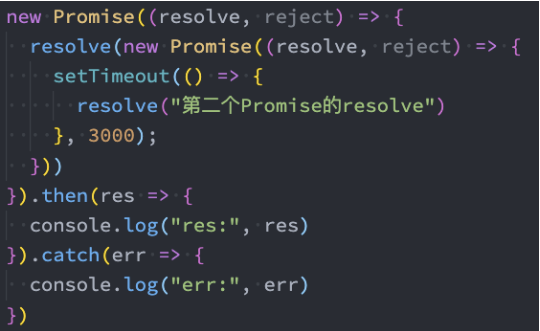
情况二:如果resolve中传入的是另外一个Promise,那么这个新Promise会决定原Promise的状态:
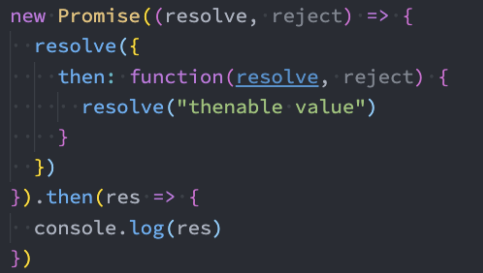
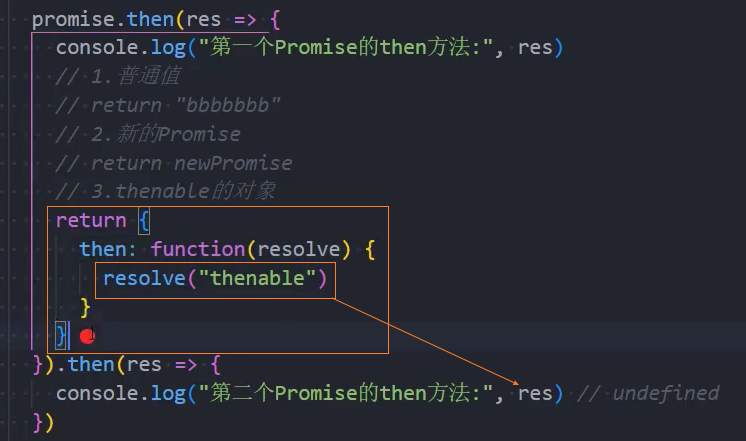
情况三:如果resolve中传入的是一个thenable对象,这个对象有实现then方法,那么会执行该then方法,并且根据then方法的结果来决定Promise的状态:
实例方法-then()
参数
then方法是Promise对象上的一个实例方法:
- 它其实是放在Promise的原型上的 Promise.prototype.then
then方法接受两个参数:
fulfilled的回调函数:当状态变成fulfilled时会回调的函数;
reject的回调函数:当状态变成reject时会回调的函数;

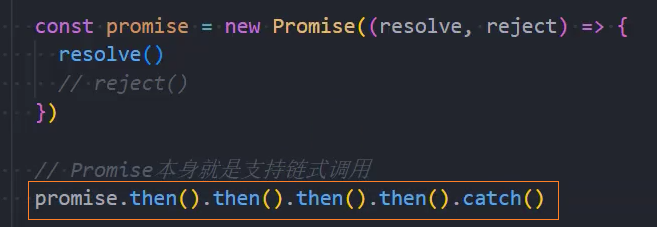
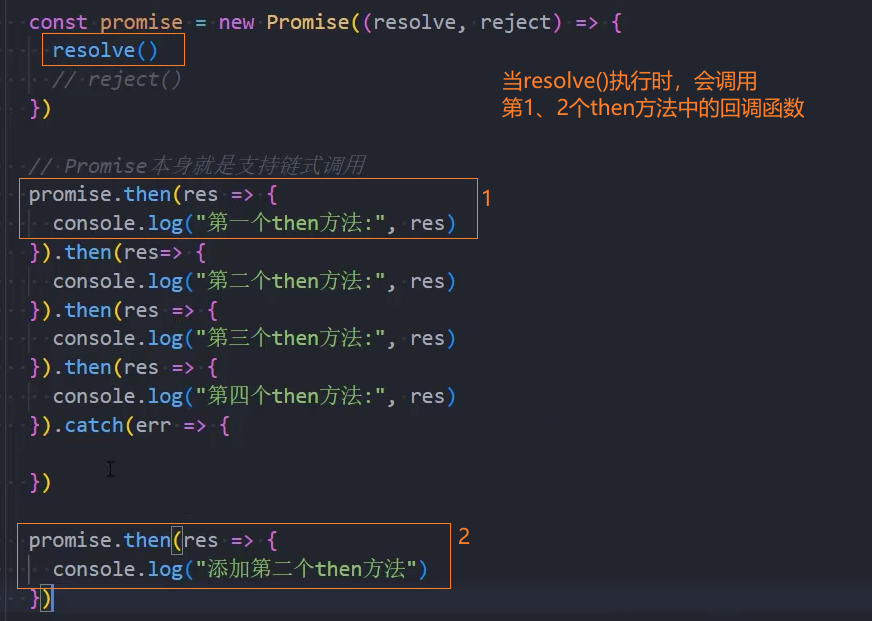
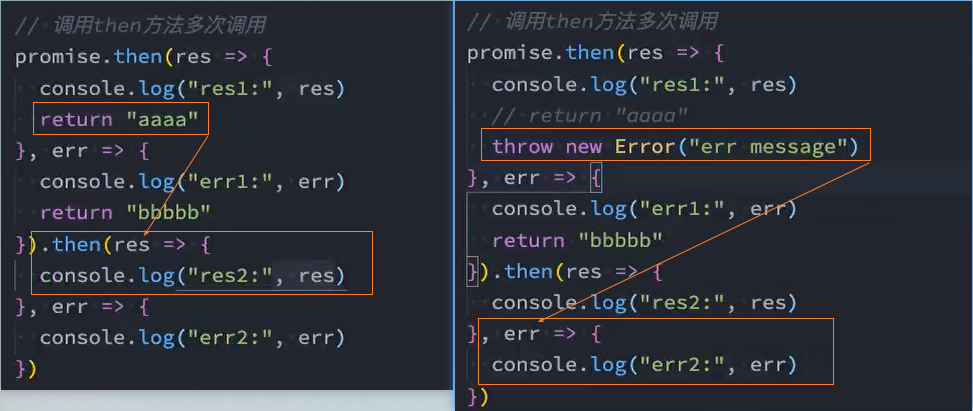
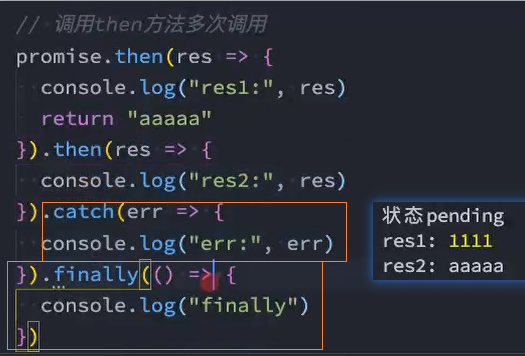
多次调用
一个Promise的then方法是可以被多次调用的:
每次调用我们都可以传入对应的fulfilled回调;
当Promise的状态变成fulfilled的时候,这些回调函数都会被执行;

返回值
then方法本身是有返回值的,它的返回值是一个Promise,所以我们可以进行如下的链式调用:
但是then方法返回的Promise到底处于什么样的状态呢?
Promise有三种状态,那么这个Promise处于什么状态呢?
当then方法中的回调函数本身在执行的时候,那么它处于pending状态;
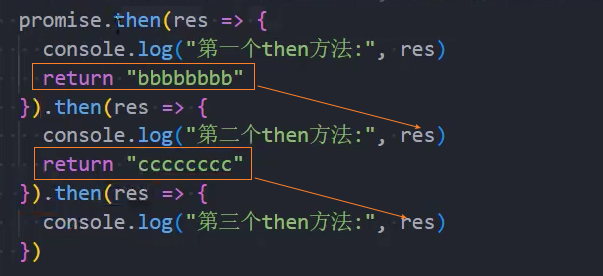
当then方法中的回调函数返回一个结果时
情况一:返回一个普通的值,那么它处于fulfilled状态,并且会将结果作为resolve的参数;
情况二:返回一个Promise,由新的Promise的状态决定
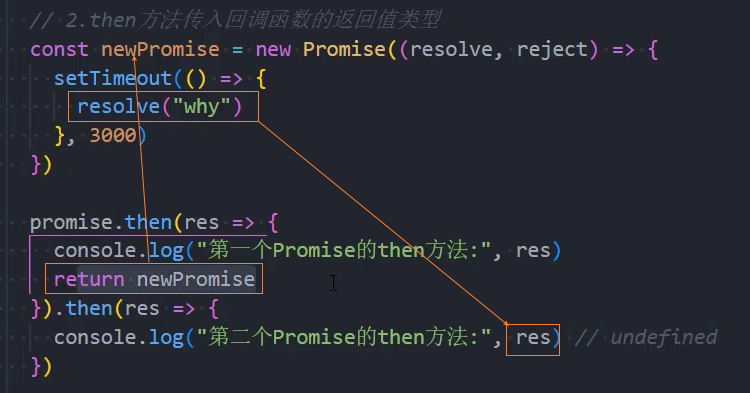
情况三:返回一个thenable值;
当then方法抛出一个异常时,那么它处于reject状态;
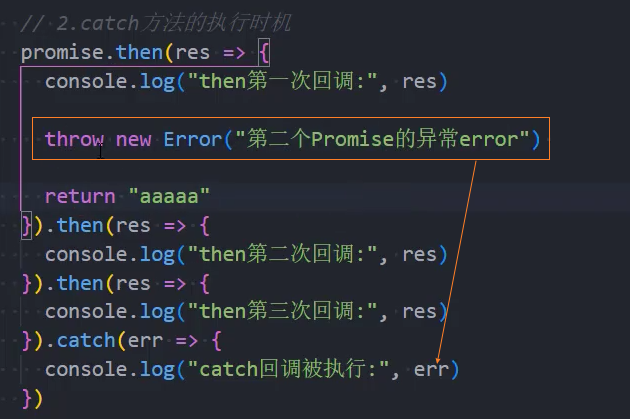
实例方法-catch()
多次调用
catch方法也是Promise对象上的一个实例方法:
- 它也是放在Promise的原型上的 Promise.prototype.catch
一个Promise的catch方法是可以被多次调用的:
每次调用我们都可以传入对应的reject回调;
当Promise的状态变成reject的时候,这些回调函数都会被执行;
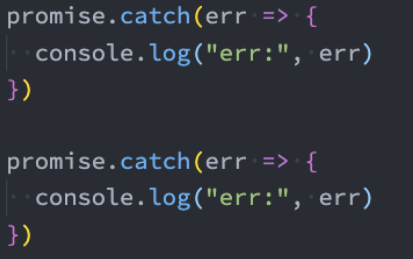
返回值
事实上catch方法也是会返回一个Promise对象的,所以catch方法后面我们可以继续调用then方法或者catch方法:
下面的代码,后续是catch中的err2打印,还是then中的res打印呢?
答案是res打印,这是因为catch传入的回调在执行完后,默认状态依然会是fulfilled的;
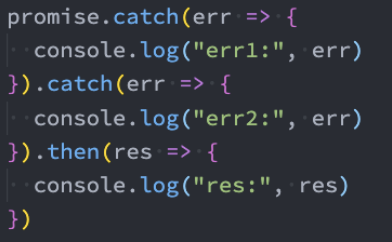
那么如果我们希望后续继续执行catch,那么需要抛出一个异常:
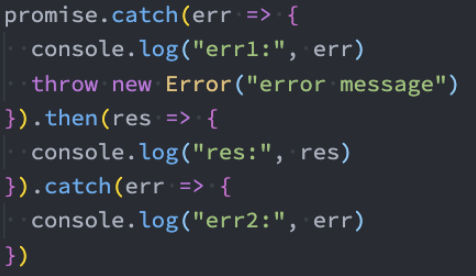
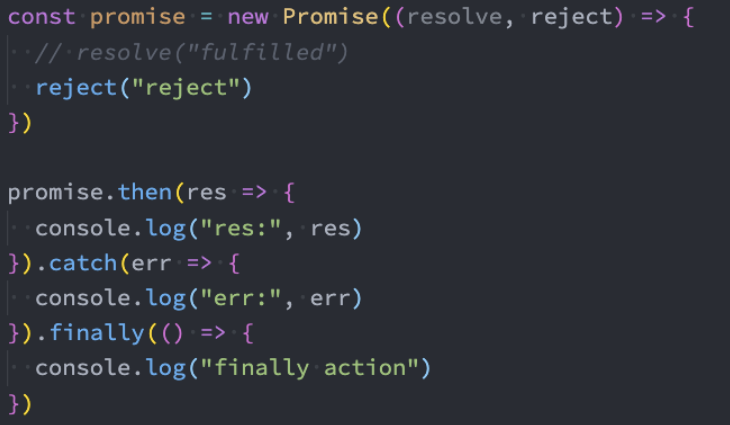
实例方法-finally()
finally是在ES9(ES2018)中新增的一个特性:表示Promise对象无论变成fulfilled还是rejected状态,最终都会被执行的代码。
finally方法的回调是不接收参数的,因为无论前面是fulfilled状态,还是rejected状态,它都会执行。
类方法-resolve
前面我们学习的then、catch、finally方法都属于Promise的实例方法,都是存放在Promise的prototype上的。
- 下面我们再来学习一下Promise的类方法。
有时候我们已经有一个现成的内容,希望将其转成Promise来使用,这个时候我们可以使用 Promise.resolve 方法来完成。
- Promise.resolve的用法相当于new Promise,并且执行resolve操作:

resolve参数的形态:
情况一:参数是一个普通的值或者对象
情况二:参数本身是Promise
情况三:参数是一个thenable
类方法-reject
reject方法类似于resolve方法,只是会将Promise对象的状态设置为reject状态。
Promise.reject的用法相当于new Promise,只是会调用reject:

Promise.reject传入的参数无论是什么形态,都会直接作为reject状态的参数传递到catch的。
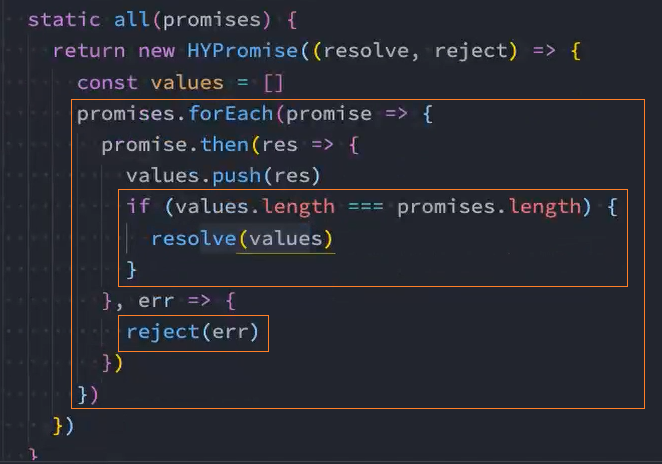
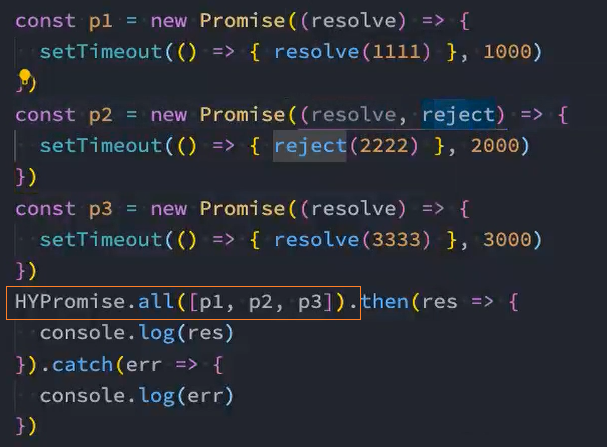
类方法-all
另外一个类方法是Promise.all:
它的作用是将多个Promise包裹在一起形成一个新的Promise;
新的Promise状态由包裹的所有Promise共同决定:
- 当所有的Promise状态变成fulfilled状态时,新的Promise状态为fulfilled,并且会将所有Promise的返回值组成一个数组;
- 当有一个Promise状态为reject时,新的Promise状态为reject,并且会将第一个reject的返回值作为参数;
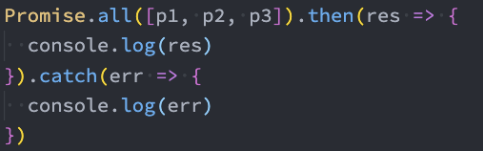
应用: 发送网络请求时,当同时发送多个网络请求后,想等所有请求都有结果再一起返回,可以使用Promise.all
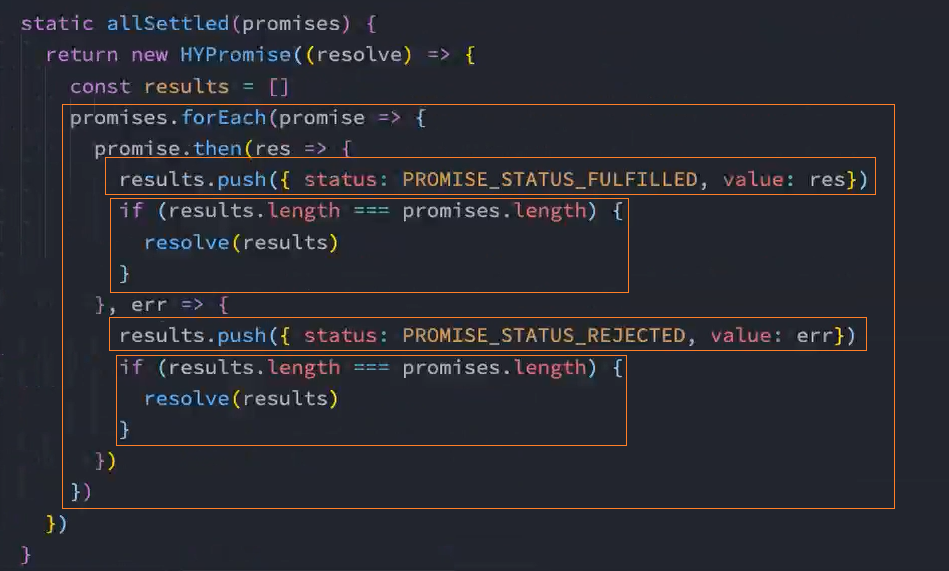
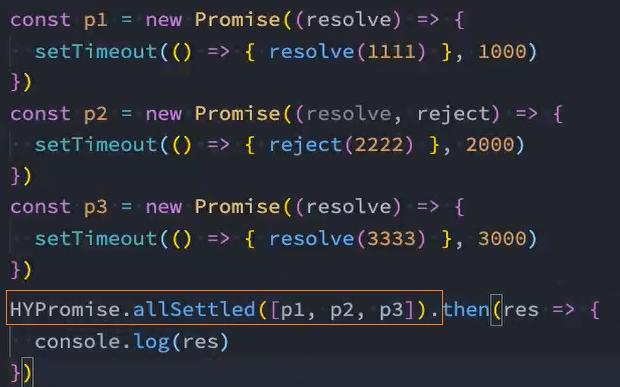
类方法-allSettled
all方法有一个缺陷:当有其中一个Promise变成reject状态时,新Promise就会立即变成对应的reject状态。
- 那么对于resolved的,以及依然处于pending状态的Promise,我们是获取不到对应的结果的;
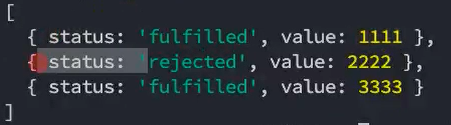
在ES11(ES2020)中,添加了新的API Promise.allSettled:
该方法会在所有的Promise都有结果(settled),无论是fulfilled,还是rejected时,才会有最终的状态;
并且这个Promise的结果一定是fulfilled状态的;
我们来看一下打印的结果:
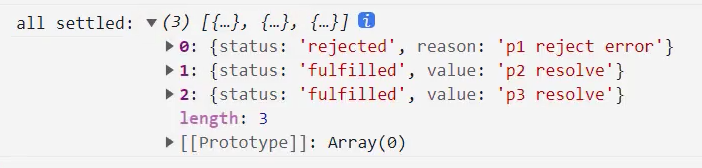
allSettled的结果是一个数组,数组中存放着每一个Promise的结果,并且是对应一个对象的;
这个对象中包含status状态,以及对应的value值;
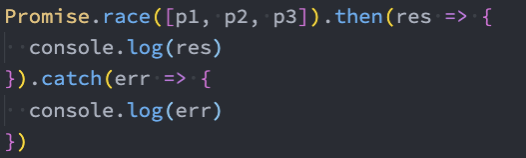
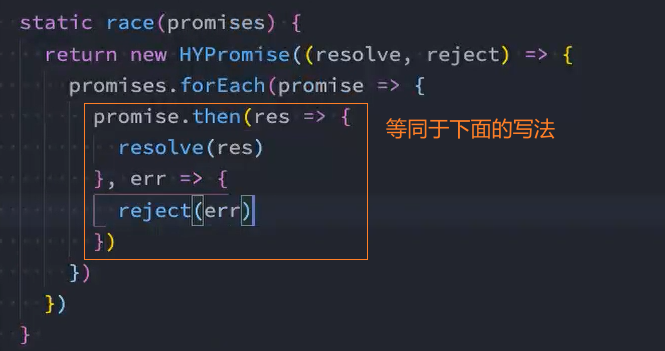
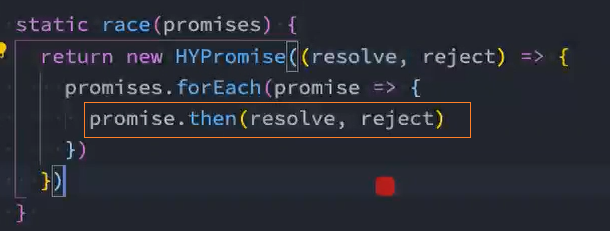
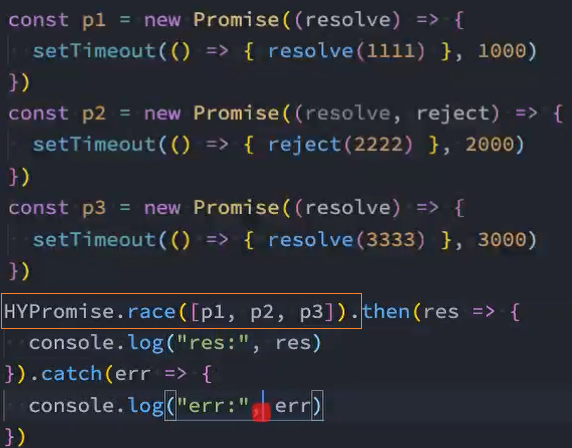
类方法-race
如果有一个Promise有了结果,我们就希望决定最终新Promise的状态,那么可以使用race方法:
- race是竞技、竞赛的意思,表示多个Promise相互竞争,谁先有结果,那么就使用谁的结果,无论结果是fulfilled还是rejected;
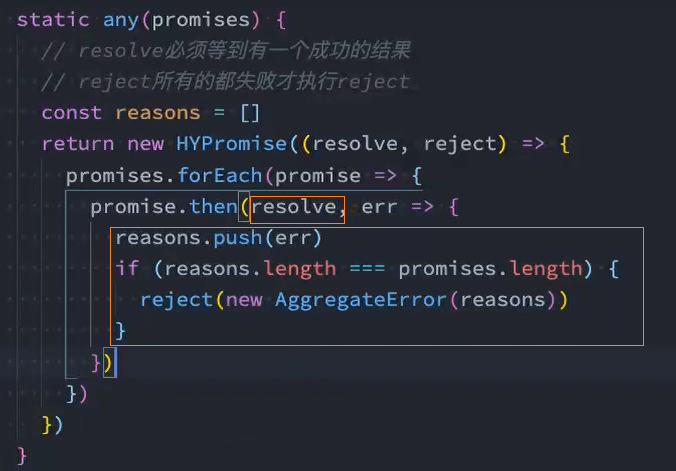
类方法-any
any方法是ES12中新增的方法,和race方法是类似的:
any方法会等到一个fulfilled状态,才会决定新Promise的状态;
如果所有的Promise都是reject的,那么也会等到所有的Promise都变成rejected状态;
如果所有的Promise都是reject的,那么会报一个AggregateError错误。
手写-Promise
Promise结构设计
Promses/A+ 规范: https://promisesaplus.com/
Promise三种状态
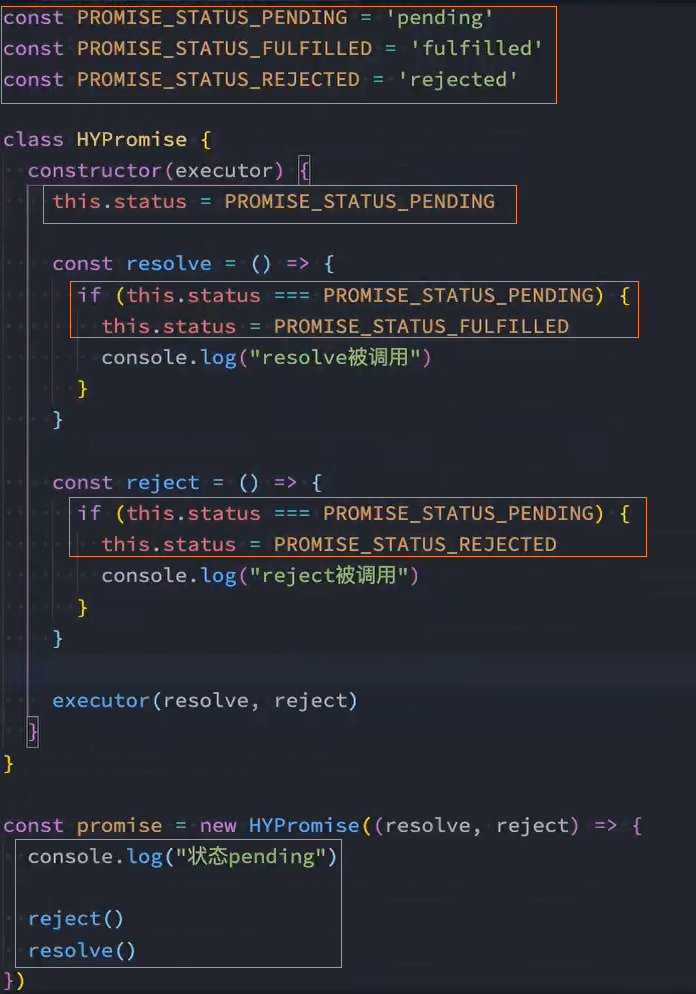
调用回调函数时传递参数
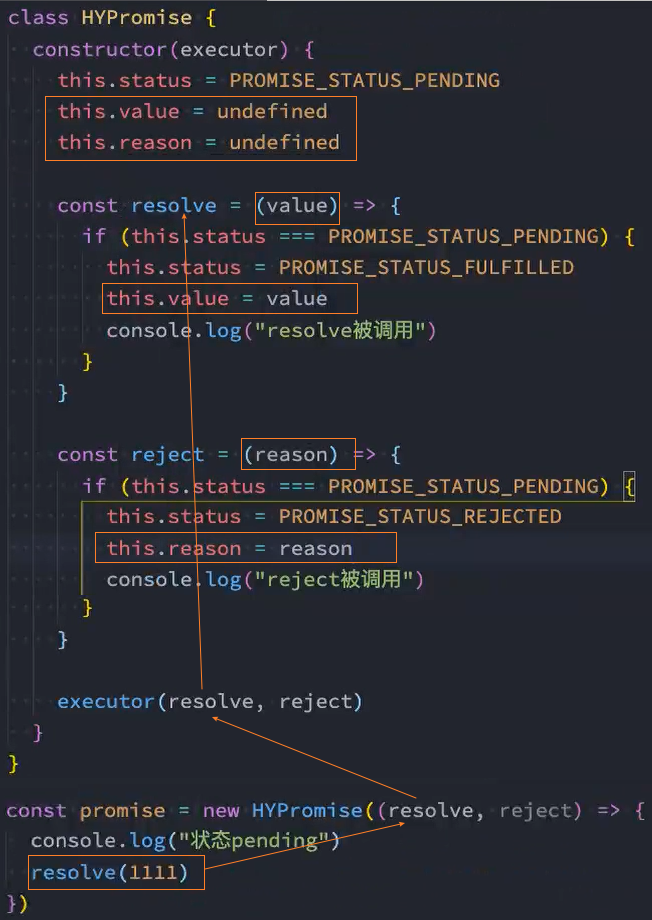
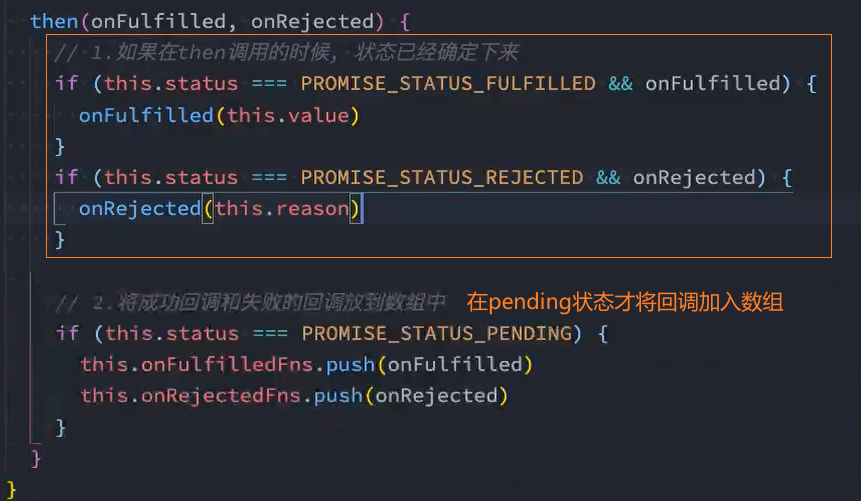
实例方法-then
1、基本实现
2、实现:同一个promise多次调用then方法
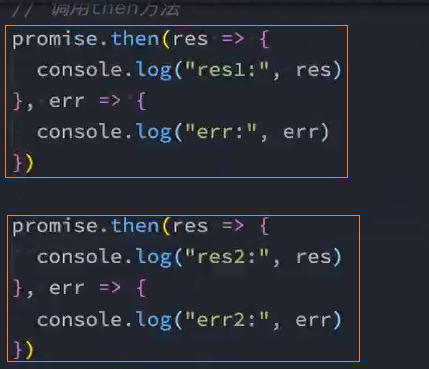
思路: 将需要多次调用的成功回调和失败回调分别放入一个数组中,调用时再遍历该数组,分别调用数组中的回调方法
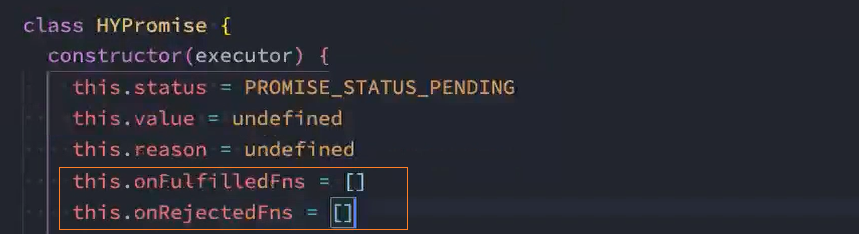
2.1、定义2个数组,将then中的成功、失败回调分别push到这2个数组中
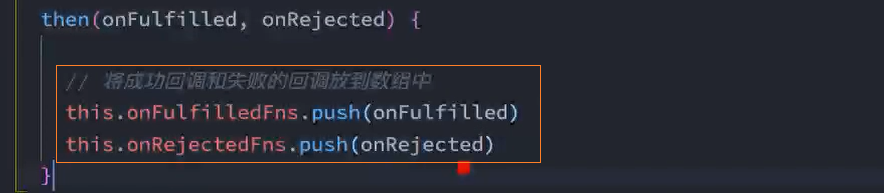
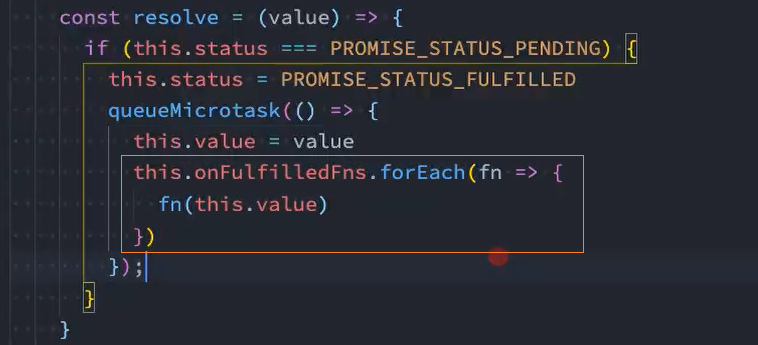
2.2、遍历这2个数组,再分别调用数组中的回调方法
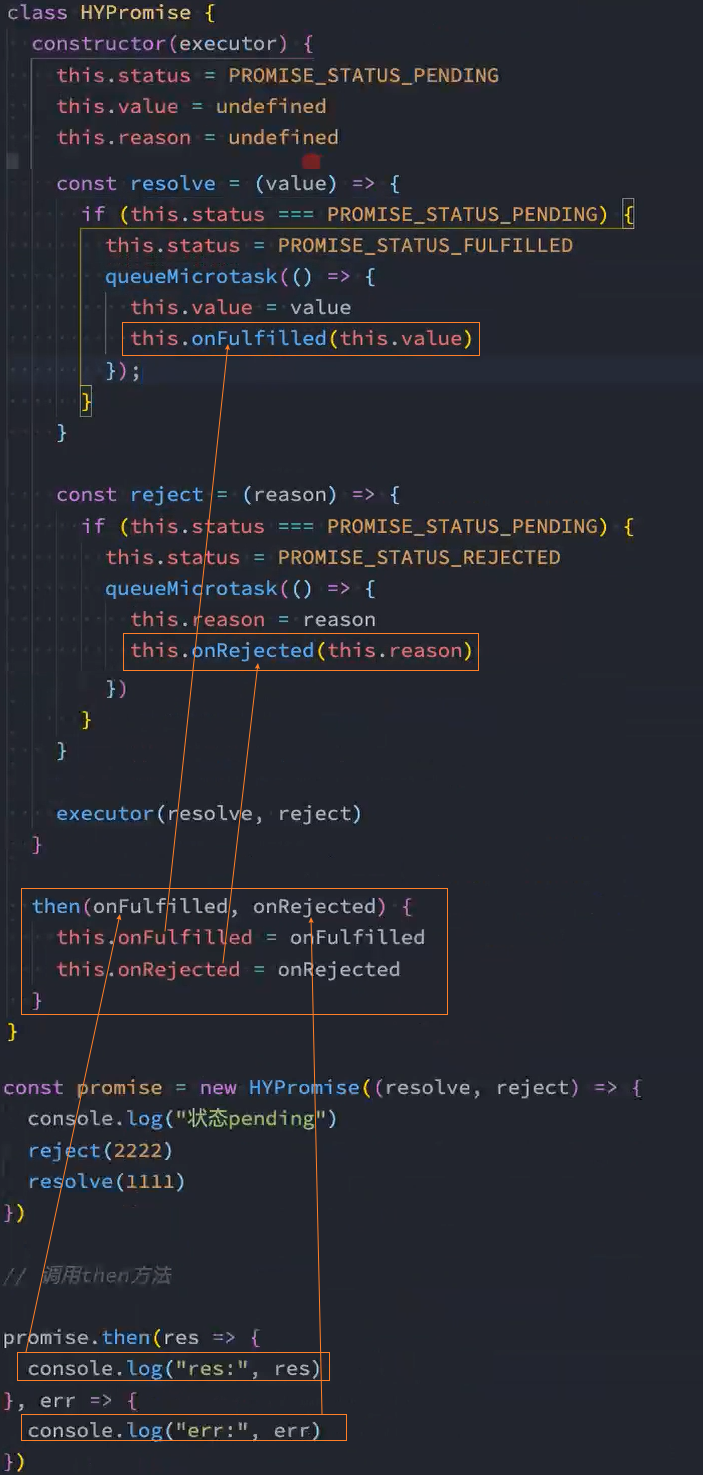
3、实现:异步延时调用then方法
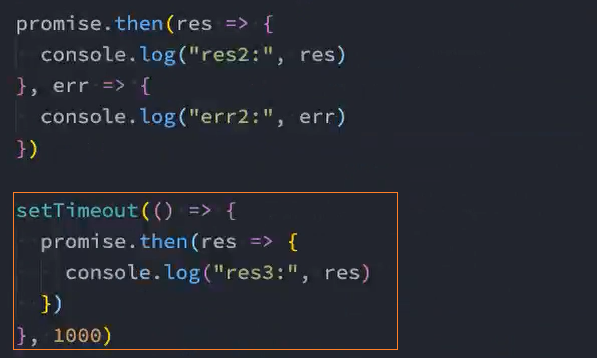
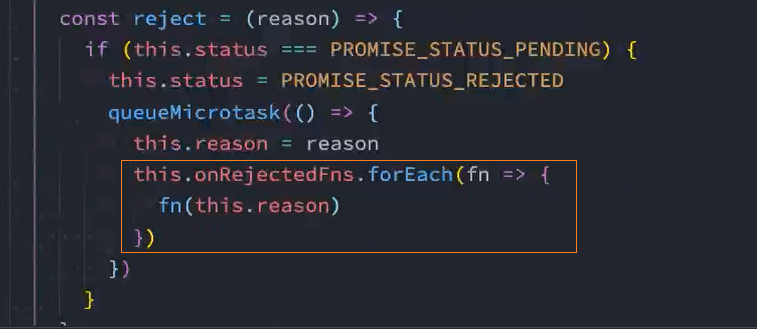
将状态status放入微队列queueMicrotask中
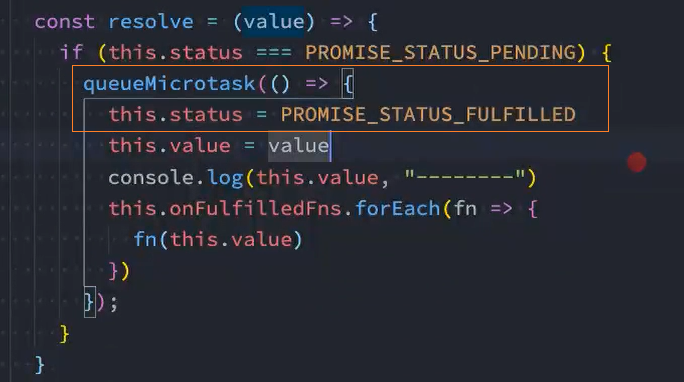
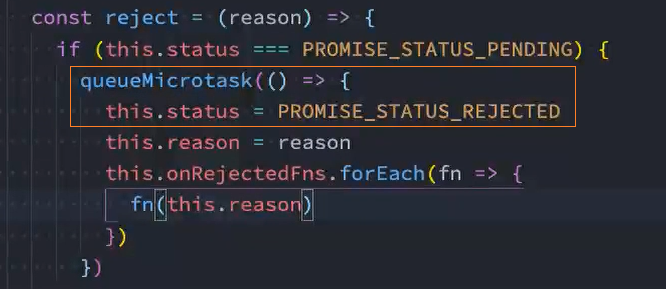
问题: 将状态status放入微队列queueMicrotask中后,resolve和reject都会执行,加入微任务队列
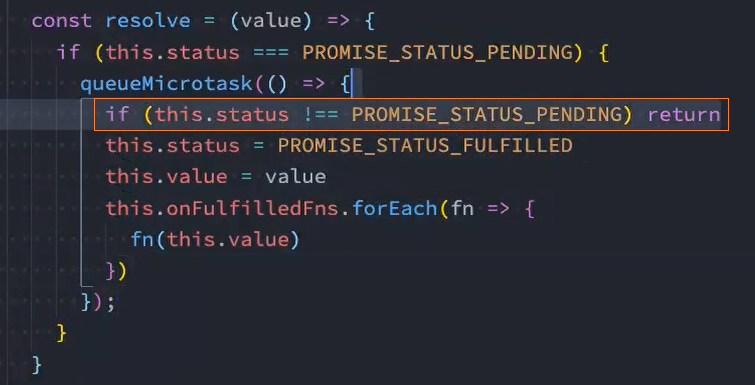
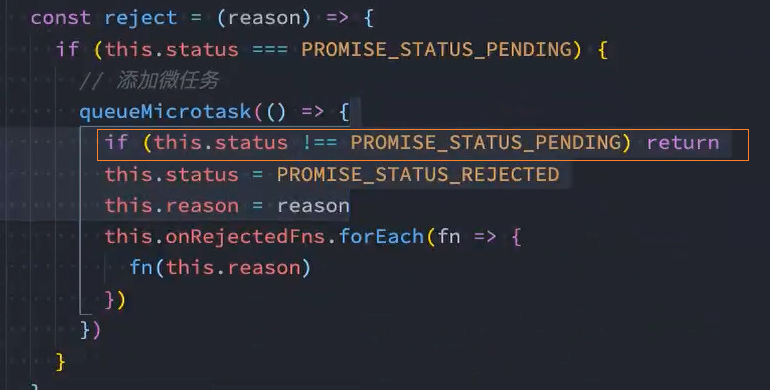
解决: 在加入微任务前判断当前状态是否为pending,如果不是pending则表示已经执行了某个回调,就不能加入微任务
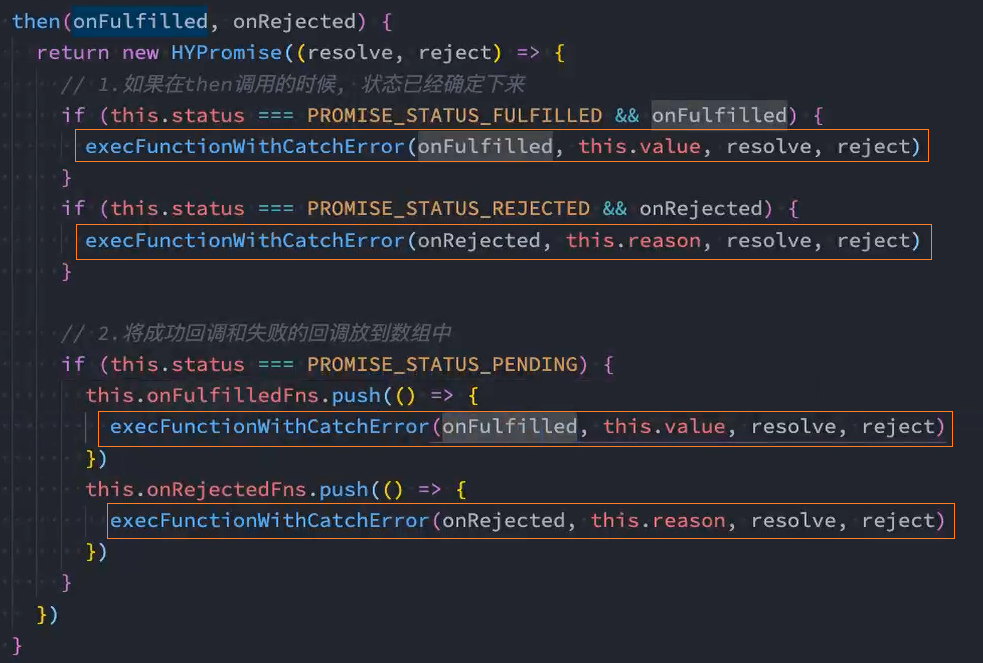
4、实现:then方法的链式调用
思路:
- 当前then方法没有返回值,所以默认会返回undefined,不能通过undefined.then()链式调用方法。
- 通过then方法中返回一个新的Promise,可以实现链式调用then方法
- 新Promise中resolve(res)或reject(err)的参数res或err必须是上一次then中回调返回的结果
问题: 在new Promise中抛出异常的情况
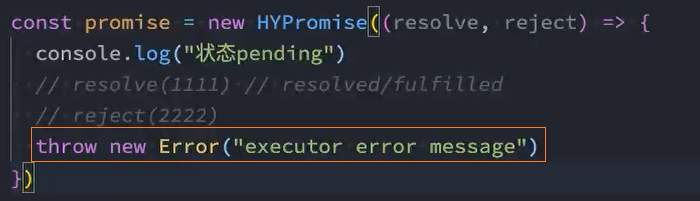
解决:
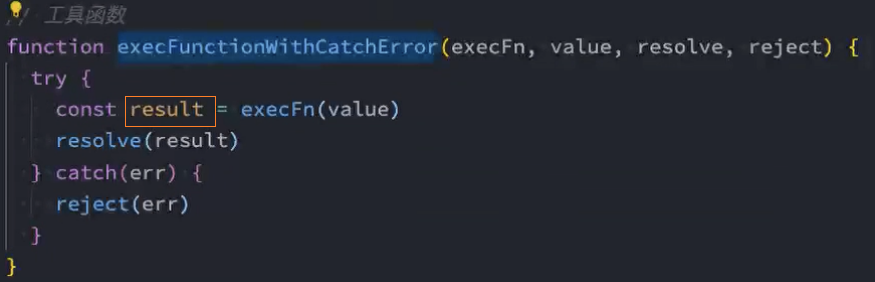
5、封装:try...catch中相似的代码
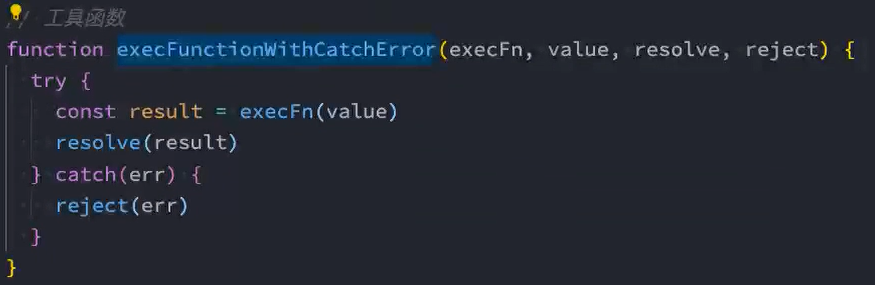
6、实现:then函数的回调函数参数为可选参数
7、实现:判断上次then执行结果的值:普通值、promise、thenable
实例方法-catch
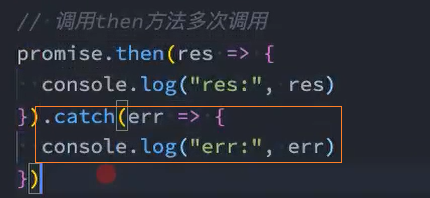
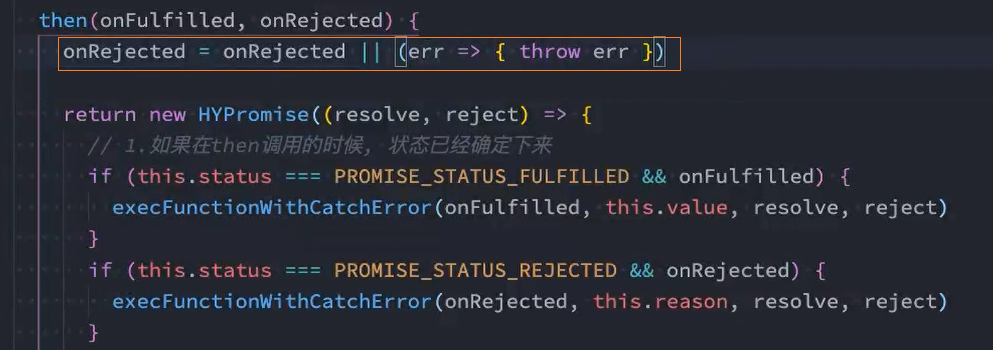
*思路:*通过调用then方法时只传递reject回调实现catch
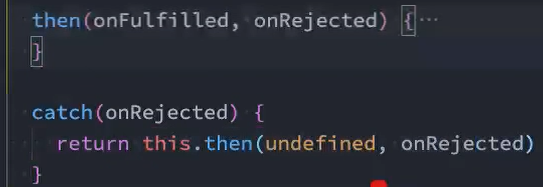
问题: 在回调函数有值(存在)的情况下,才去执行函数或添加到数组中
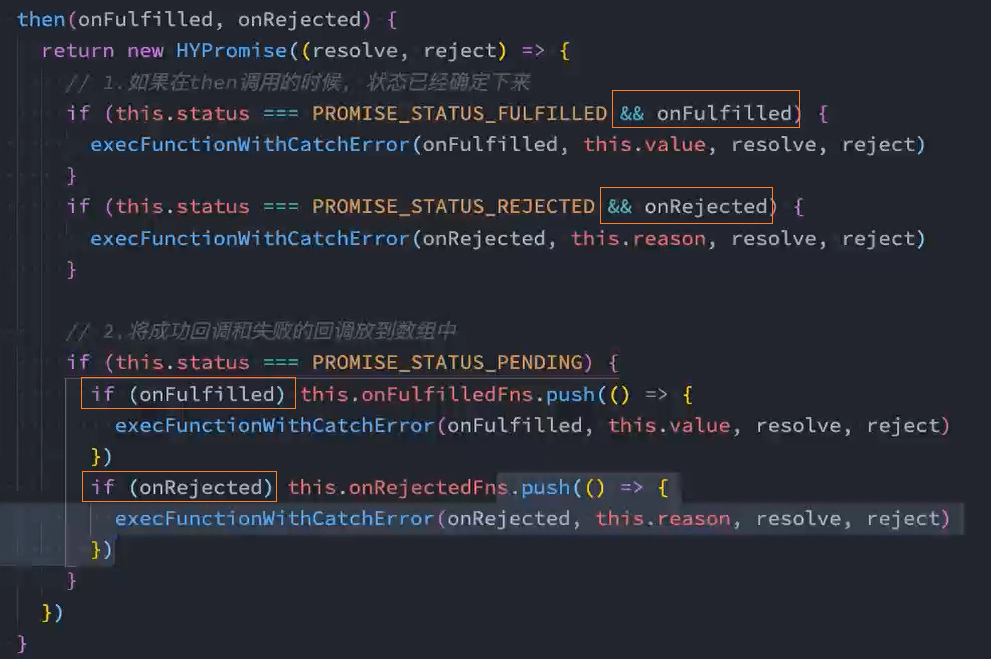
问题: catch调用的是通过返回的新promise调用的,并不是和then同一个promise
解决: 当promise1中的reject为空时,在then方法执行reject回调处抛出一个异常。这样就会被第二个promise接收到了
实例方法-finally
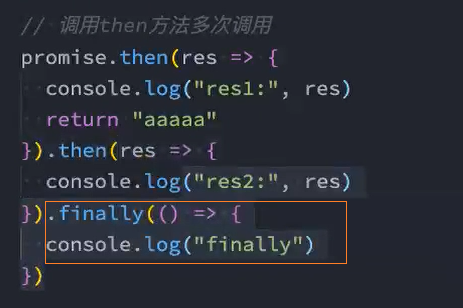
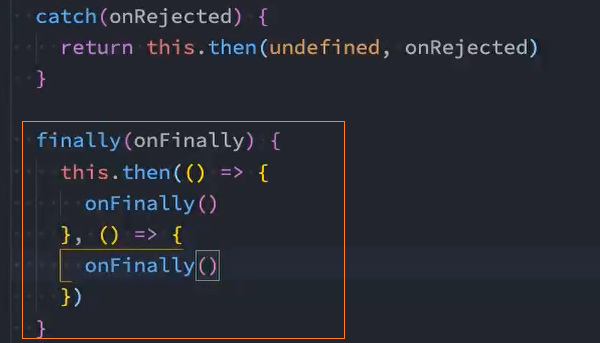
问题: 添加catch后,执行resolve时,finally被阻止了,不再执行finally中的回调。只有执行reject时才会执行finally
原因: 这是由于catch方法中是这样调用then的:this.then(undefined, onRejected),其中成功回调是undefined,所以就不会处理上次then返回的值
解决:
类方法-resolve

使用resolve

类方法-reject

使用reject

类方法-all
关键: 什么时候要执行resolve、什么时候要执行reject
使用all
类方法-allSettled
使用allSetted
类方法-race
等同于下面的写法
使用race
类方法-any
使用any



▸最终代码
/* 工具函数-封装try...catch函数 */
function runFunctionWithCatchError(fn, value, resolve, reject) {
try {
resolve(fn(value))
} catch (err) {
reject(err)
}
}
// Promise状态
const PROMISE_STATUS_PENDING = 'pending'
const PROMISE_STATUS_FULFILLED = 'fulfilled'
const PROMISE_STATUS_REJECTED = 'rejected'
class MrPromise {
constructor(executor) {
this.status = PROMISE_STATUS_PENDING
this.value = undefined
this.reason = undefined
this.onFulfilledFns = []
this.onRejectedFns = []
const resolve = (value) => {
if (this.status === PROMISE_STATUS_PENDING) {
queueMicrotask(() => {
if (this.status !== PROMISE_STATUS_PENDING) return
this.status = PROMISE_STATUS_FULFILLED
this.value = value
for (const fn of this.onFulfilledFns) {
fn(this.value)
}
})
}
}
const reject = (reason) => {
if (this.status === PROMISE_STATUS_PENDING) {
queueMicrotask(() => {
if (this.status !== PROMISE_STATUS_PENDING) return
this.status = PROMISE_STATUS_REJECTED
this.reason = reason
for (const fn of this.onRejectedFns) {
fn(this.reason)
}
})
}
}
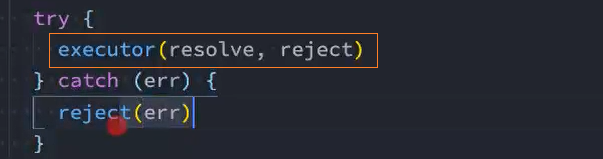
try {
executor(resolve, reject)
} catch (err) {
reject(err)
}
}
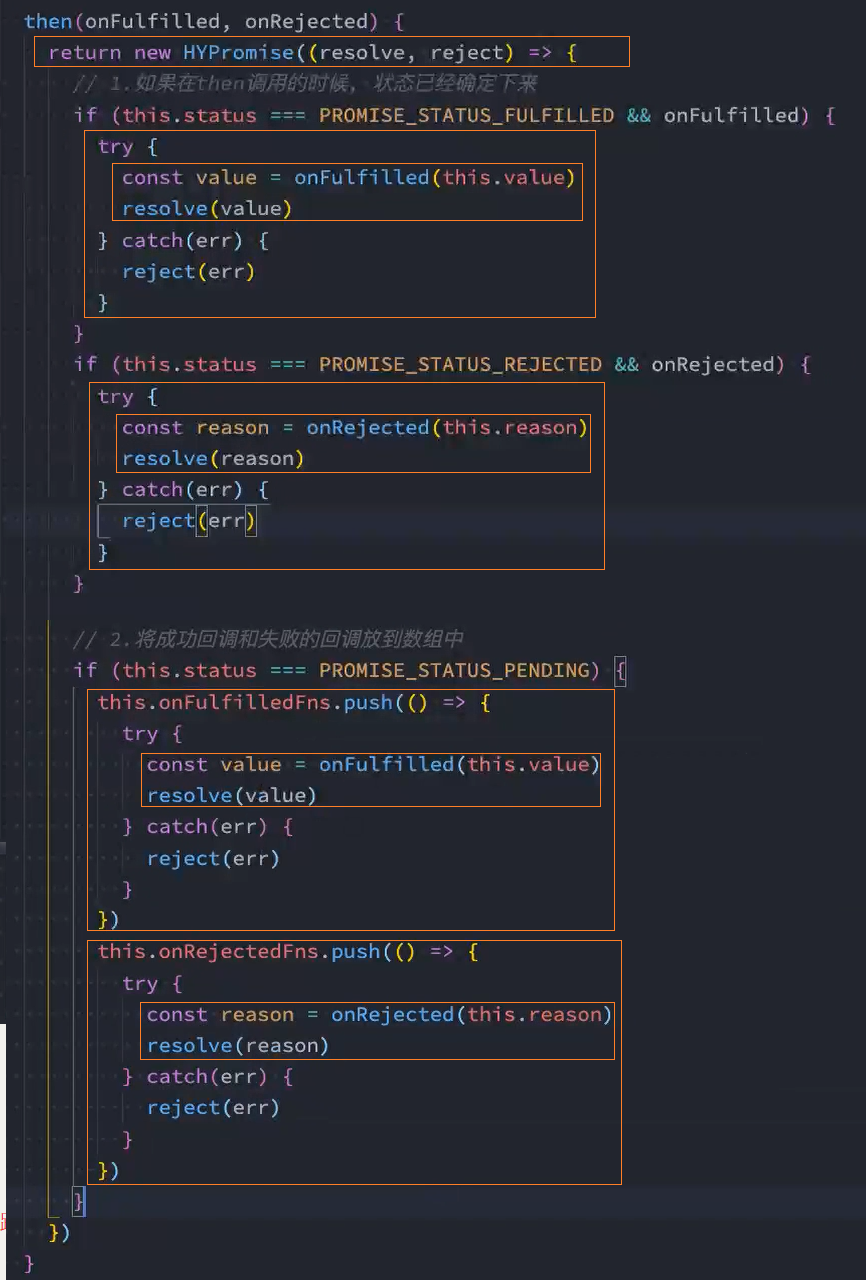
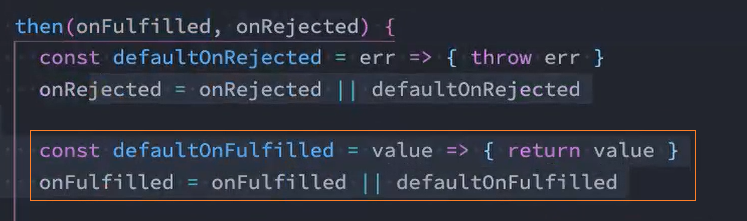
then(onFulfilled, onRejected) {
// 判断onFulfilled、onRejected回调函数是否存在
onRejected = onRejected || ((err) => { throw err })
onFulfilled = onFulfilled || ((res) => res)
return new MrPromise((resolve, reject) => {
// console.log('then status: ', this.status)
if (this.status === PROMISE_STATUS_FULFILLED) {
runFunctionWithCatchError(onFulfilled, this.value, resolve, reject)
}
if (this.status === PROMISE_STATUS_REJECTED) {
runFunctionWithCatchError(onRejected, this.reason, resolve, reject)
}
if (this.status === PROMISE_STATUS_PENDING) {
this.onFulfilledFns.push(() => {
runFunctionWithCatchError(onFulfilled, this.value, resolve, reject)
})
this.onRejectedFns.push(() => {
runFunctionWithCatchError(onRejected, this.reason, resolve, reject)
})
}
})
}
catch(onRejected) {
return this.then(undefined, onRejected)
}
finally(onFinally) {
this.then(
() => {
onFinally()
},
() => {
onFinally()
}
)
}
static resolve(value) {
return new Promise((resolve) => resolve(value))
}
static reject(reason) {
return new Promise((resolve, reject) => reject(reason))
}
static all(promises) {
return new Promise((resolve, reject) => {
const values = []
promises.forEach((promise) => {
promise.then(
(res) => {
values.push(res)
if (values.length === promises.length) {
resolve(values)
}
},
(err) => {
reject(err)
}
)
})
})
}
static allSettled(promises) {
return new Promise((resolve, reject) => {
const results = []
promises.forEach((promise) => {
promise.then(
(res) => {
results.push({ status: 'fulfilled', value: res })
if (results.length === promises.length) {
resolve(results)
}
},
(err) => {
results.push({ status: 'rejected', reason: err })
if (results.length === promises.length) {
resolve(results)
}
}
)
})
})
}
static race(promises) {
return new Promise((resolve, reject) => {
promises.forEach((promise) => {
promise.then(
(res) => {
resolve(res)
},
(err) => {
reject(err)
}
)
})
})
}
static any(promises) {
return new Promise((resolve, reject) => {
const reasons = []
promises.forEach((promise) => {
promise.then(
(res) => {
resolve(res)
},
(err) => {
reasons.push(err)
if (reasons.length === promises.length) {
reject(new AggregateError(err))
}
}
)
})
})
}
}测试
// 测试
const p1 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p1~')
}, 3000)
})
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p2~')
}, 5000)
})
const p3 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p3~')
}, 3000)
})
const p = new MrPromise((resolve, reject) => {
// throw new Error('抛出异常')
resolve('aaa')
// reject('111')
// setTimeout(() => {
// // resolve('aaa')
// reject('111')
// }, 1000)
})
// - 类方法-any
Promise.any([p1, p2, p3]).then(
(res) => {
console.log('any res: ', res)
},
(err) => {
console.log('any err: ', err)
}
)
// // - 类方法-race
// Promise.race([p1, p2, p3]).then(
// (res) => {
// console.log('race res: ', res)
// },
// (err) => {
// console.log('race err: ', err)
// }
// )
// // - 类方法-allSettled
// Promise.allSettled([p1, p2, p3]).then((res) => {
// console.log('allSettled: ', res)
// })
// // - 类方法-all
// Promise.all([p1, p2, p3]).then(
// (res) => {
// console.log('all res: ', res)
// },
// (err) => {
// console.log('all err: ', err)
// }
// )
// // - 类方法-reject
// Promise.reject('222').catch((err) => {
// console.log(err)
// })
// // - 类方法-resolve
// Promise.resolve('1111').then((res) => {
// console.log(res)
// })
// p.then(
// (res) => {
// console.log('res: ', res)
// },
// (err) => {
// console.log('err: ', err)
// }
// )
// // - 异步延迟调用
// setTimeout(() => {
// p.then(
// (res) => {
// console.log('异步延时调用 res: ', res)
// },
// (err) => {
// console.log('异步延时调用 err: ', err)
// }
// )
// }, 2000)
// // - 链式调用
// p.then(
// (res) => {
// console.log('链式调用 res1: ', res)
// return 'bbb'
// },
// (err) => {
// console.log('链式调用 err1: ', err)
// return '222'
// }
// ).then(
// (res) => {
// console.log('链式调用 res2: ', res)
// return 'ccc'
// },
// (err) => {
// console.log('链式调用 err2: ', err)
// return '333'
// }
// )
// // - catch
// p.then((res) => {
// console.log('then res: ', res)
// }).catch((err) => {
// console.log('catch err: ', err)
// })
// // - finally
// p.then((res) => {
// console.log('then res: ', res)
// })
// .catch((err) => {
// console.log('catch err: ', err)
// })
// .finally(() => {
// console.log('finally~')
// })
// p.then(
// (res) => {
// console.log('res: ', res)
// },
// (err) => {
// console.log('err: ', err)
// }
// )
// p.then(
// (res) => {
// console.log('res2: ', res)
// },
// (err) => {
// console.log('err2: ', err)
// }
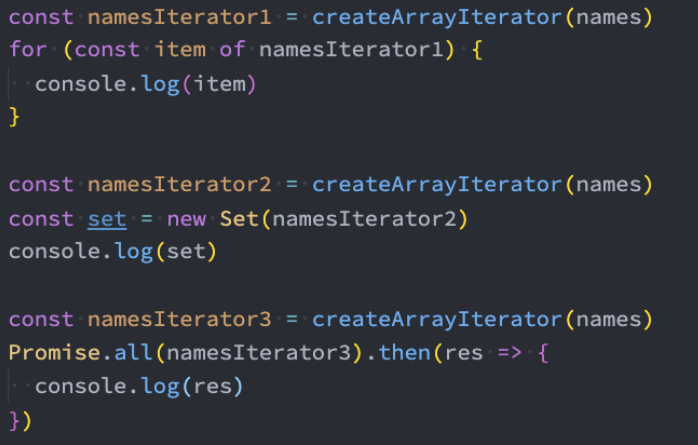
// )Iterator
概念:
- 迭代器:Iterator。它是一种提供遍历集合元素的机制。
- 可迭代对象:Iterable。它是一种实现了Iterator Protocol方法的对象。
- 迭代器协议:Iterator Protocol。它是一种定义迭代器对象的标准,它规定了迭代器对象必须实现的方法和属性。
迭代器-介绍
迭代器(iterator),使用户在容器对象(container,例如链表或数组)上遍访的对象,使用该接口无需关心对象的内部实现细节。
其行为像数据库中的光标,迭代器最早出现在1974年设计的CLU编程语言中;
在各种编程语言的实现中,迭代器的实现方式各不相同,但是基本都有迭代器,比如Java、Python等;
从迭代器的定义我们可以看出来,迭代器是帮助我们对某个数据结构进行遍历的对象。
在JavaScript中,迭代器也是一个具体的对象,这个对象需要符合迭代器协议(iterator protocol):
迭代器协议定义了产生一系列值(无论是有限还是无限个)的标准方式;
在JavaScript中这个标准就是一个特定的next方法;
next方法有如下的要求:
一个无参数或者一个参数的函数,返回一个应当拥有以下两个属性的对象:
done(boolean)
- 如果迭代器可以产生序列中的下一个值,则为 false。(这等价于没有指定 done 这个属性。)
- 如果迭代器已将序列迭代完毕,则为 true。这种情况下,value 是可选的,如果它依然存在,即为迭代结束之后的默认返回值。
value
- 迭代器返回的任何 JavaScript 值。done 为 true 时可省略。
迭代器-语法
JS中的迭代器:实现了next方法的对象,在next方法中必须返回一个包含了done和value属性的对象
const arr = ['a', 'b', 'c']
let index = 0
const iterator = {
next: function() {
return index < arr.length ? {done: false, vlaue: arr[index++]} : {done: true, value: undefined}
}
}示例: 迭代器的代码练习
1、迭代器-基本案例
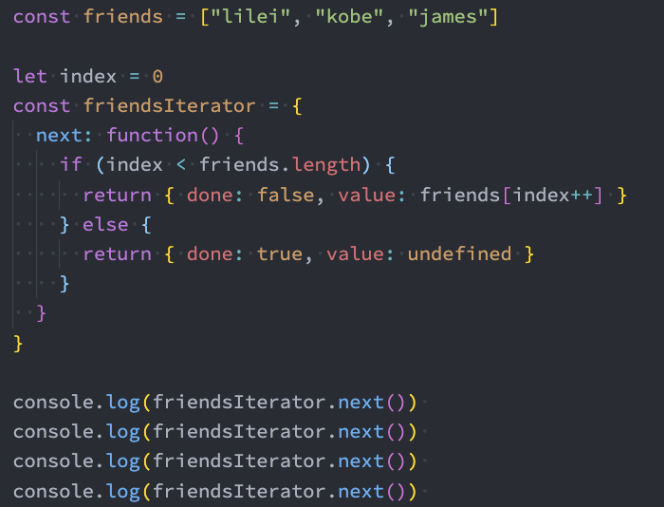
2、迭代器-封装一个通用的迭代器生成函数
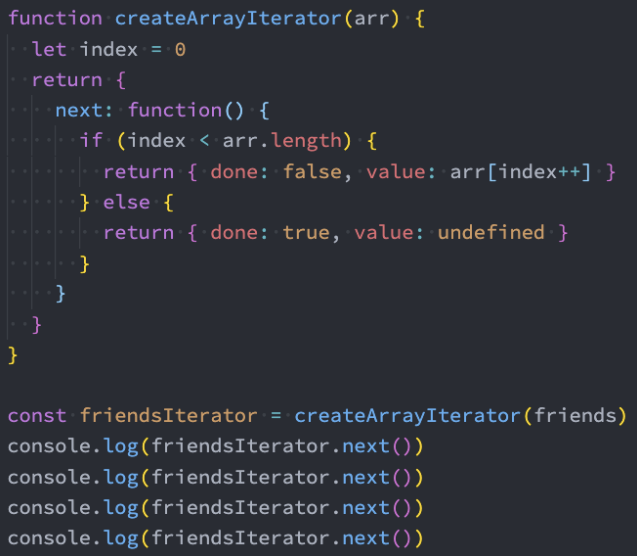
可迭代对象-介绍
但是上面的代码整体来说看起来是有点奇怪的:
我们获取一个数组的时候,需要自己创建一个index变量,再创建一个所谓的迭代器对象;
事实上我们可以对上面的代码进行进一步的封装,让其变成一个可迭代对象;
什么又是可迭代对象呢?
它和迭代器是不同的概念;
当一个对象实现了iterable protocol协议时,它就是一个可迭代对象;
这个对象的要求是必须实现 @@iterator 方法,在代码中我们使用 Symbol.iterator 访问该属性;
当然我们要问一个问题,我们转成这样的一个东西有什么好处呢?
当一个对象变成一个可迭代对象的时候,就可以进行某些迭代操作;
比如 for...of 操作时,其实就会调用它的 @@iterator 方法;
特性:
1、可迭代对象内部需要实现[Symbol.iterator] 方法,该方法返回一个迭代器。
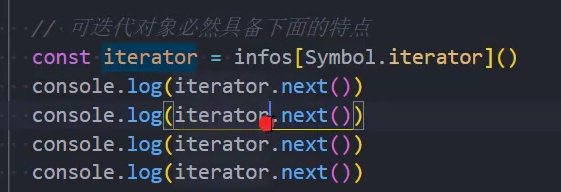
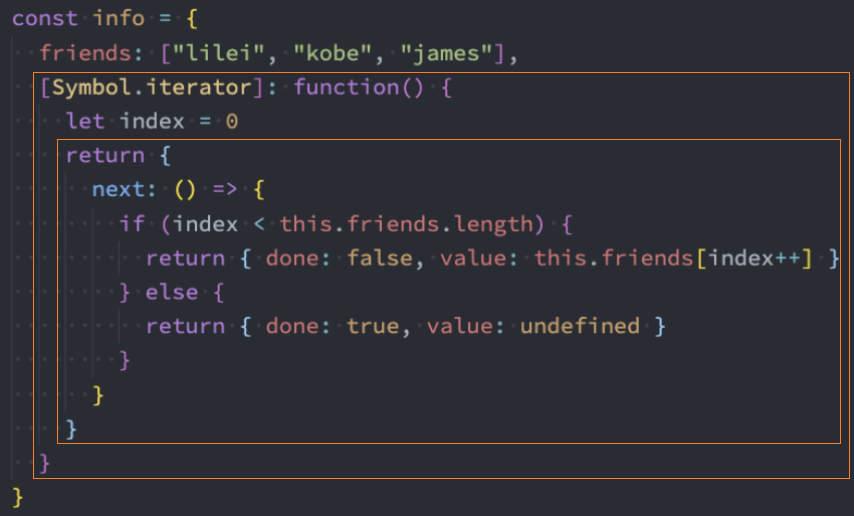
2、可迭代对象可以进行for...of遍历
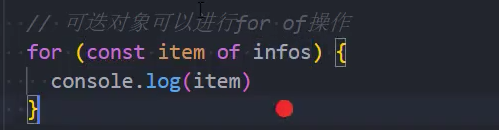
可迭代对象-优化
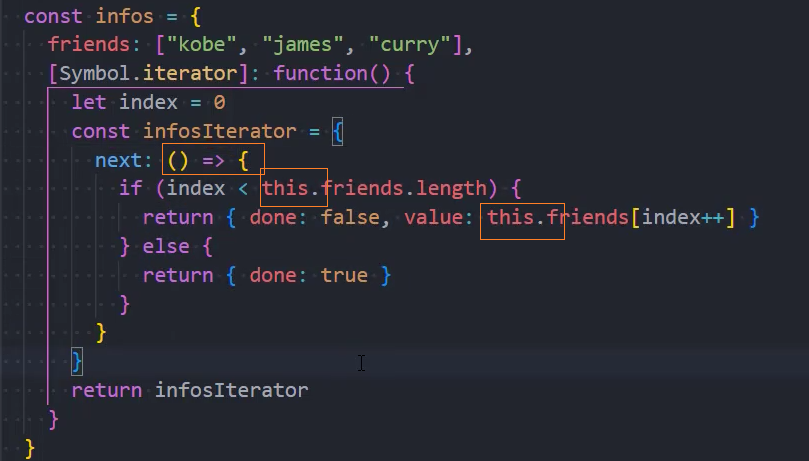
1、迭代infos中的friends属性
next函数用箭头函数书写,可以让其内部的this指向可迭代对象,从而实现更通用的封装
2、迭代对象中的键,值,键值对
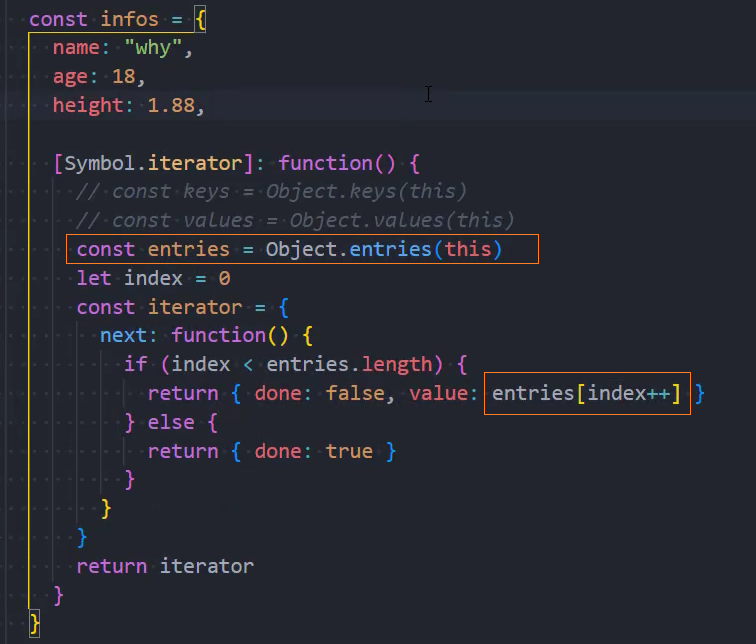
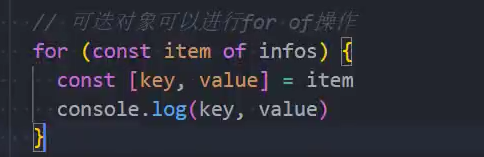
可迭代对象-内置
事实上我们平时创建的很多原生对象已经实现了可迭代协议,会生成一个可迭代对象的:
- String、Array、Map、Set、arguments对象、NodeList集合;
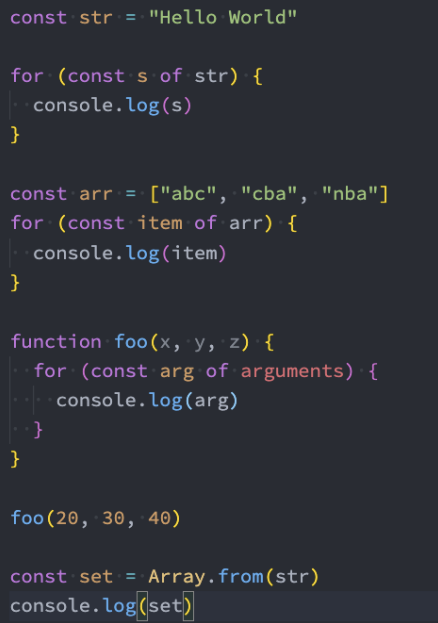

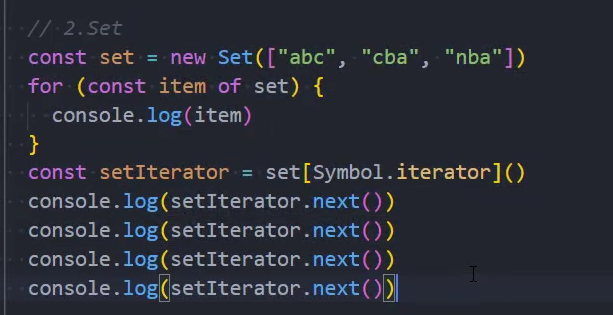
可迭代对象-应用
那么这些东西可以被用在哪里呢?
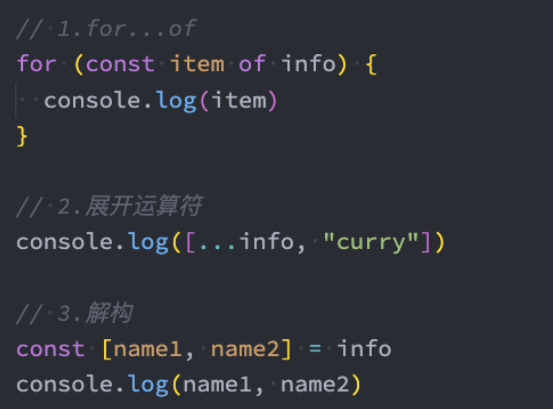
JS中语法:for ...of、展开语法(spread syntax)、yield*(后面讲)、解构赋值(Destructuring_assignment);
创建一些对象时:new Map([Iterable])、new WeakMap([iterable])、new Set([iterable])、new WeakSet([iterable]);
一些方法的调用:Promise.all(iterable)、Promise.race(iterable)、Array.from(iterable);

自定义类的迭代
在前面我们看到Array、Set、String、Map等类创建出来的对象都是可迭代对象:
在面向对象开发中,我们可以通过class定义一个自己的类,这个类可以创建很多的对象:
如果我们也希望自己的类创建出来的对象默认是可迭代的,那么在设计类的时候我们就可以添加上 @@iterator 方法;
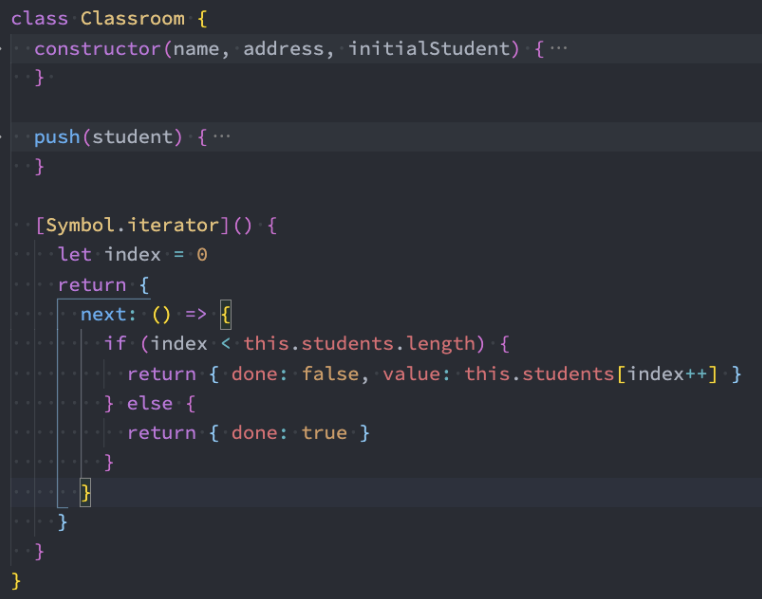
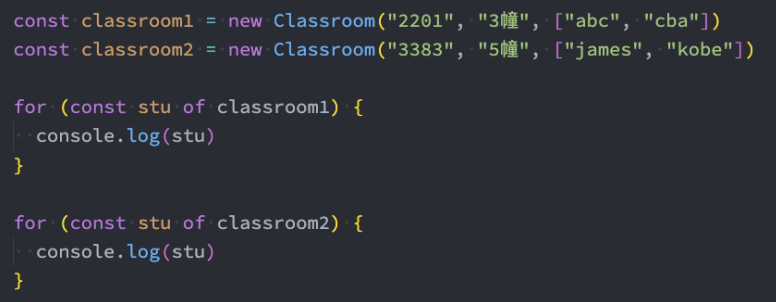
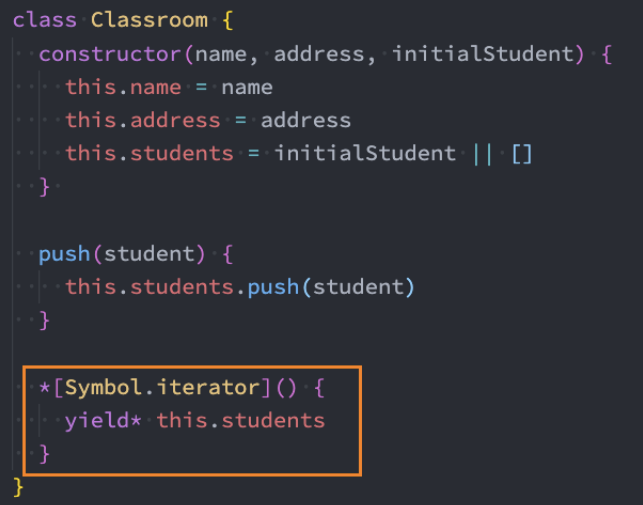
案例:创建一个classroom的类
教室中有自己的位置、名称、当前教室的学生;
这个教室可以进来新学生(push);
创建的教室对象是可迭代对象;
自定义类的迭代实现
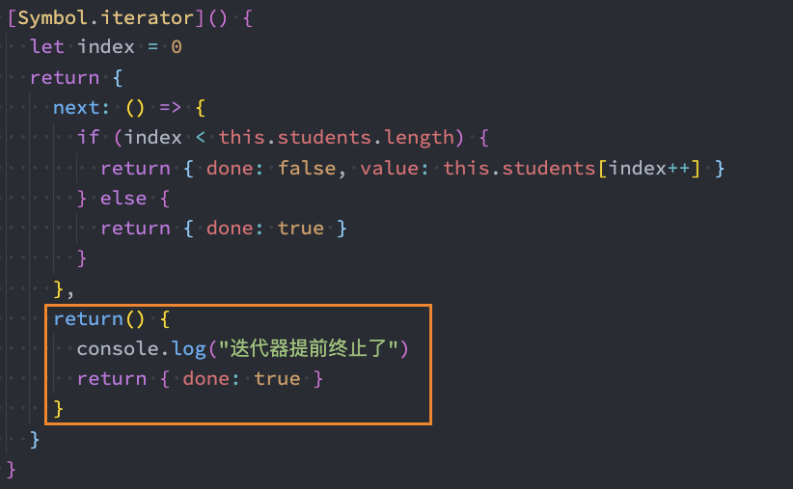
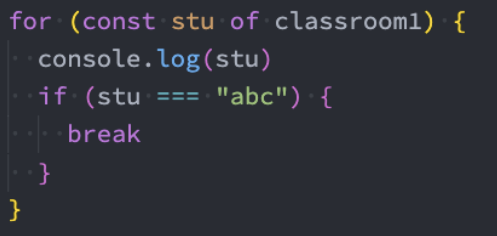
迭代器-监听中断
迭代器在某些情况下会在没有完全迭代的情况下中断:
比如遍历的过程中通过break、return、throw中断了循环操作;
比如在解构的时候,没有解构所有的值;
那么这个时候我们想要监听中断的话,可以添加return方法:
Generator
什么是生成器?
生成器是ES6中新增的一种函数控制、使用的方案,它可以让我们更加灵活的控制函数什么时候继续执行、暂停执行等。
- 平时我们会编写很多的函数,这些函数终止的条件通常是返回值或者发生了异常。
生成器函数特点:
生成器函数也是一个函数,但是和普通的函数有一些区别:
首先,生成器函数需要在function的后面加一个符号:* :
function* foo()或者function *foo()其次,生成器函数可以通过yield关键字来控制函数的执行流程:
最后,生成器函数执行时返回一个Generator(生成器):
- 要想执行函数内部的代码,需要通过生成器对象调用它的next方法
- 当遇到yield时,就会中断执行,需要再次调用next方法,才会继续执行
生成器事实上是一种特殊的迭代器;
- MDN:Instead, they return a special type of iterator, called a Generator.
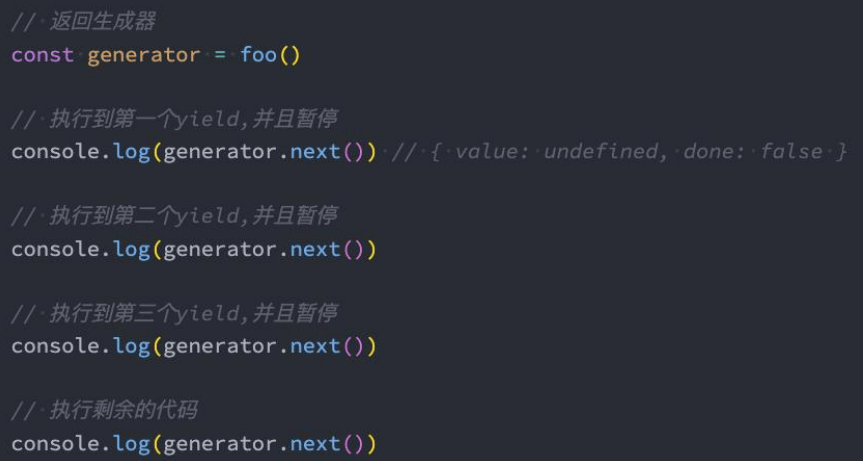
生成器函数执行
我们发现下面的生成器函数foo的执行体压根没有执行,它只是返回了一个生成器对象。
那么我们如何可以让它执行函数中的东西呢?调用next即可;
我们之前学习迭代器时,知道迭代器的next是会有返回值的;
但是我们很多时候不希望next返回的是一个undefined,这个时候我们可以通过yield来返回结果;
生成器-返回值
通过yield返回结果
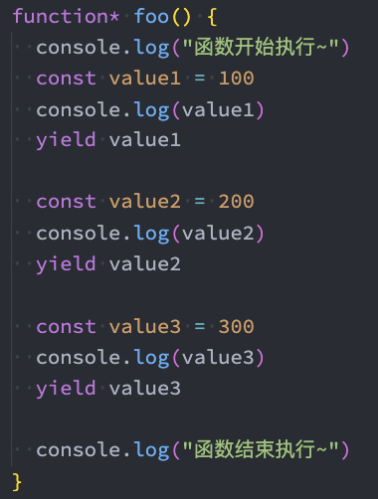
生成器-传递参数 – next()
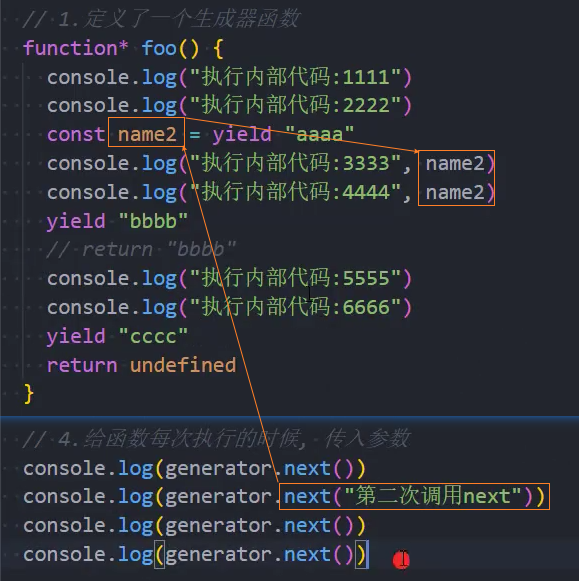
函数既然可以暂停来分段执行,那么函数应该是可以传递参数的,我们是否可以给每个分段来传递参数呢?
答案是可以的;
我们在调用next函数的时候,可以给它传递参数,那么这个参数会作为上一个yield语句的返回值;
注意:也就是说我们是为本次的函数代码块执行提供了一个值;
传递参数:
- 1、第一次传递参数
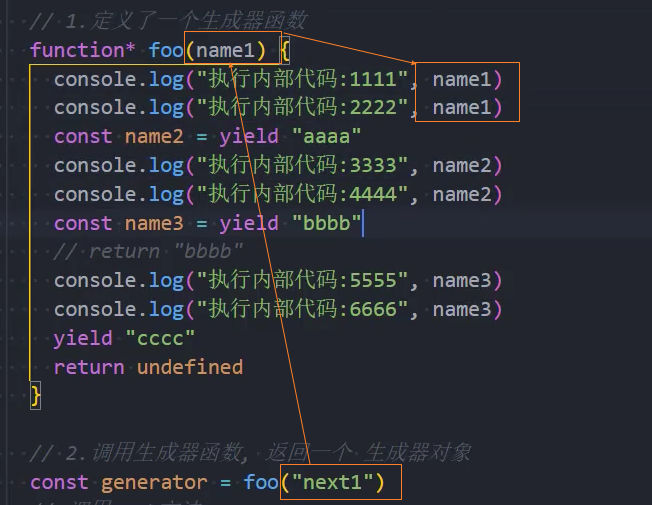
- 2、之后传递参数
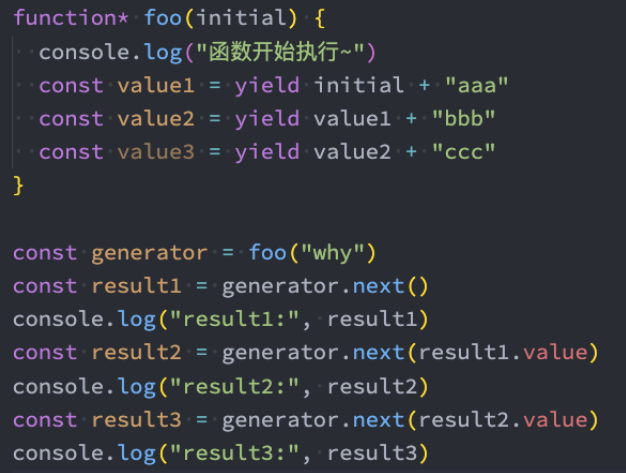
示例:
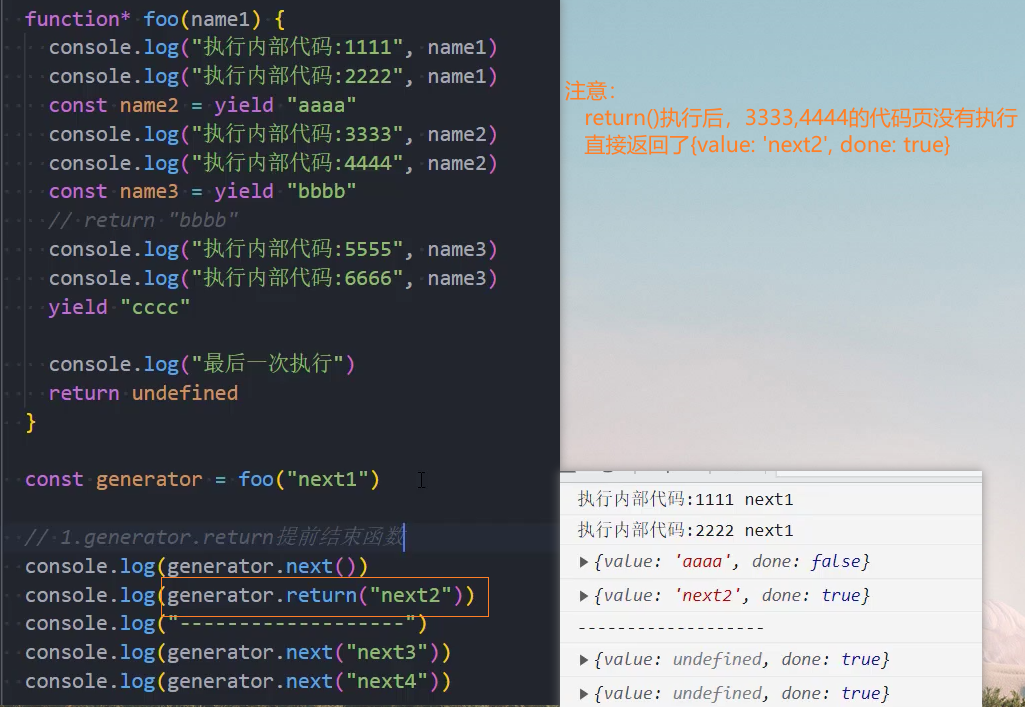
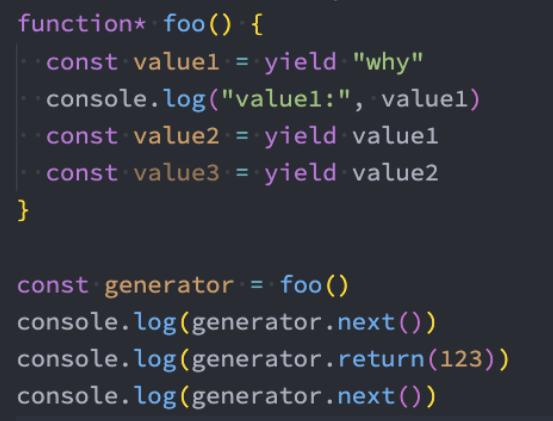
生成器-提前结束 – return()
还有一个可以给生成器函数传递参数的方法是通过return函数:
- return传值后这个生成器函数就会立即结束,之后调用next不会继续生成值了;
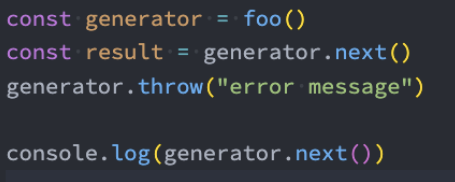
生成器-抛出异常 – throw()
除了给生成器函数内部传递参数之外,也可以给生成器函数内部抛出异常:
抛出异常后我们可以在生成器函数中捕获异常;
但是在catch语句中不能继续yield新的值了,但是可以在catch语句外使用yield继续中断函数的执行;

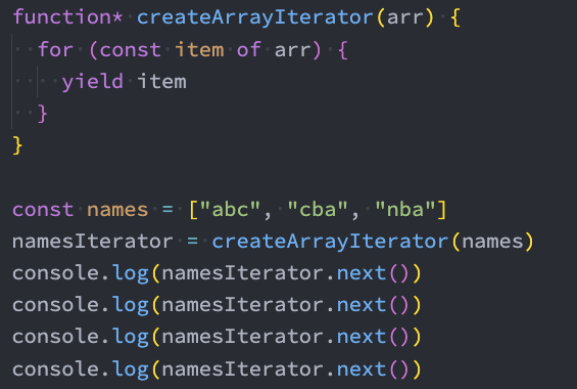
生成器替代迭代器
我们发现生成器是一种特殊的迭代器,那么在某些情况下我们可以使用生成器来替代迭代器:
示例: 利用生成器对之前的迭代器代码进行重构
示例: 生成器函数,可以生成某个范围的值
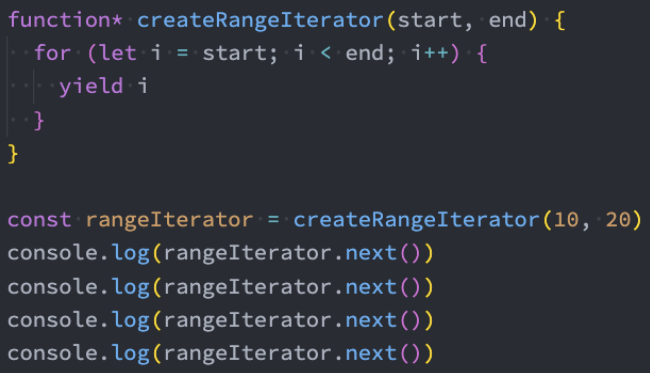
生成器-yield*
事实上我们还可以使用*yield**来生成一个可迭代对象:
语法
yield* iterable说明:iterable 是可迭代对象
特性:
1、yield* 是 yield 语句的一种语法糖。它会依次迭代这个可迭代对象,每次迭代其中的一个值。
2、yield* 只能存在于生成器函数中。
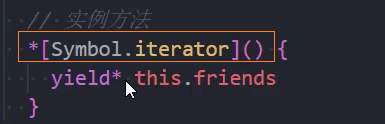
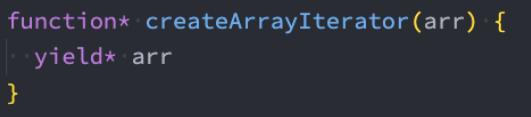
替代-可迭代对象
替代-自定义类迭代
在之前的自定义类迭代中,我们也可以换成生成器:
对生成器的操作
既然生成器是一个迭代器,那么我们可以对其进行如下的操作:
异步处理方案
学完了我们前面的Promise、生成器等,我们目前来看一下异步代码的最终处理方案。
案例需求:
我们需要向服务器发送网络请求获取数据,一共需要发送三次请求;
第二次的请求url依赖于第一次的结果;
第三次的请求url依赖于第二次的结果;
依次类推;
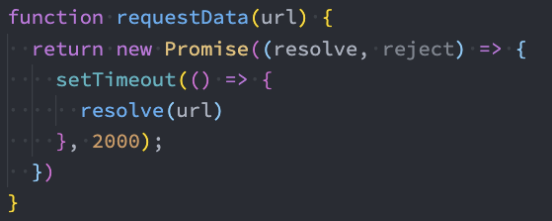
回调地狱:回调嵌套
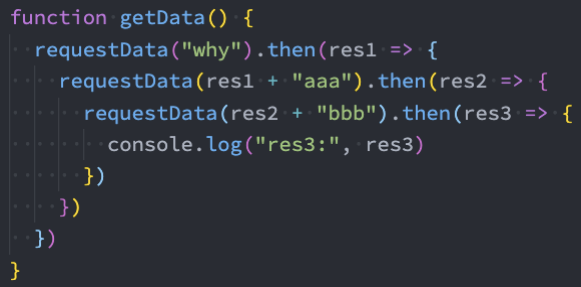
链式调用:Promise
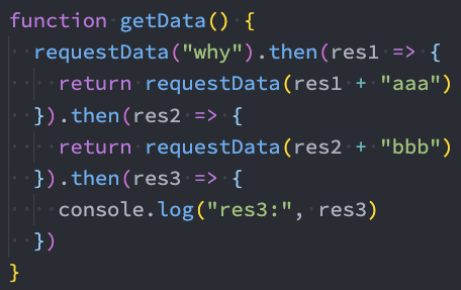
Generator方案
但是上面的代码其实看起来也是阅读性比较差的,有没有办法可以继续来对上面的代码进行优化呢?
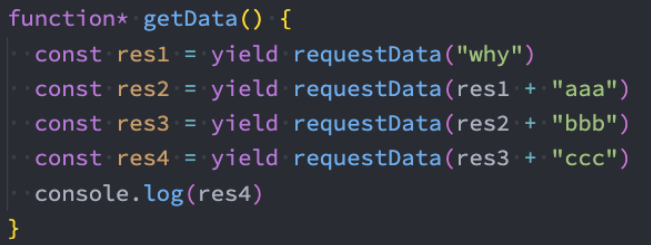
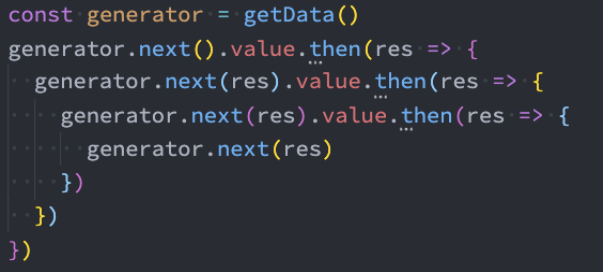
自动执行generator函数
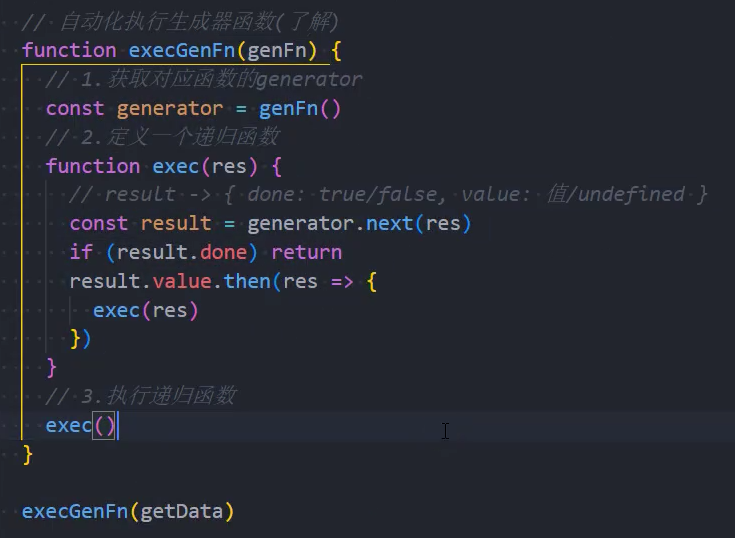
目前我们的写法有两个问题:
第一,我们不能确定到底需要调用几层的Promise关系;
第二,如果还有其他需要这样执行的函数,我们应该如何操作呢?
所以,我们可以封装一个工具函数execGenerator自动执行生成器函数:
async、await
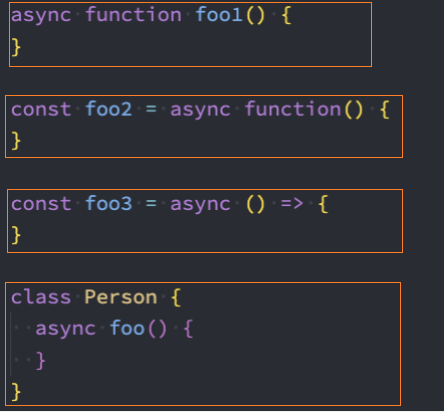
异步函数 async function
async关键字用于声明一个异步函数:
async是asynchronous单词的缩写,异步、非同步;
sync是synchronous单词的缩写,同步、同时;
async异步函数可以有很多中写法:
特性:
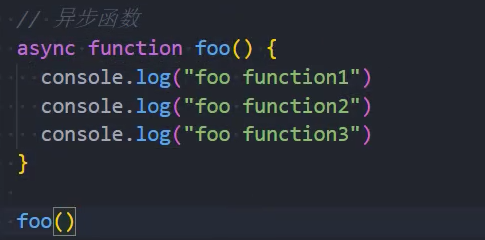
1、异步函数默认情况下和普通函数一样
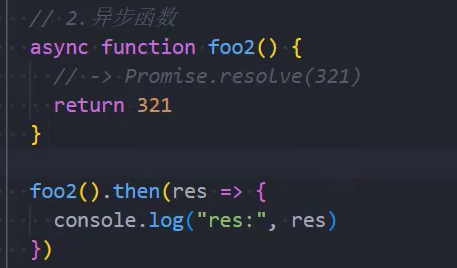
2、异步函数返回的是一个Promise
异步函数的执行流程
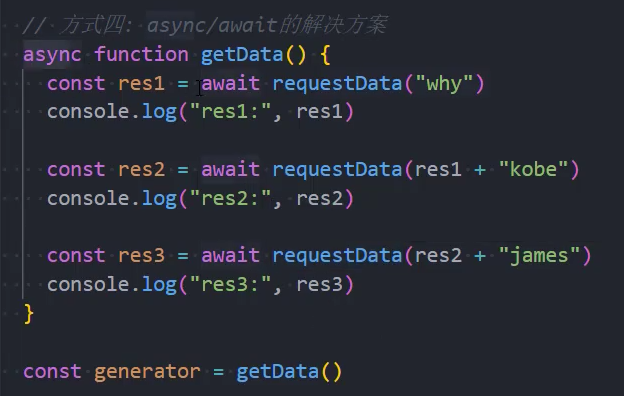
异步函数的内部代码执行过程和普通的函数是一致的,默认情况下也是会被同步执行。
异步函数有返回值时,和普通函数会有区别:
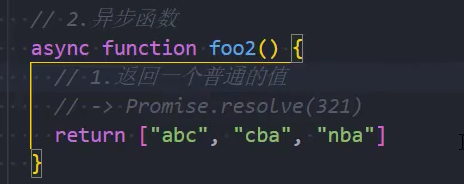
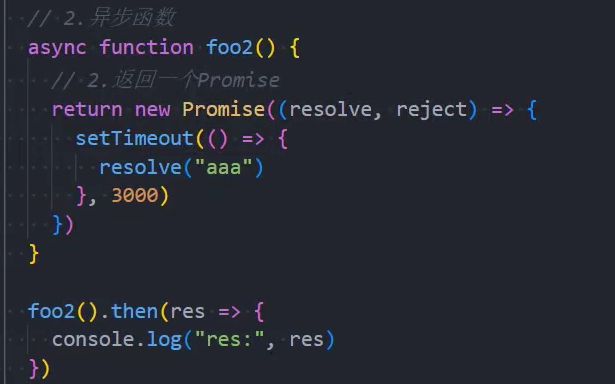
情况一:异步函数也可以有返回值,但是异步函数的返回值相当于被包裹到Promise.resolve中;
情况二:如果我们的异步函数的返回值是Promise,状态由会由Promise决定;
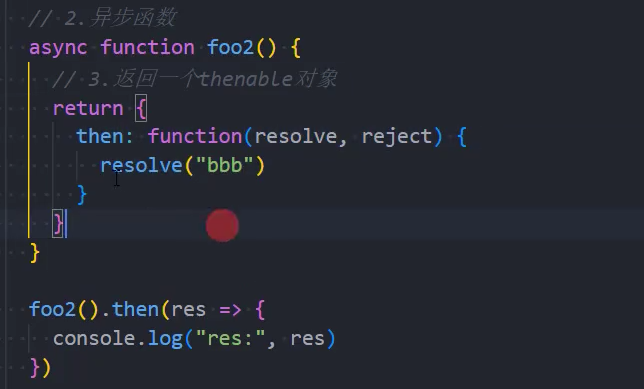
情况三:如果我们的异步函数的返回值是一个对象并且实现了thenable,那么会由对象的then方法来决定;
示例: 返回一个普通的值
示例: 返回一个Promise
示例: 返回一个thenable
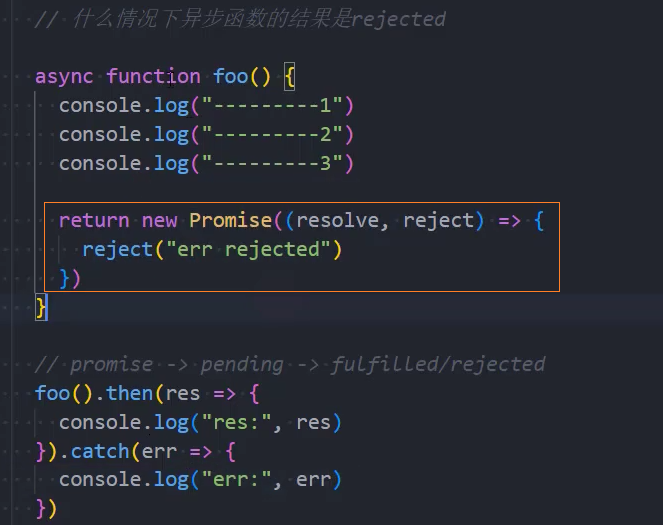
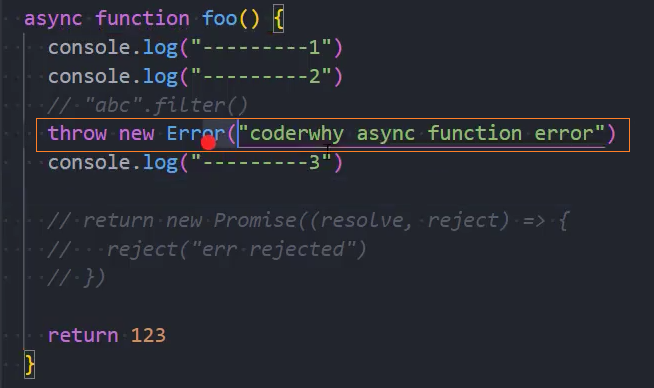
什么情况下异步函数的结果是rejected:
在异步函数中返回一个执行reject的Promise
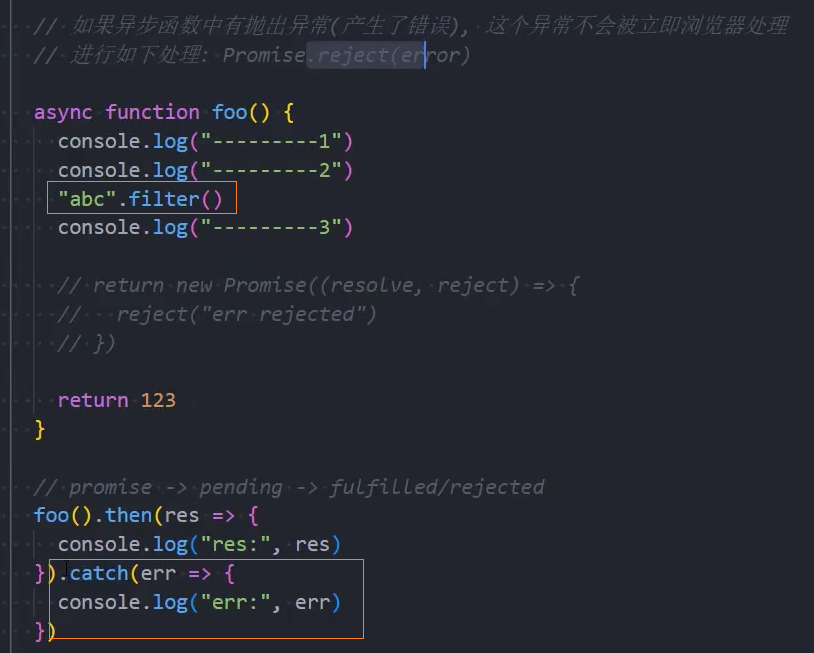
如果我们在async中抛出了异常,那么程序它并不会像普通函数一样报错,而是会作为Promise的reject来传递;
示例: 在异步函数中返回一个执行reject的Promise
示例: 在异步函数中抛出了异常
await关键字
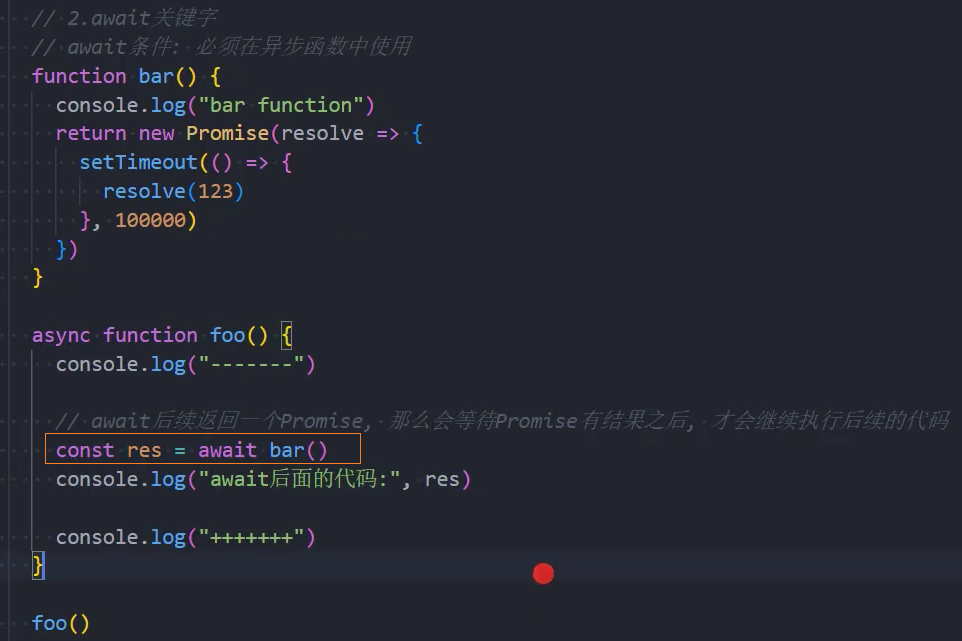
async函数另外一个特殊之处就是可以在它内部使用await关键字,而普通函数中是不可以的。
await关键字有什么特点呢?
通常使用await是后面会跟上一个表达式,这个表达式会返回一个Promise;
那么await会等到Promise的状态变成fulfilled状态,之后继续执行异步函数;
如果await后面是一个普通的值,那么会直接返回这个值;
如果await后面是一个thenable的对象,那么会根据对象的then方法调用来决定后续的值;
如果await后面的表达式,返回的Promise是reject的状态,那么会将这个reject结果直接作为函数的Promise的reject值;
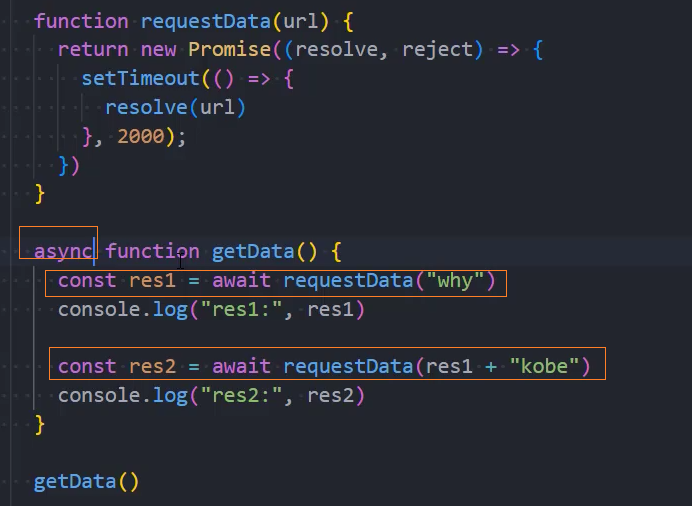
示例: await处理异步请求
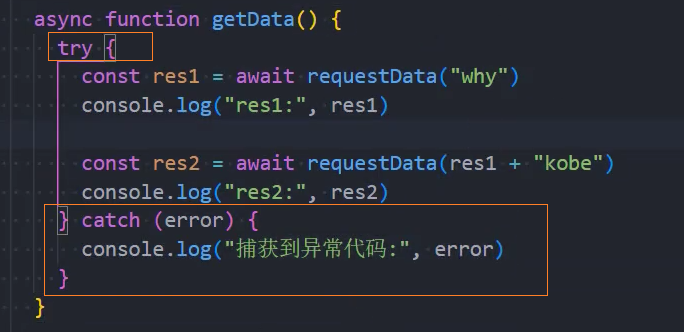
在异步函数中抛出异常的处理方式
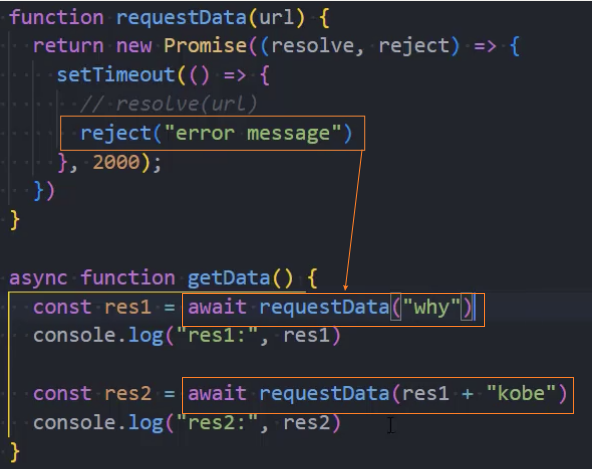
1、方式一:在异步函数后的catch中捕获异常
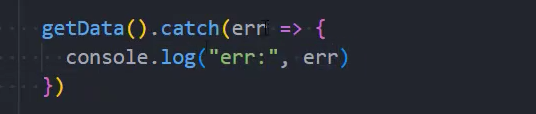
2、方式二:在异步函数内部,通过try...catch,捕获异常
浏览器进程、线程
进程和线程
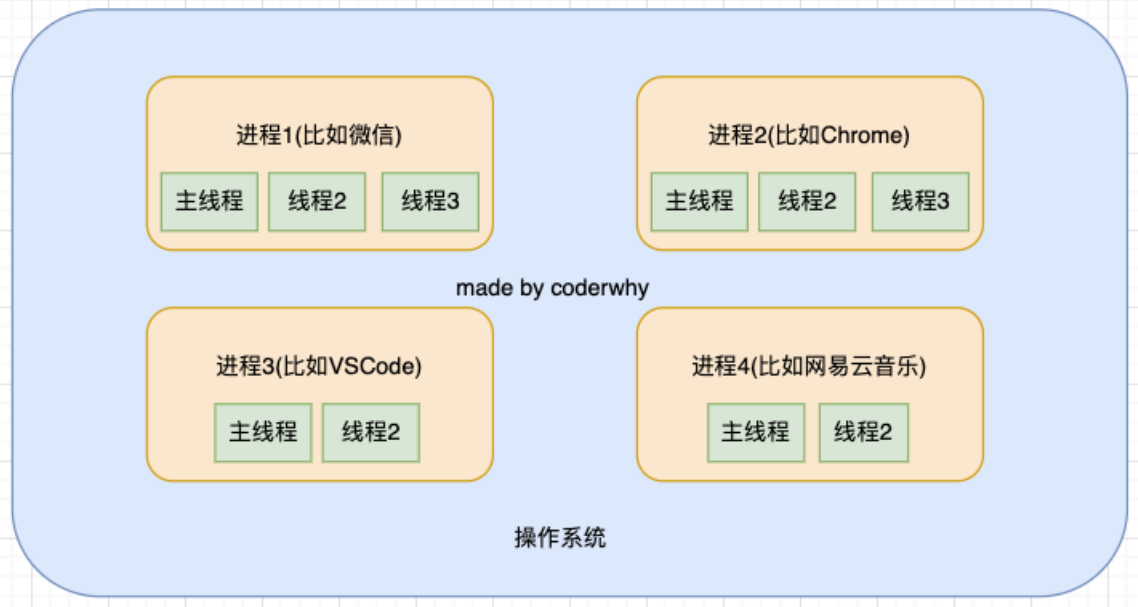
线程和进程是操作系统中的两个概念:
进程(process):计算机已经运行的程序,是操作系统管理程序的一种方式;
线程(thread):操作系统能够运行运算调度的最小单位,通常情况下它被包含在进程中;
听起来很抽象,这里还是给出我的解释:
进程:我们可以认为,启动一个应用程序,就会默认启动一个进程(也可能是多个进程);
线程:每一个进程中,都会启动至少一个线程用来执行程序中的代码,这个线程被称之为主线程;
所以我们也可以说进程是线程的容器;
再用一个形象的例子解释:
操作系统类似于一个大工厂;
工厂中里有很多车间,这个车间就是进程;
每个车间可能有一个以上的工人在工厂,这个工人就是线程;
操作系统-进程-线程
操作系统的工作方式
操作系统是如何做到同时让多个进程(边听歌、边写代码、边查阅资料)同时工作呢?
这是因为CPU的运算速度非常快,它可以快速的在多个进程之间迅速的切换;
当我们进程中的线程获取到时间片时,就可以快速执行我们编写的代码;
对于用户来说是感受不到这种快速的切换的;
你可以在Mac的活动监视器或者Windows的资源管理器中查看到很多进程:
浏览器中的JavaScript线程
我们经常会说*JavaScript是单线程(可以开启workers)的,但是JavaScript的线程应该有自己的容器进程**:浏览器或者**Node。
浏览器是一个进程吗,它里面只有一个线程吗?
目前多数的浏览器其实都是多进程的,当我们打开一个tab页面时就会开启一个新的进程,这是为了防止一个页面卡死而造成所有页面无法响应,整个浏览器需要强制退出;
每个进程中又有很多的线程,其中包括执行JavaScript代码的线程;
JavaScript的代码执行是在一个单独的线程中执行的:**
这就意味着JavaScript的代码,在同一个时刻只能做一件事;
如果这件事是非常耗时的,就意味着当前的线程就会被阻塞;
所以真正耗时的操作,实际上并不是由JavaScript线程在执行的:
浏览器的每个进程是多线程的,那么其他线程可以来完成这个耗时的操作;
比如网络请求、定时器,我们只需要在特性的时候执行应该有的回调即可;
浏览器的事件循环
如果在执行JavaScript代码的过程中,有异步操作呢?
中间我们插入了一个setTimeout的函数调用;
这个函数被放到入调用栈中,执行会立即结束,并不会阻塞后续代码的执行;

宏任务、微任务队列
宏任务和微任务
但是事件循环中并非只维护着一个队列,事实上是有两个队列:
宏任务队列(macrotask queue):ajax、setTimeout、setInterval、DOM监听、UI Rendering等
微任务队列(microtask queue):Promise的then回调、 Mutation Observer API、*queueMicrotask()*等
那么事件循环对于两个队列的优先级是怎么样的呢?
1.main script中的代码优先执行(编写的顶层script代码);
2.在执行任何一个宏任务之前(不是队列,是一个宏任务),都会先查看微任务队列中是否有任务需要执行
- 也就是宏任务执行之前,必须保证微任务队列是空的;
- 如果不为空,那么就优先执行微任务队列中的任务(回调);
下面我们通过几到面试题来练习一下。
Promise面试题
Promise面试题
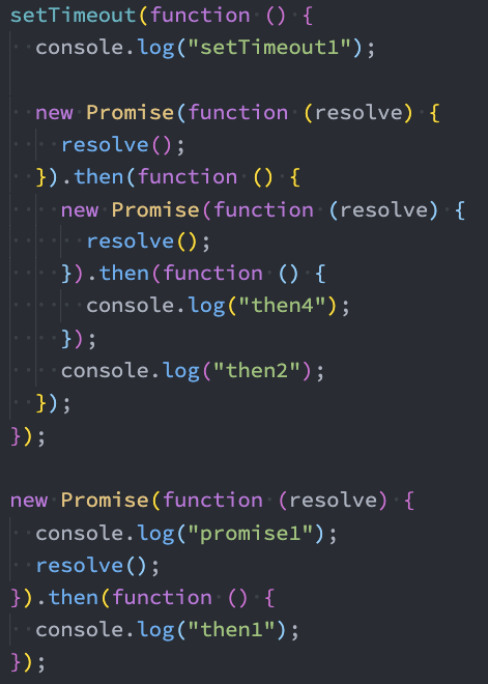
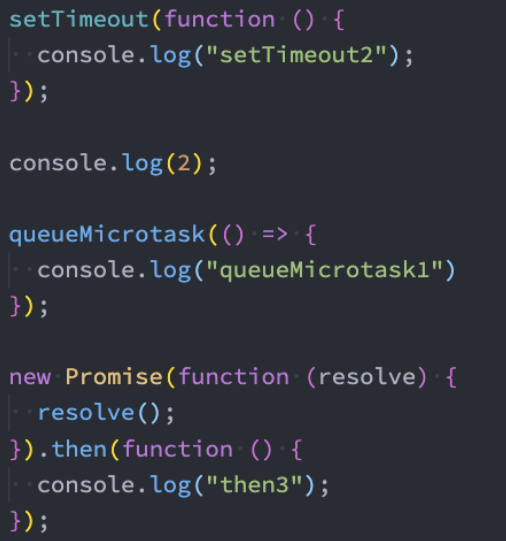
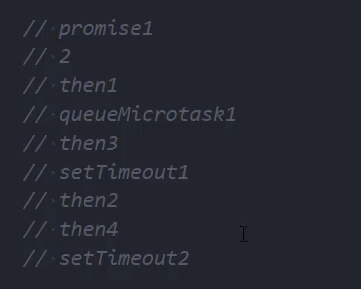
promise async await 面试题



事件循环
Node的事件循环
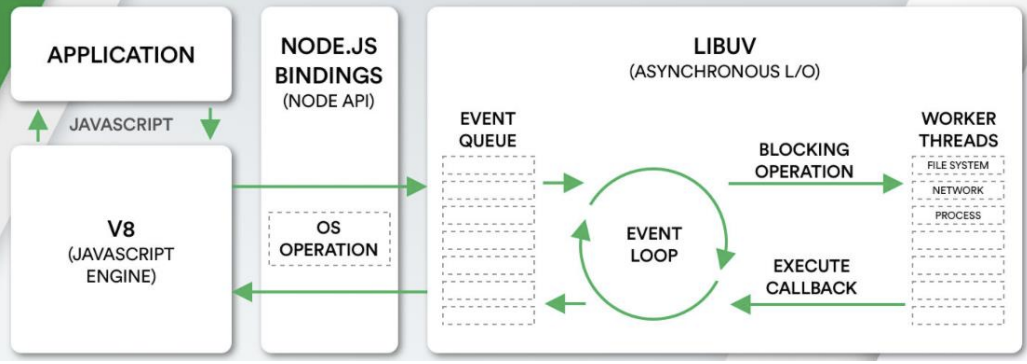
浏览器中的EventLoop是根据HTML5定义的规范来实现的,不同的浏览器可能会有不同的实现,而Node中是由libuv实现的。
这里我们来给出一个Node的架构图:
我们会发现libuv中主要维护了一个EventLoop和worker threads(线程池);
EventLoop负责调用系统的一些其他操作:文件的IO、Network、child-processes等
libuv是一个多平台的专注于异步IO的库,它最初是为Node开发的,但是现在也被使用到Luvit、Julia、pyuv等其他地方;
Node事件循环的阶段
我们最前面就强调过,事件循环像是一个桥梁,是连接着应用程序的JavaScript和系统调用之间的通道:
无论是我们的文件IO、数据库、网络IO、定时器、子进程,在完成对应的操作后,都会将对应的结果和回调函数放到事件循环(任务队列)中;
事件循环会不断的从任务队列中取出对应的事件(回调函数)来执行;
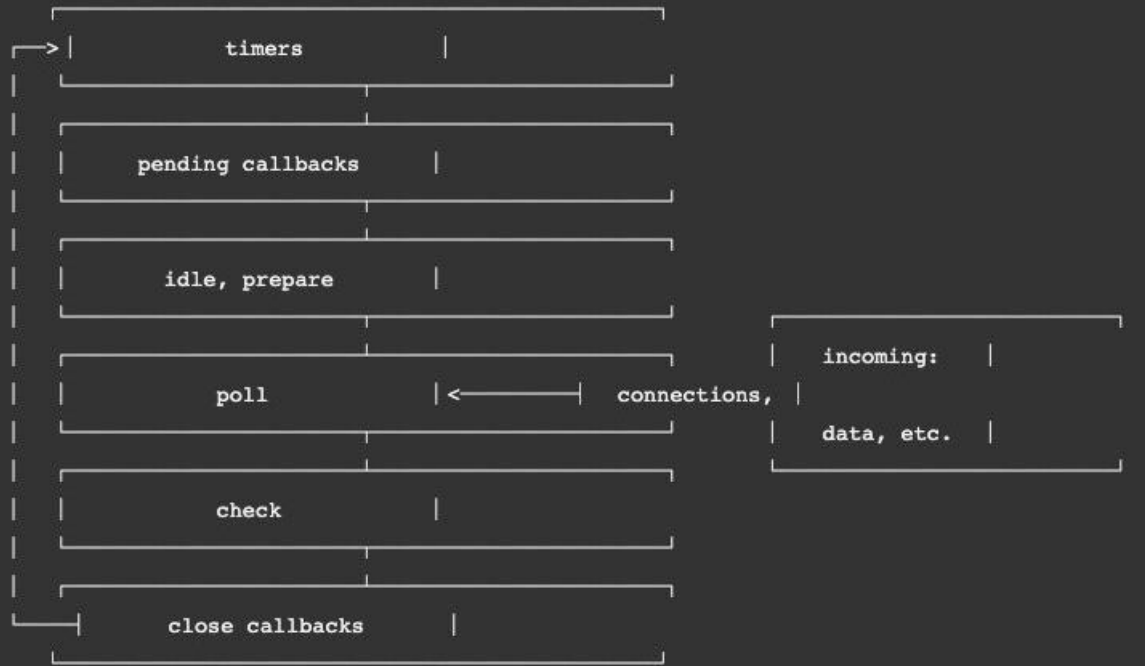
但是一次完整的事件循环Tick分成很多个阶段:
定时器(Timers):本阶段执行已经被 setTimeout() 和 setInterval() 的调度回调函数。
待定回调(Pending Callback):对某些系统操作(如TCP错误类型)执行回调,比如TCP连接时接收到ECONNREFUSED。
idle, prepare:仅系统内部使用。
轮询(Poll):检索新的 I/O 事件;执行与 I/O 相关的回调;
检测(check):setImmediate() 回调函数在这里执行。
关闭的回调函数:一些关闭的回调函数,如:socket.on('close', ...)。
Node事件循环的阶段图解
Node的宏任务和微任务
我们会发现从一次事件循环的Tick来说,Node的事件循环更复杂,它也分为微任务和宏任务:
宏任务(macrotask):setTimeout、setInterval、IO事件、setImmediate、close事件;
微任务(microtask):Promise的then回调、process.nextTick、queueMicrotask;
但是,Node中的事件循环不只是 微任务队列和 宏任务队列:
微任务队列:
- next tick queue:process.nextTick;
- other queue:Promise的then回调、queueMicrotask;
宏任务队列:
- timer queue:setTimeout、setInterval;
- poll queue:IO事件;
- check queue:setImmediate;
- close queue:close事件;
Node事件循环的顺序
所以,在每一次事件循环的tick中,会按照如下顺序来执行代码:
next tick microtask queue;
other microtask queue;
timer queue;
poll queue;
check queue;
close queue;
Node执行面试题
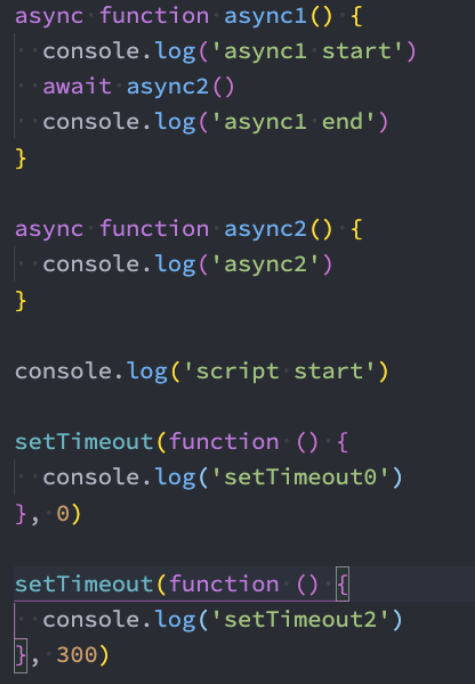
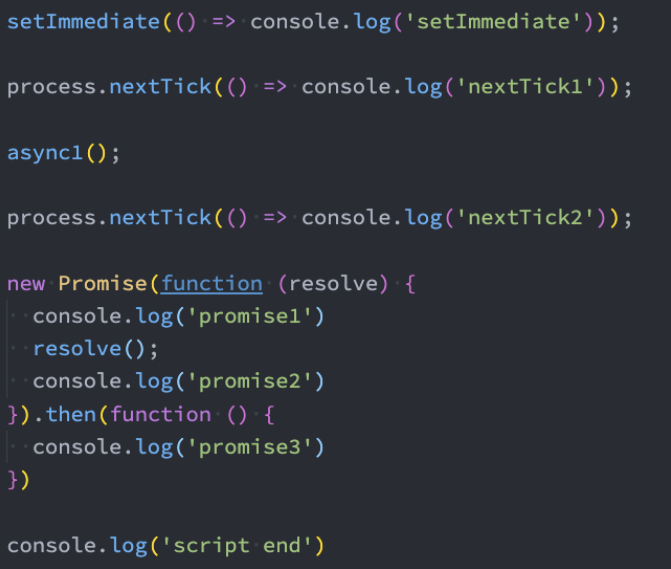
throw、try catch
错误处理方案
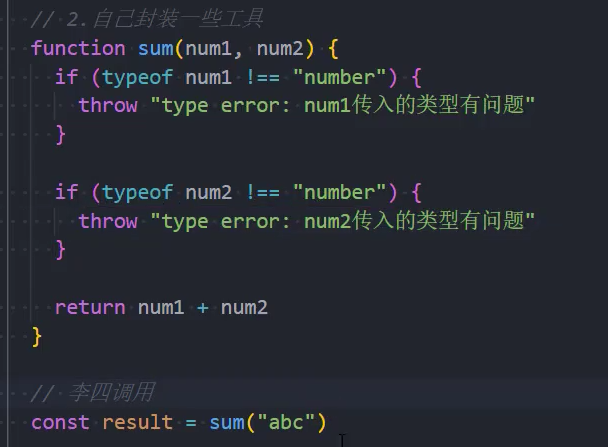
开发中我们会封装一些工具函数,封装之后给别人使用:
在其他人使用的过程中,可能会传递一些参数;
对于函数来说,需要对这些参数进行验证,否则可能得到的是我们不想要的结果;
很多时候我们可能验证到不是希望得到的参数时,就会直接return:
但是return存在很大的弊端:调用者不知道是因为函数内部没有正常执行,还是执行结果就是一个undefined;
事实上,正确的做法应该是如果没有通过某些验证,那么应该让外界知道函数内部报错了;
如何可以让一个函数告知外界自己内部出现了错误呢?
- 通过throw关键字,抛出一个异常;
throw语句:
throw语句用于抛出一个用户自定义的异常;
当遇到throw语句时,当前的函数执行会被停止(throw后面的语句不会执行);
如果我们执行代码,就会报错,拿到错误信息的时候我们可以及时的去修正代码。

throw关键字
throw表达式就是在throw后面可以跟上一个表达式来表示具体的异常信息:

throw关键字可以跟上哪些类型呢?
基本数据类型:比如number、string、Boolean
对象类型:对象类型可以包含更多的信息
但是每次写这么长的对象又有点麻烦,所以我们可以创建一个类:
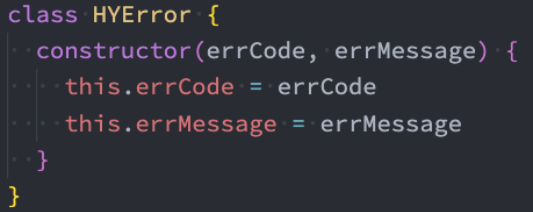
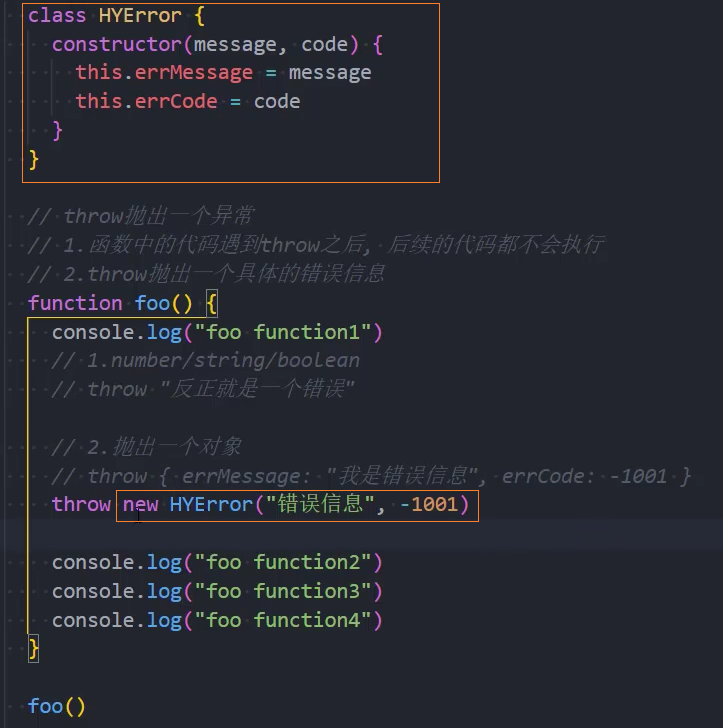
Error类型
事实上,JavaScript已经给我们提供了一个Error类,我们可以直接创建这个类的对象:

Error包含三个属性:
messsage:创建Error对象时传入的message;
name:Error的名称,通常和类的名称一致;
stack:整个Error的错误信息,包括函数的调用栈,当我们直接打印Error对象时,打印的就是stack;
Error有一些自己的子类:**
RangeError:下标值越界时使用的错误类型;
SyntaxError:解析语法错误时使用的错误类型;
TypeError:出现类型错误时,使用的错误类型;
异常的处理
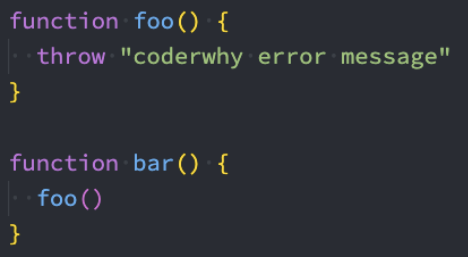
我们会发现在之前的代码中,一个函数抛出了异常,调用它的时候程序会被强制终止:
这是因为如果我们在调用一个函数时,这个函数抛出了异常,但是我们并没有对这个异常进行处理,那么这个异常会继续传递到上一个函数调用中;
而如果到了最顶层(全局)的代码中依然没有对这个异常的处理代码,这个时候就会报错并且终止程序的运行;
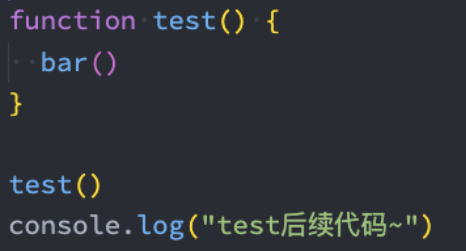
我们先来看一下这段代码的异常传递过程:
foo函数在被执行时会抛出异常,也就是我们的bar函数会拿到这个异常;
但是bar函数并没有对这个异常进行处理,那么这个异常就会被继续传递到调用bar函数的函数,也就是test函数;
但是test函数依然没有处理,就会继续传递到我们的全局代码逻辑中;
依然没有被处理,这个时候程序会终止执行,后续代码都不会再执行了;
异常的捕获
但是很多情况下当出现异常时,我们并不希望程序直接退出,而是希望可以正确的处理异常:
- 这个时候我们就可以使用try catch


在ES10(ES2019)中,catch后面绑定的error可以省略。
当然,如果有一些必须要执行的代码,我们可以使用finally来执行:
- finally表示最终一定会被执行的代码结构;
注意:如果try和finally中都有返回值,那么会使用finally当中的返回值;
Storage
认识Storage
WebStorage主要提供了一种机制,可以让浏览器提供一种比cookie更直观的key、value存储方式:
localStorage:本地存储,提供的是一种永久性的存储方法,在关闭掉网页重新打开时,存储的内容依然保留;
sessionStorage:会话存储,提供的是本次会话的存储,在关闭掉会话时,存储的内容会被清除;

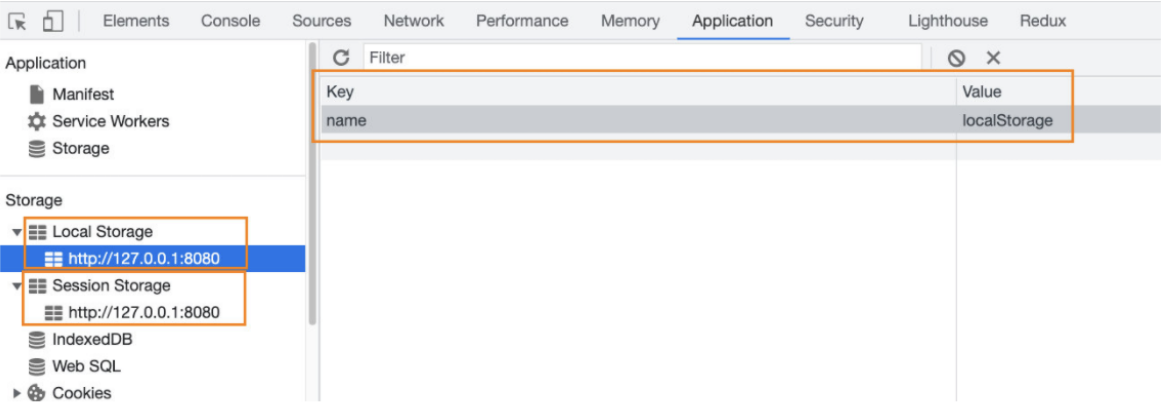
localStorage和sessionStorage的区别
我们会发现localStorage和sessionStorage看起来非常的相似。
那么它们有什么区别呢?
验证一:关闭网页后重新打开,localStorage会保留,而sessionStorage会被删除;
验证二:在页面内实现跳转,localStorage会保留,sessionStorage也会保留;
验证三:在页面外实现跳转(打开新的网页),localStorage会保留,sessionStorage不会被保留;
Storage常见的方法和属性
Storage有如下的属性和方法:
属性:
- Storage.length:只读属性
- 返回一个整数,表示存储在Storage对象中的数据项数量;
方法:
Storage.key(index):该方法接受一个数值n作为参数,返回存储中的第n个key名称;
Storage.getItem(key):该方法接受一个key作为参数,并且返回key对应的value;
Storage.setItem(key, value):该方法接受一个key和value,并且将会把key和value添加到存储中。
- 如果key已经存在,则更新其对应的值;
Storage.removeItem(key):该方法接受一个key作为参数,并把该key从存储中删除;
Storage.clear():该方法的作用是清空存储中的所有key;
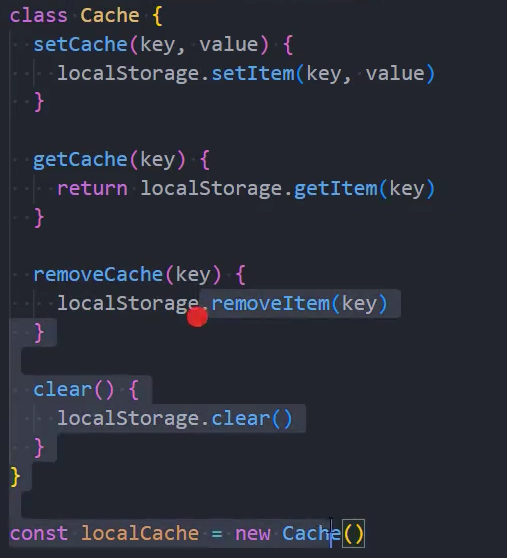
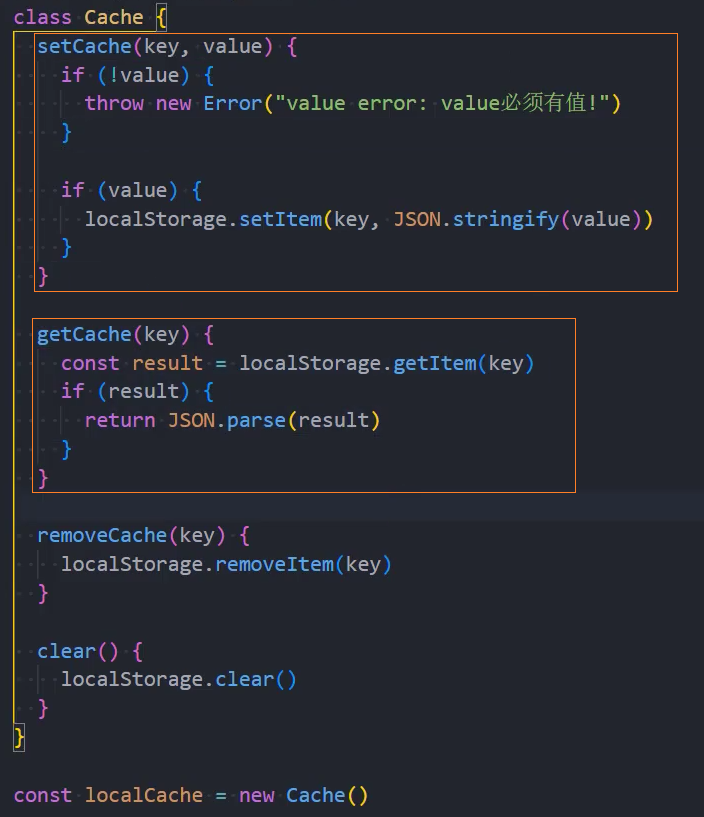
封装-Cache
基础封装
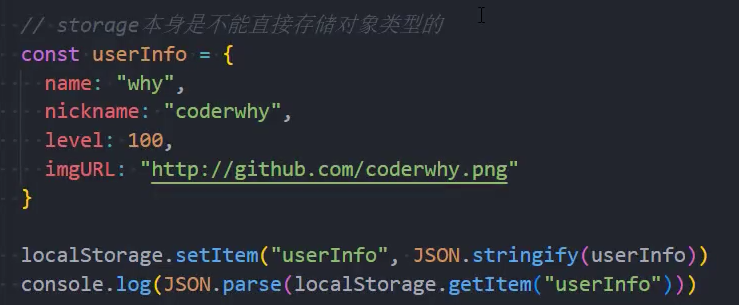
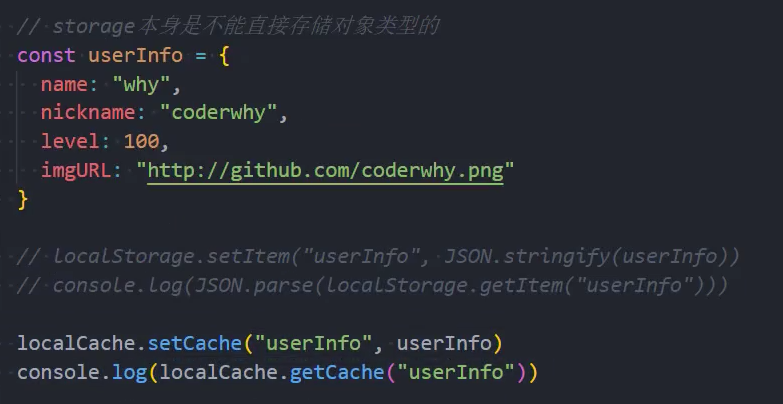
优化:存储对象类型
原生方法
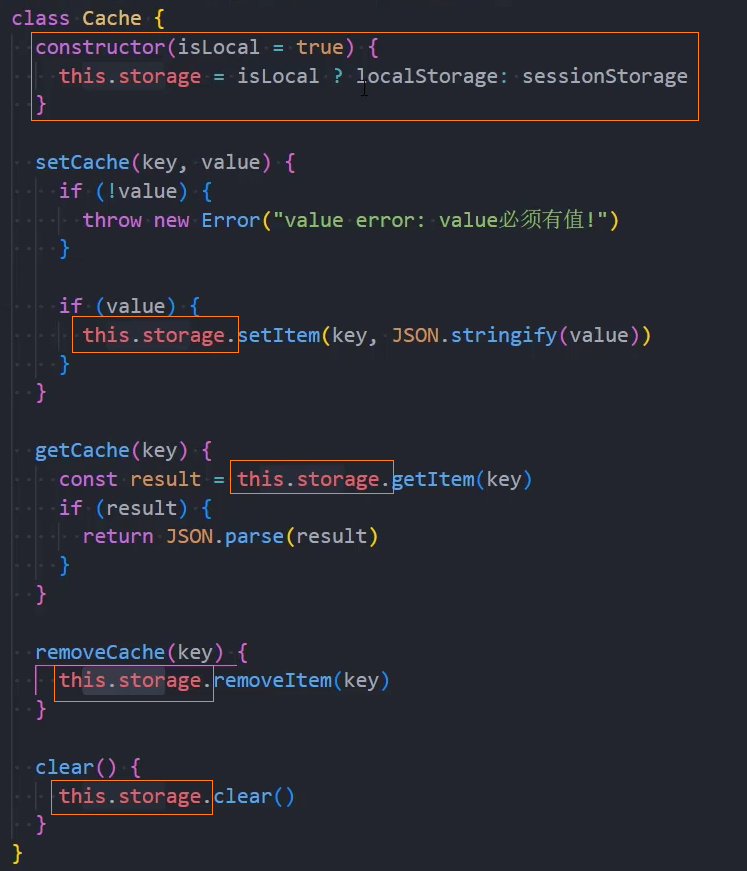
▸优化:兼容local和session

正则表达式
什么是正则表达式?
我们先来看一下维基百科对正则表达式的解释:
正则表达式(英语:Regular Expression,常简写为regex、regexp或RE),又称正则表示式、正则表示法、规则表达式、常规表示法,是计算机科学的一个概念;
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串**。**
许多程序设计语言都支持利用正则表达式进行字符串操作。
简单概况:正则表达式是一种字符串匹配利器,可以帮助我们搜索、获取、替代字符串;
在JavaScript中,正则表达式使用RegExp类来创建,也有对应的字面量的方式:
- 正则表达式主要由两部分组成:模式(patterns)和修饰符(flags)

正则表达式使用方法
有了正则表达式我们要如何使用它呢?
JavaScript中的正则表达式被用于 RegExp的 exec 和 test 方法;
也包括 String 的 match、matchAll、replace、search 和 split 方法;

正则常用方法
- RegExp
- RegExp.prototype.exec():
返回:array, - RegExp.prototype.test(str):
返回:boolean,检测某个字符串是否符合正则的规则 - String
- String.prototype.match():
返回:, - String.prototype.matchAll():
返回:, - String.prototype.search():
返回:, - String.prototype.replace():
返回:, - String.prototype.split():
返回:,
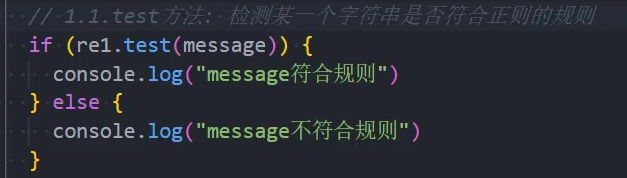
示例: test

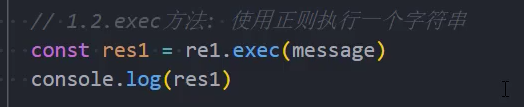
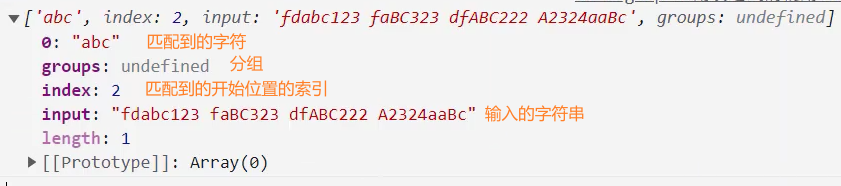
示例: exec
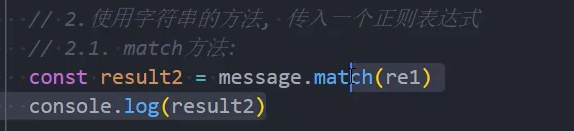
示例: match
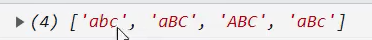
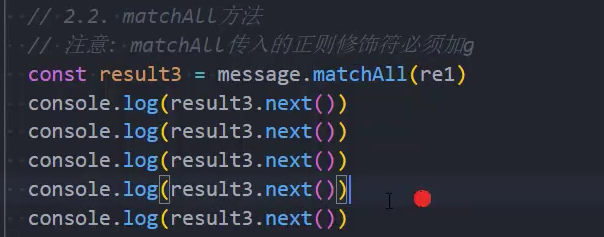
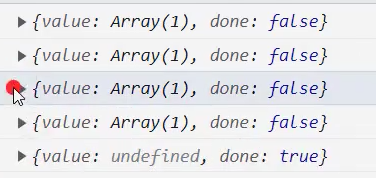
示例: matchAll
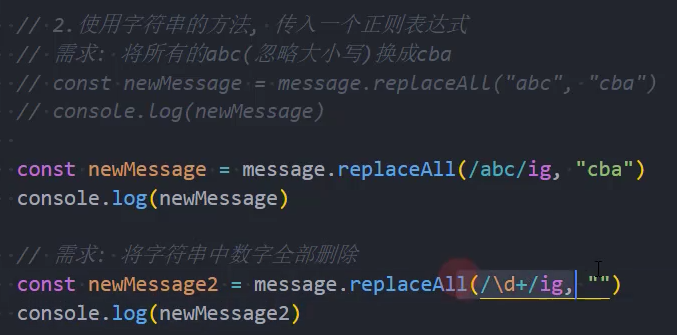
示例: replace / replaceAll
示例: split
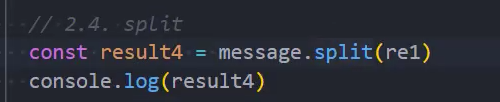

示例: search


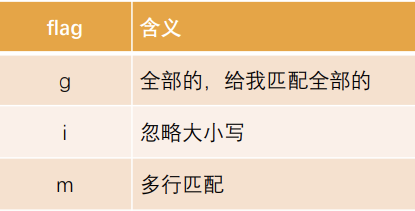
修饰符
常见的修饰符:
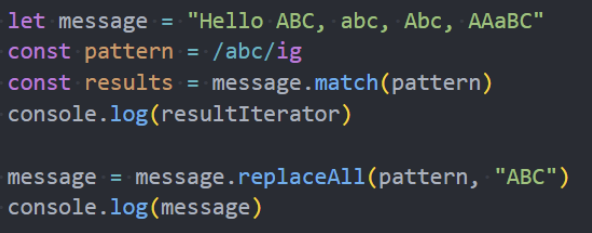
需求:
获取一个字符串中所有的abc;
将一个字符串中的所有abc换成大写;
规则
字符类
字符类(Character classes) 是一个特殊的符号,匹配特定集中的任何符号。
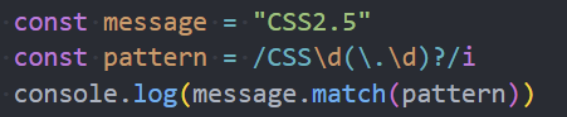
\d:,匹配任何数字 (阿拉伯数字)。相当于[0-9]。\s:,匹配单个空白字符,包括空格、制表符、换页符、换行符和其他 Unicode 空格。相当于[\f\n\r\t\v]。\w:,匹配基本拉丁字母中的任何字母数字字符,包括下划线。相当于[A-Za-z0-9_]。.:,匹配除行终止符之外的任何单个字符:\n,\r\D:,匹配任何非数字 (阿拉伯数字) 的字符。相当于[^0-9]。\S:,匹配除空格以外的单个字符。相当于[^\f\n\r\t\v]。\W:,匹配任何不是来自基本拉丁字母的单词字符。相当于[^A-Za-z0-9_]。\t:,匹配水平制表符。\r:,匹配回车符。\n:,匹配换行符。\:,指示应特殊处理或“转义”后面的字符。
断言
边界类断言
^:,匹配输入的开头。如果多行模式设为 true,^在换行符后也能立即匹配,$:,匹配输入的结束。如果多行模式设为 true,$在换行符前也能立即匹配,\b:,匹配一个单词的边界\B:,匹配非单词边界。
其他断言
x(?=y):,先行断言: x 被 y 跟随时匹配 x。x(?!y):,先行否定断言: x 没有被 y 紧随时匹配 x。(?<=y)x:,后行断言: x 跟随 y 的情况下匹配 x。(?<!y)x:,后行否定断言: x 不跟随 y 时匹配 x。
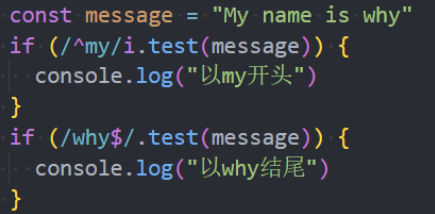
符号 ^ 和符号 $ 在正则表达式中具有特殊的意义,它们被称为“锚点”。
符号 ^ 匹配文本开头;
符号 $ 匹配文本末尾;
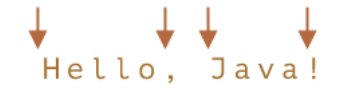
词边界(Word boundary)
词边界 \b 是一种检查,就像 ^ 和 $ 一样,它会检查字符串中的位置是否是词边界。
词边界测试 \b 检查位置的一侧是否匹配 \w,而另一侧则不匹配 “\w”
在字符串 Hello, Java! 中,以下位置对应于 \b:
匹配下面字符串中的时间:


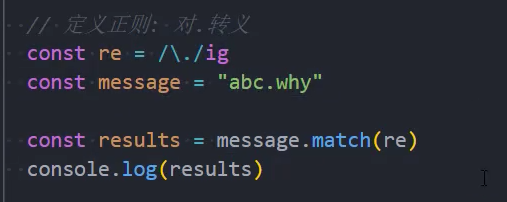
转义字符串
如果要把特殊字符作为常规字符来使用,需要对其进行转义:
- 只需要在它前面加个反斜杠;
常见的需要转义的字符:

- 斜杠符号
/并不是一个特殊符号,但是在字面量正则表达式中也需要转义;
示例: 匹配所有以.js或者.jsx结尾的文件名

在webpack当中,匹配文件名时就是以这样的方式。
示例: 只匹配.点

集合、范围
有时候我们只要选择多个匹配字符的其中之一就可以:
- 在方括号 […] 中的几个字符或者字符类意味着“搜索给定的字符中的任意一个”;
集合(Sets)
- 比如说,[eao] 意味着查找在 3 个字符 ‘a’、‘e’ 或者 ` ‘o’ 中的任意一个;
范围(Ranges)
方括号也可以包含字符范围;
比如说,[a-z] 会匹配从 a 到 z 范围内的字母,[0-5] 表示从 0 到 5 的数字;
[0-9A-F] 表示两个范围:它搜索一个字符,满足数字 0 到 9 或字母 A 到 F;
\d —— 和 [0-9] 相同;
\w —— 和 [a-zA-Z0-9_] 相同;
示例: 匹配手机号码

// 手机号
/^1[3-9]\d{9}$/排除范围:除了普通的范围匹配,还有类似[^…]的“排除”范围匹配;
量词
假设我们有一个字符串 +7(903)-123-45-67,并且想要找到它包含的所有数字。
因为它们的数量是不同的,所以我们需要给与数量一个范围;
用来形容我们所需要的数量的词被称为量词( Quantifiers )。
语法:
{m}: 确切的位数:{5}{m,n}: 某个范围的位数:{3,5}
注意: {m,n} 此处逗号后面不能加空格
缩写:
+:代表“一个或多个”,相当于{1,}?:代表“零个或一个”,相当于{0,1}。换句话说,它使得符号变得可选;\*:代表着“零个或多个”,相当于{0,}。也就是说,这个字符可以多次出现或不出现;
示例: 匹配开始或结束标签

贪婪模式、惰性模式
如果我们有这样一个需求:匹配下面字符串中所有使用《》包裹的内容


贪婪模式( Greedy)
默认情况下的匹配规则是查找到匹配的内容后,会继续向后查找,一直找到最后一个匹配的内容,这种匹配的方式,我们称之为贪婪模式(Greedy)
惰性模式( lazy)
懒惰模式中的量词与贪婪模式中的是相反的。
只要获取到对应的内容后,就不再继续向后匹配;
我们可以在量词后面再加一个问号 ‘?’ 来启用它;
所以匹配模式变为 *? 或 +?,甚至将 '?' 变为 ??

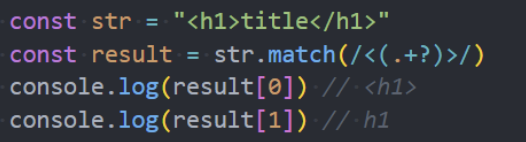
捕获组
模式的一部分可以用括号括起来 (...),这称为“捕获组(capturing group)”。
作用:
它允许将匹配的一部分作为结果数组中的单独项;
它将括号视为一个整体;
方法 str.match(regexp),如果 regexp没有 g 标志,将查找第一个匹配并将它作为一个数组返回:
在索引 0 处:完全匹配。
在索引 1 处:第一个括号的内容。
在索引 2 处:第二个括号的内容。
…等等…
示例: 匹配到HTML标签,并且获取其中的内容
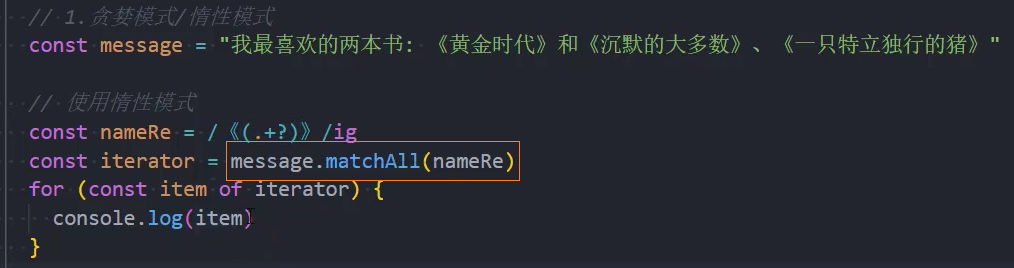

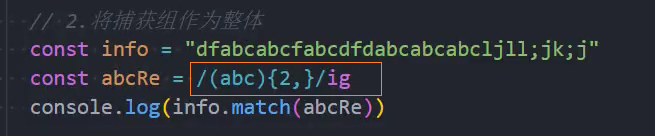
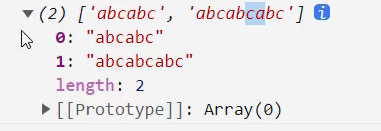
示例: 将捕获组作为整体
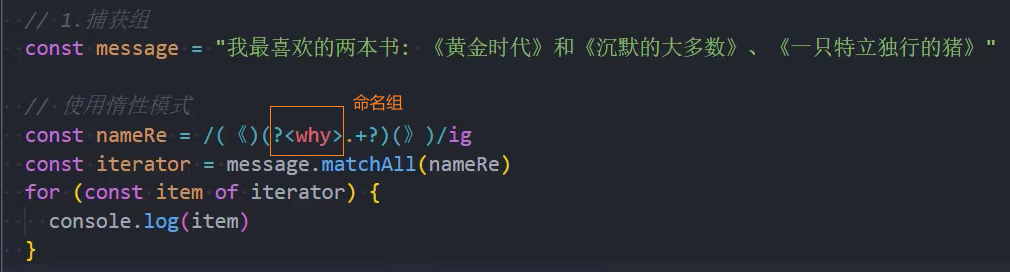
命名组:
用数字记录组很困难。
对于更复杂的模式,计算括号很不方便。我们有一个更好的选择:给括号起个名字。
这是通过在开始括号之后立即放置
?<name>来完成的。如(?<name>xxx)

非捕获组:
有时我们需要括号才能正确应用量词,但我们不希望它们的内容出现在结果中。
可以通过在开头添加
?:来排除组。如(?:xxx)

or:
or是正则表达式中的一个术语,实际上是一个简单的“或”。
在正则表达式中,它用竖线
|表示;通常会和捕获组一起来使用,在其中表示多个值;


or和集合的区别
- or可以给多个字符分类:
(abc|cba|nba)表示abc或cba或nba - 集合只能给单个字符分类:
[abc]表示a或b或c
案例练习-歌词解析
歌词解析:http://123.207.32.32:9002/lyric?id=167876

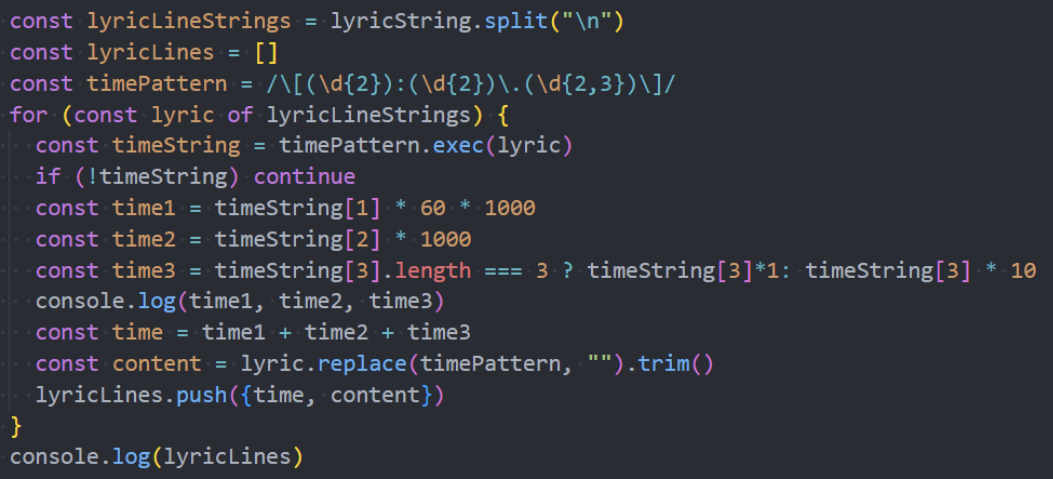
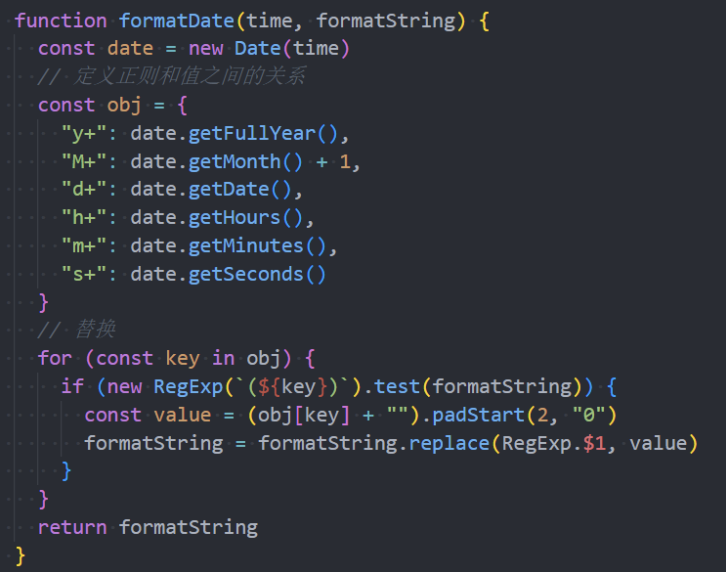
案例练习-时间格式化
时间格式化:从服务器拿到时间戳,转成想要的时间格式

**更多正则查询:**https://c.runoob.com/front-end/854/
防抖、节流
简介
防抖和节流的概念其实最早并不是出现在软件工程中,防抖是出现在电子元件中,节流出现在流体流动中
而JavaScript是事件驱动的,大量的操作会触发事件,加入到事件队列中处理。
而对于某些频繁的事件处理会造成性能的损耗,我们就可以通过防抖和节流来限制事件频繁的发生;
防抖和节流函数目前已经是前端实际开发中两个非常重要的函数,也是面试经常被问到的面试题。
但是很多前端开发者面对这两个功能,有点摸不着头脑:
某些开发者根本无法区分防抖和节流有什么区别(面试经常会被问到);
某些开发者可以区分,但是不知道如何应用;
某些开发者会通过一些第三方库来使用,但是不知道内部原理,更不会编写;
接下来我们会一起来学习防抖和节流函数:
我们不仅仅要区分清楚防抖和节流两者的区别,也要明白在实际工作中哪些场景会用到;
并且我会带着大家一点点来编写一个自己的防抖和节流的函数,不仅理解原理,也学会自己来编写;
防抖函数
防抖函数(debounce)
我们用一副图来理解一下它的过程:
当事件触发时,相应的函数并不会立即触发,而是会等待一定的时间;
当事件密集触发时,函数的触发会被频繁的推迟;
只有等待了一段时间也没有事件触发,才会真正的执行响应函数;
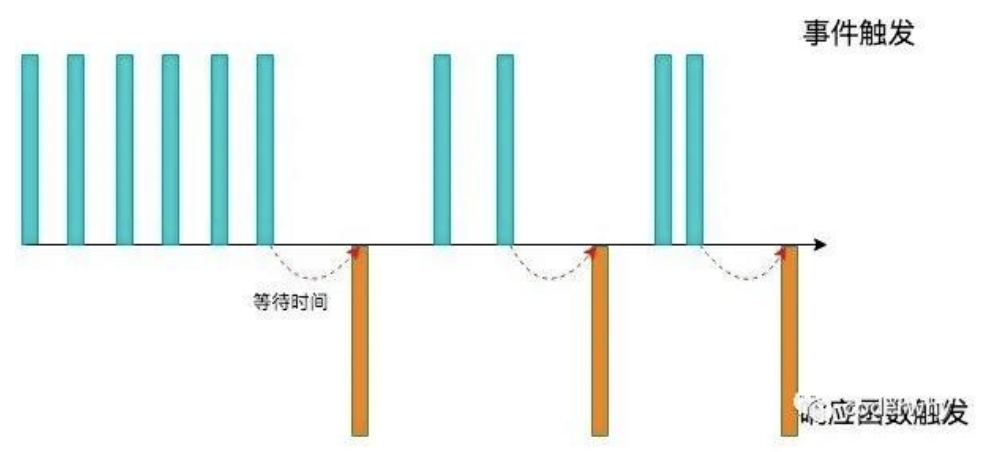
应用场景:
防抖的应用场景很多:
搜索联想:
oninput,输入框中频繁的输入内容,搜索或者提交信息;频繁点击事件:
onclick,频繁的点击按钮,触发某个事件;浏览器滚动事件:
onscroll,监听浏览器滚动事件,完成某些特定操作;浏览器缩放事件:
onresize,用户缩放浏览器的resize事件;
示例: 搜索联想
我们都遇到过这样的场景,在某个搜索框中输入自己想要搜索的内容:
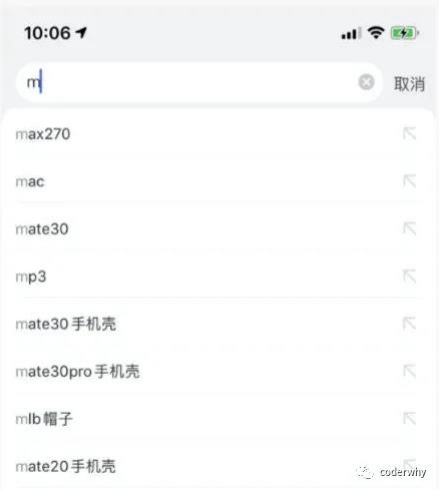
比如想要搜索一个MacBook:
当我输入m时,为了更好的用户体验,通常会出现对应的联想内容,这些联想内容通常是保存在服务器的,所以需要一次网络请求;
当继续输入ma时,再次发送网络请求;
那么macbook一共需要发送7次网络请求;
这大大损耗我们整个系统的性能,无论是前端的事件处理,还是对于服务器的压力;
但是我们需要这么多次的网络请求吗?
不需要,正确的做法应该是在合适的情况下再发送网络请求;
比如如果用户快速的输入一个macbook,那么只是发送一次网络请求;
比如如果用户是输入一个m想了一会儿,这个时候m确实应该发送一次网络请求;
也就是我们应该监听用户在某个时间,比如500ms内,没有再次触发时间时,再发送网络请求;
这就是防抖的操作:只有在某个时间内,没有再次触发某个函数时,才真正的调用这个函数;
节流函数
节流函数(throttle)
我们用一副图来理解一下节流的过程
当事件触发时,会执行这个事件的响应函数;
如果这个事件会被频繁触发,那么节流函数会按照一定的频率来执行函数;
不管在这个中间有多少次触发这个事件,执行函数的频率总是固定的;
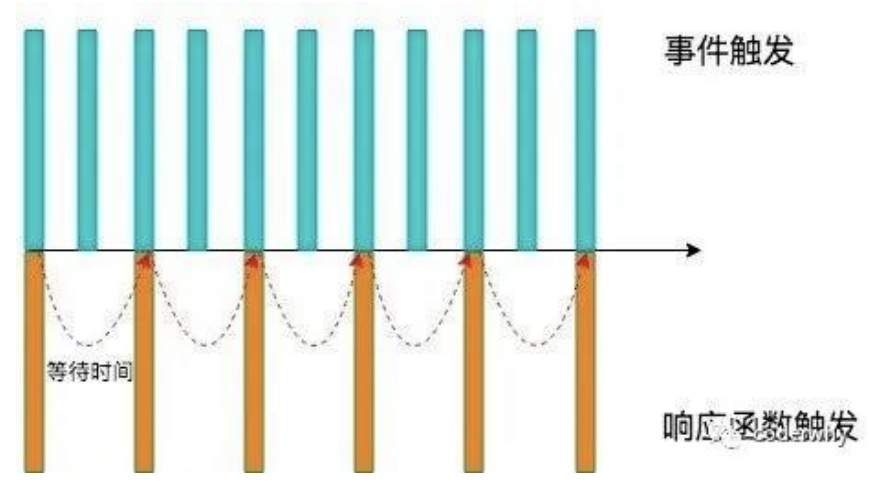
应用场景:
页面滚动事件:监听页面的滚动事件;
鼠标移动事件;
频繁点击事件:用户频繁点击按钮操作;
游戏某些设计:游戏中的一些设计,如发射子弹;
很多人都玩过类似于飞机大战的游戏
在飞机大战的游戏中,我们按下空格会发射一个子弹:
很多飞机大战的游戏中会有这样的设定,即使按下的频率非常快,子弹也会保持一定的频率来发射;
比如1秒钟只能发射一次,即使用户在这1秒钟按下了10次,子弹会保持发射一颗的频率来发射;
但是事件是触发了10次的,响应的函数只触发了一次;

生活中的例子
生活中防抖的例子:
比如说有一天我上完课,我说大家有什么问题来问我,我会等待五分钟的时间。
如果在五分钟的时间内,没有同学问我问题,那么我就下课了;
在此期间,a同学过来问问题,并且帮他解答,解答完后,我会再次等待五分钟的时间看有没有其他同学问问题;
如果我等待超过了5分钟,就点击了下课(才真正执行这个时间);
生活中节流的例子:
比如说有一天我上完课,我说大家有什么问题来问我,但是在一个5分钟之内,不管有多少同学来问问题,我只会解答一个问题;
如果在解答完一个问题后,5分钟之后还没有同学问问题,那么就下课;
案例准备
我们通过一个搜索框来延迟防抖函数的实现过程:
- 监听input的输入,通过打印模拟网络请求
测试发现快速输入一个macbook共发送了7次请求,显示我们需要对它进行防抖操作:
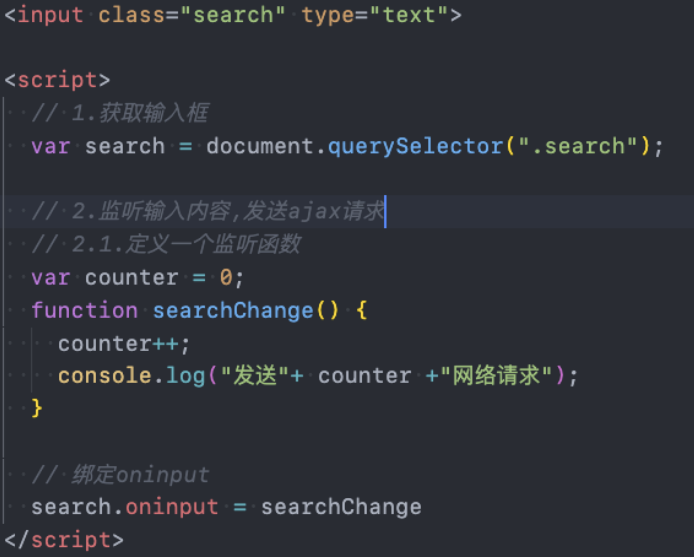

underscore
Underscore库的介绍
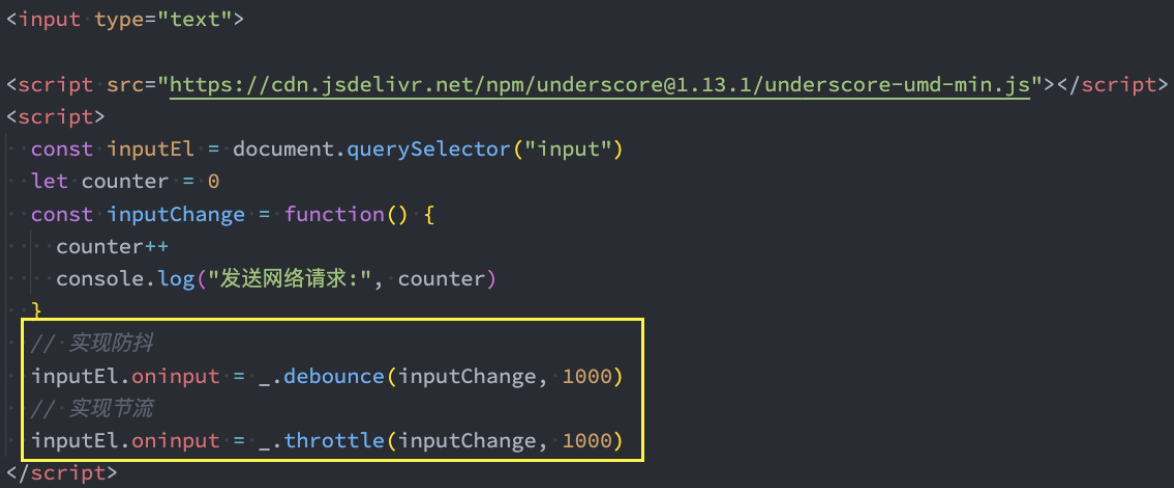
事实上我们可以通过一些第三方库来实现防抖操作:
lodash
underscore
这里使用underscore
我们可以理解成lodash是underscore的升级版,它更重量级,功能也更多;
但是目前我看到underscore还在维护,lodash已经很久没有更新了;
Underscore的官网: https://underscorejs.org/
安装:
Underscore的安装有很多种方式:
下载Underscore,本地引入;
通过CDN直接引入;
通过包管理工具(npm)管理安装;
这里我们直接通过CDN:
<script src="https://cdn.jsdelivr.net/npm/underscore@1.13.1/underscore-umd-min.js"></script>Underscore实现防抖和节流
手写题
手写-防抖函数
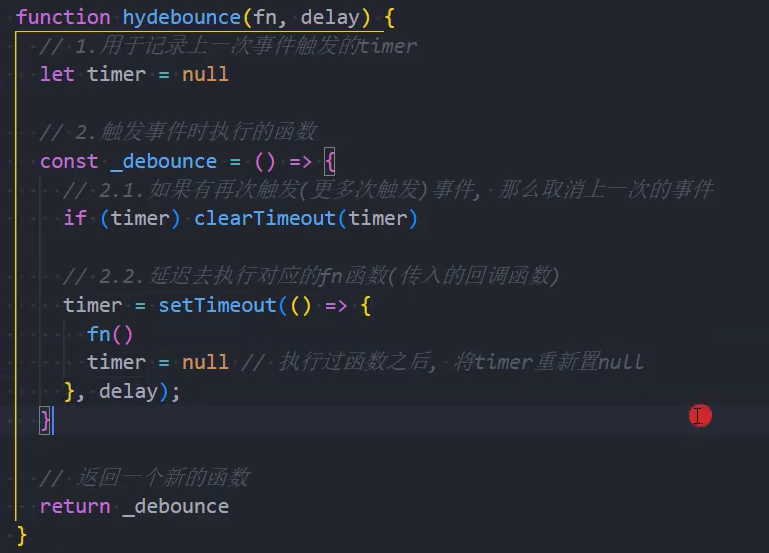
我们按照如下思路来实现:
- 防抖基本功能实现:可以实现防抖效果
- 优化一:优化参数和this指向
- 优化二:优化取消操作(增加取消功能)
- 优化三:优化立即执行效果(第一次立即执行)
- 优化四:优化返回值
1、基本实现
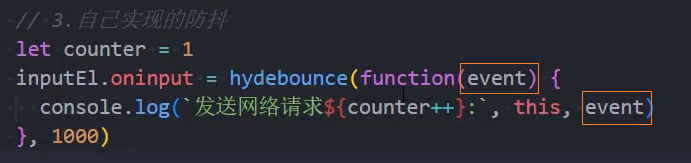
2、优化:参数和this绑定
this指向
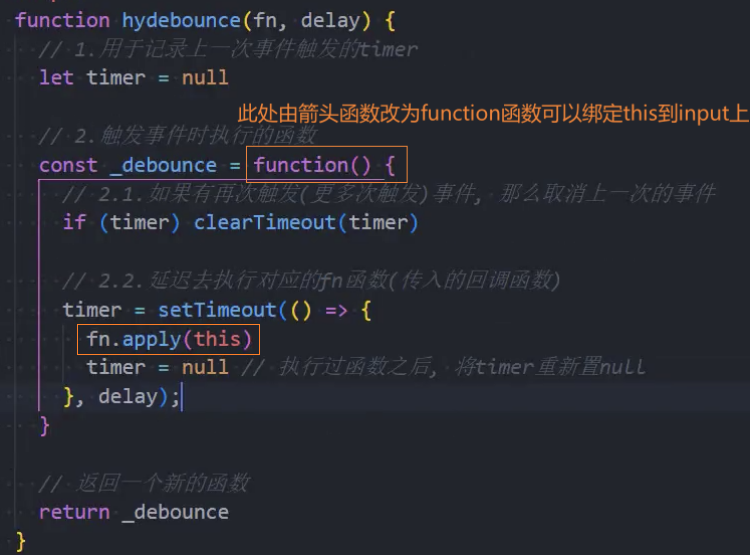
参数
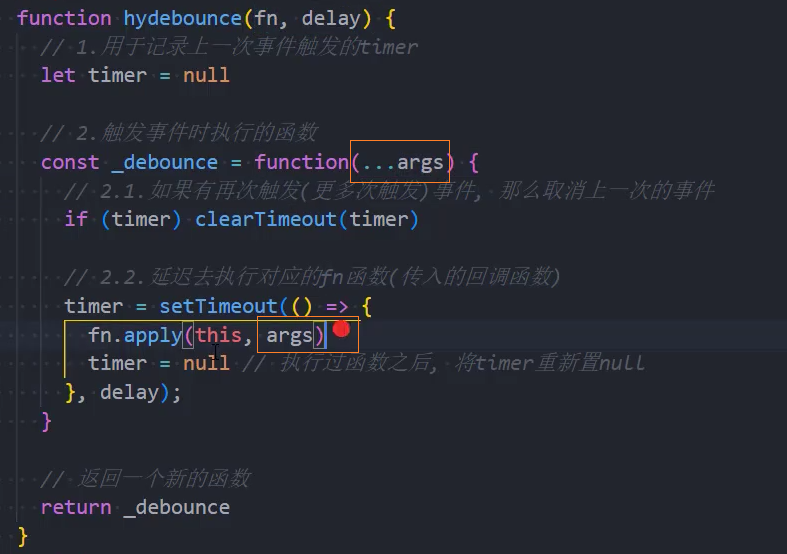
3、优化:取消功能
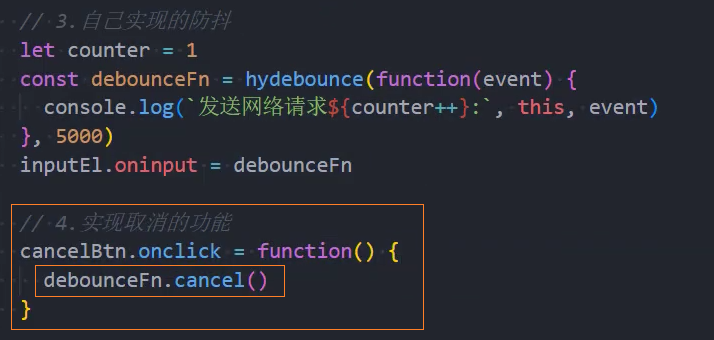
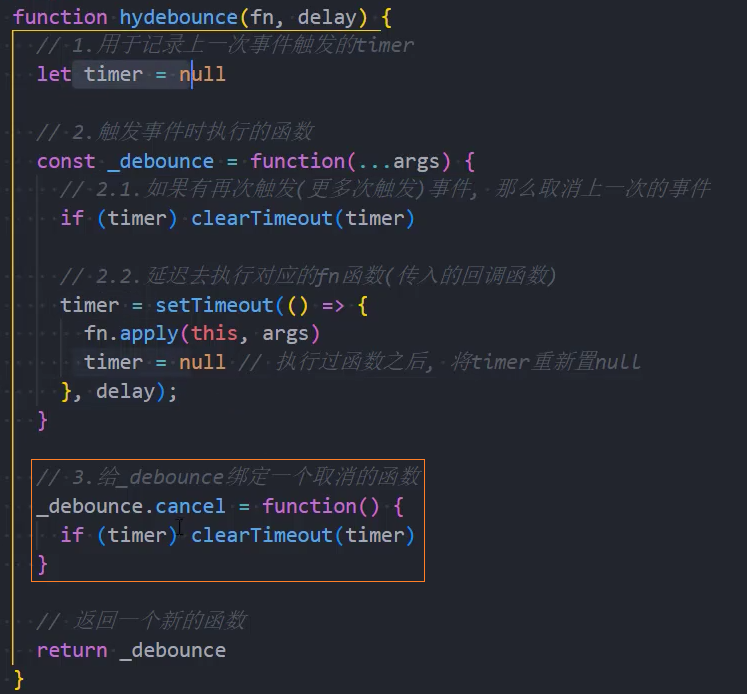
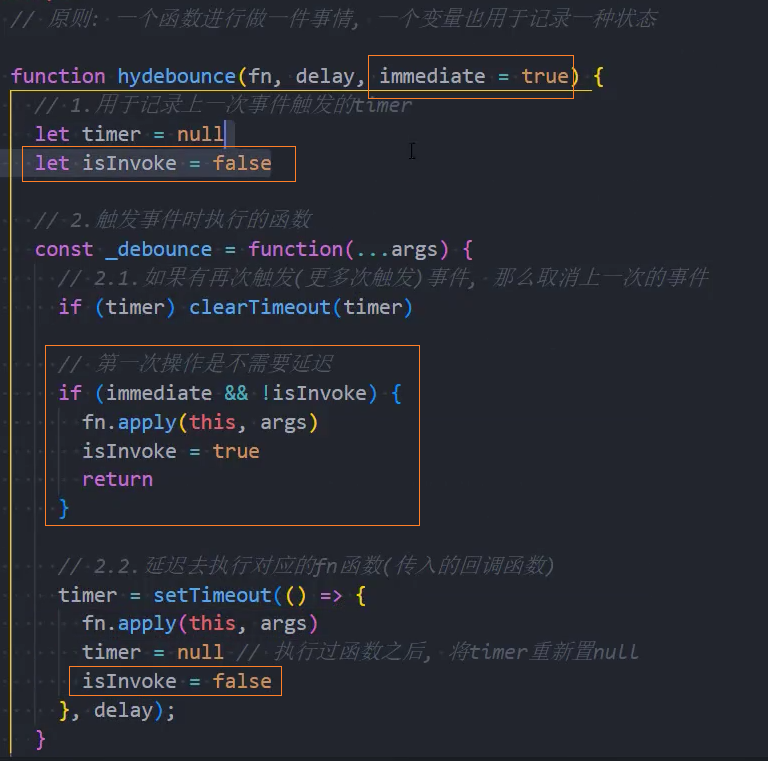
4、优化:第一次立即执行
immediate:控制否时启用立即执行功能isInvoke:控制函数是否已经立即执行一次了
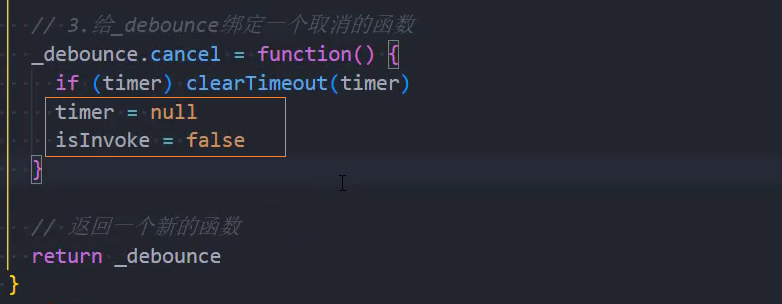
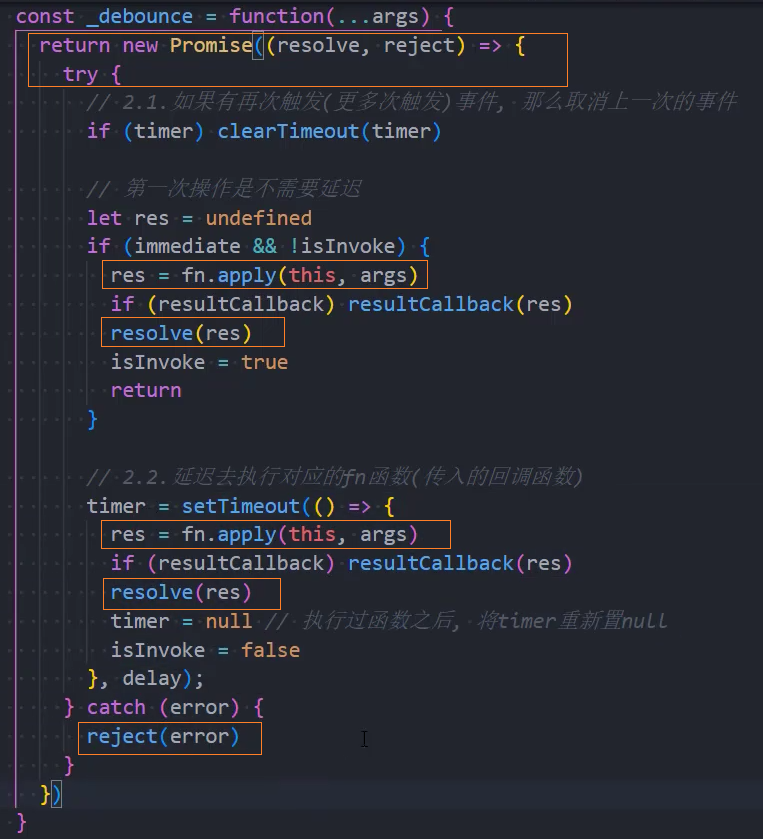
5、优化:返回值
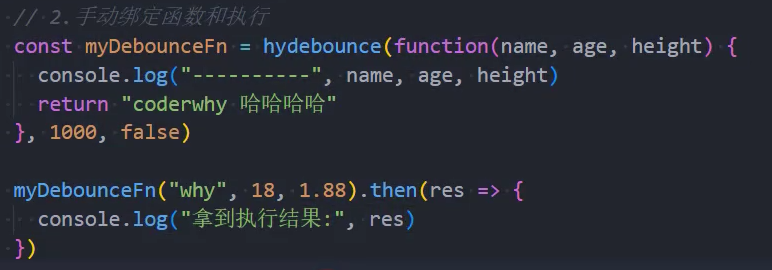
手写-节流函数
我们按照如下思路来实现:
- 节流函数的基本实现:可以实现节流效果
- 优化一:绑定this和参数
- 优化二:控制立即执行,节流最后一次也可以执行
- 优化三:优化添加取消功能
- 优化四:优化返回值问题
1、基本实现
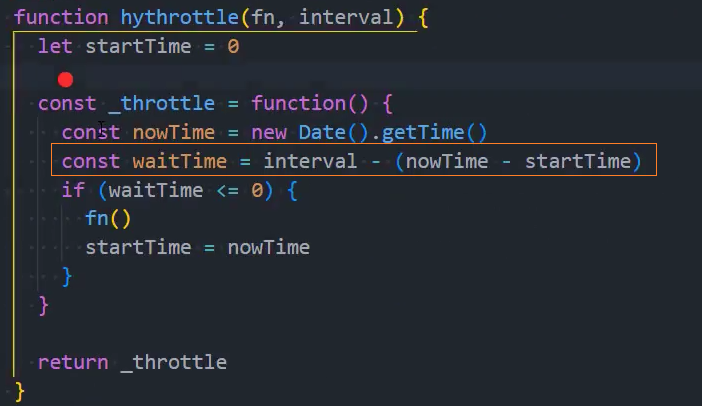
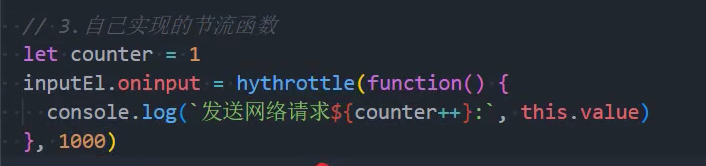
2、优化:绑定this和参数
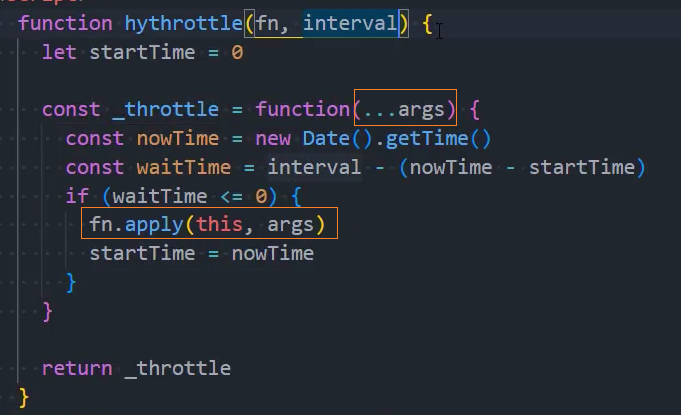
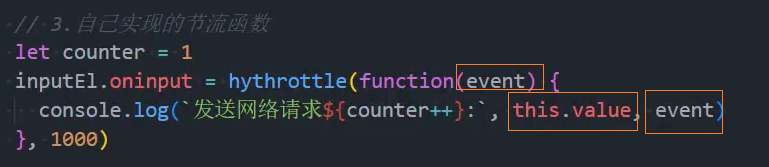
3、优化:控制立即执行
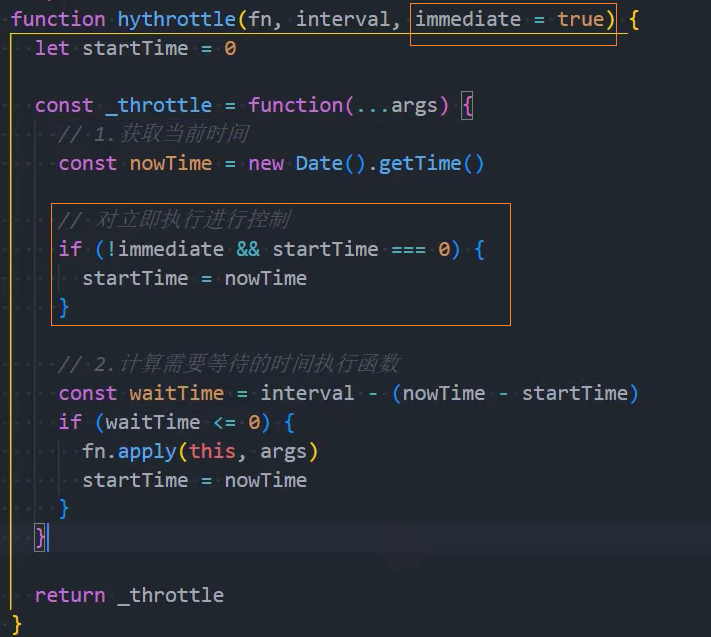
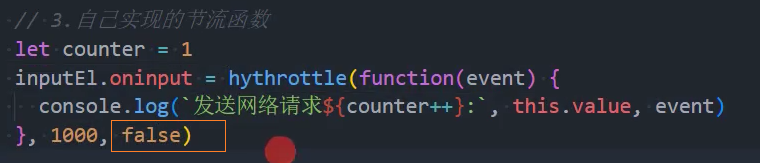
4、优化:控制执行最后一次
思路一: 给每次点击时添加一个定时器,延迟时间设为waitTime,当再次点击时取消上次的定时器,重新添加一个。
思路二: 在每个执行fn函数的节点,添加一个延迟时间为waitTime的定时器,当用户在fn函数执行节点的时间上也点击了一次就取消该定时器(使用中)
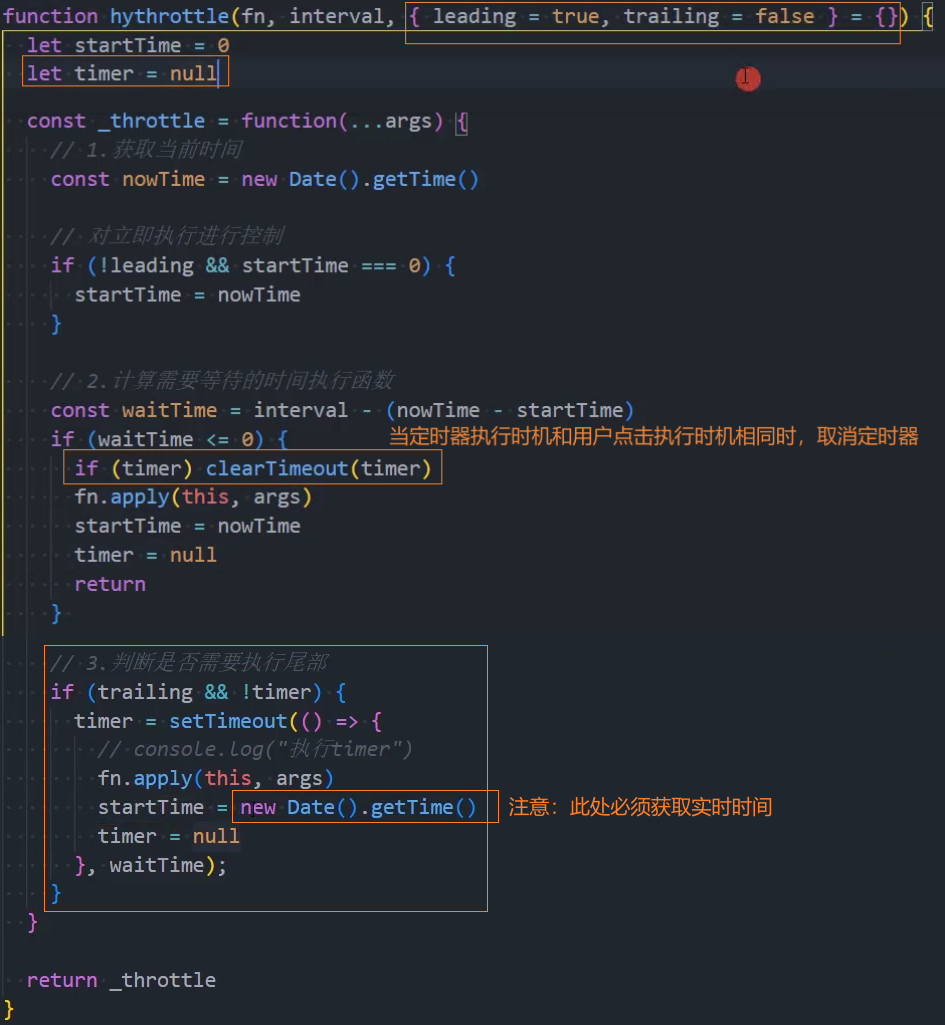
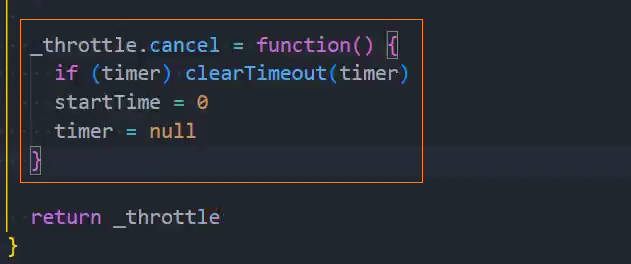
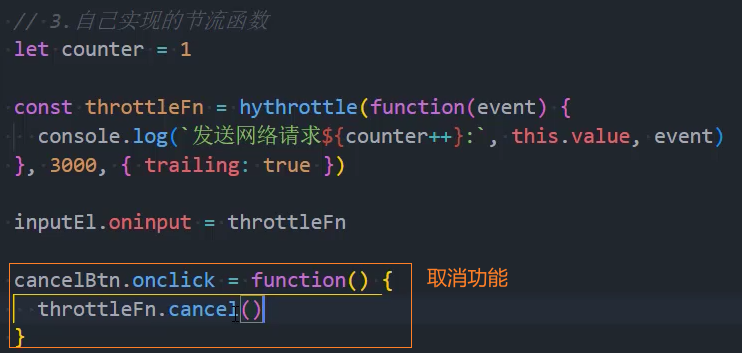
4、优化:取消功能
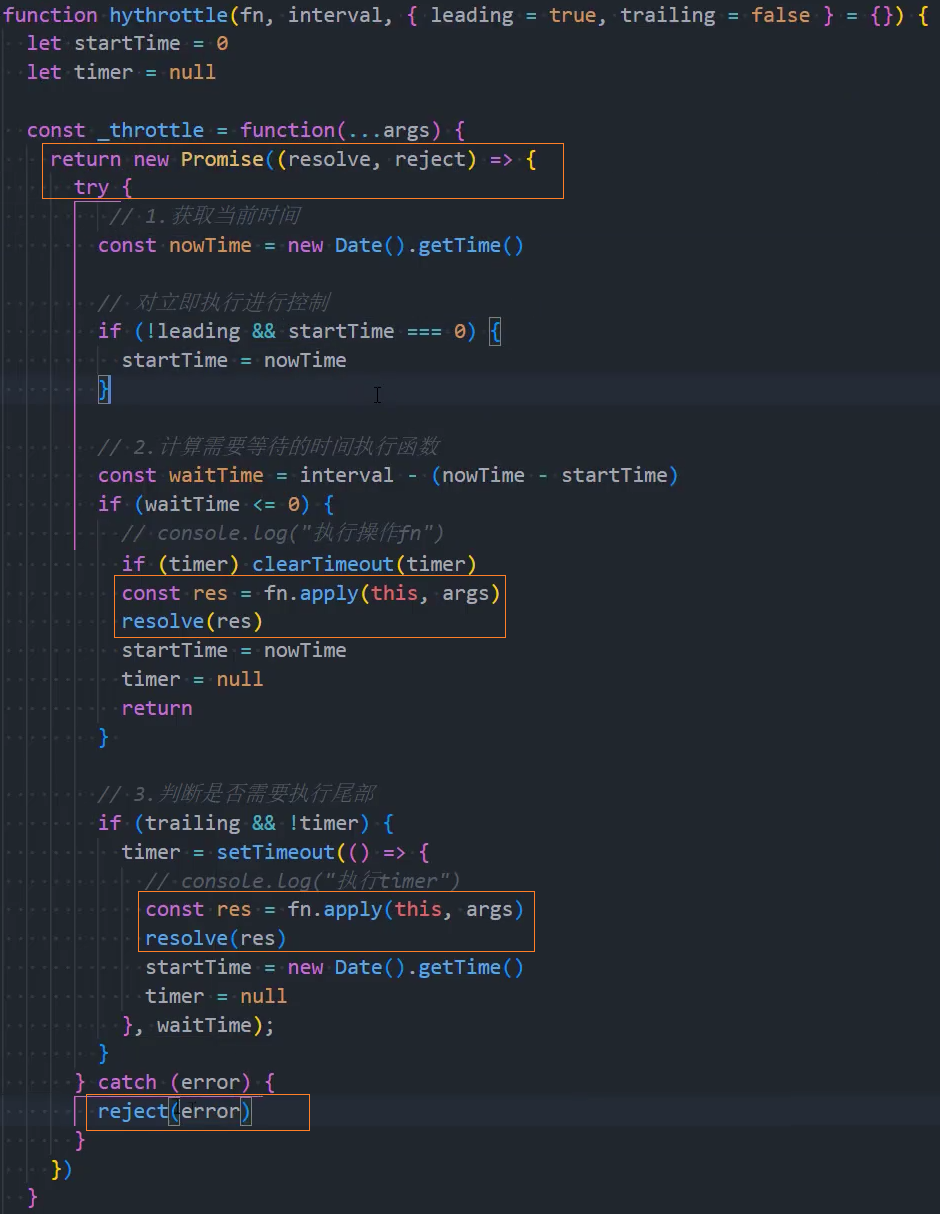
5、优化:返回值
手写-深拷贝函数
前面我们已经学习了对象相互赋值的一些关系,分别包括:
引用赋值:指向同一个对象,相互之间会影响;
对象的浅拷贝:只是浅层的拷贝,内部引入对象时,依然会相互影响;
对象的深拷贝:两个对象不再有任何关系,不会相互影响;
深拷贝实现方式:
- JSON.parse
- 第三方库:underscore、lodash
- 自己实现
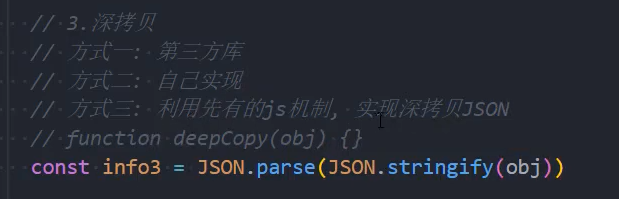
前面我们已经可以通过一种方法来实现深拷贝了:JSON.parse
这种深拷贝的方式其实对于函数、Symbol等是无法处理的;
并且如果存在对象的循环引用,也会报错的;
const obj = JSON.parse(JSON.stringify(info))自定义深拷贝函数:
1.自定义深拷贝的基本功能;
2.对Symbol的key进行处理;
3.其他数据类型的值进程处理:数组、函数、Symbol、Set、Map;
4.对循环引用的处理;
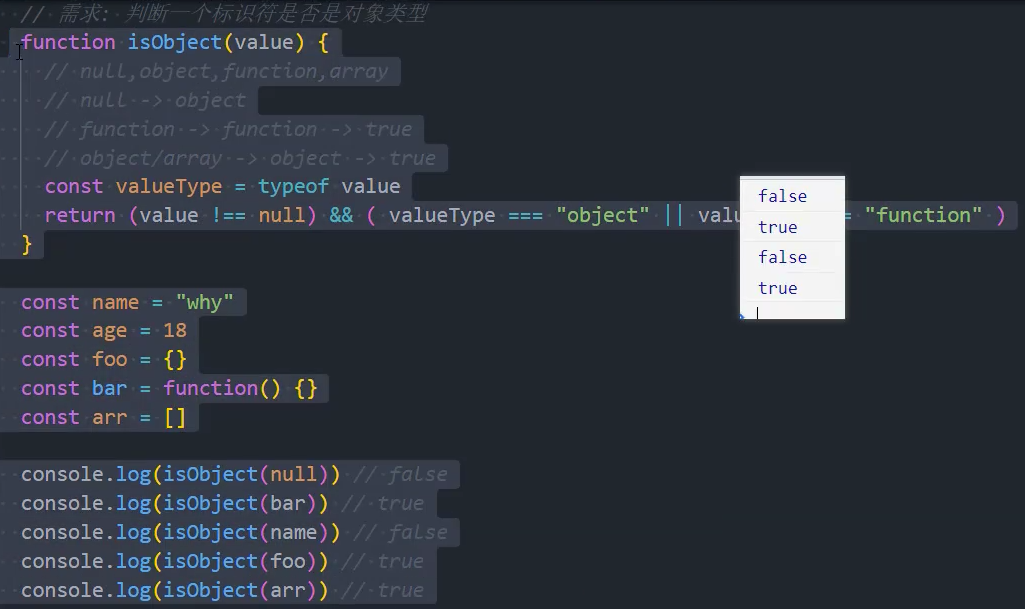
工具函数:判断对象
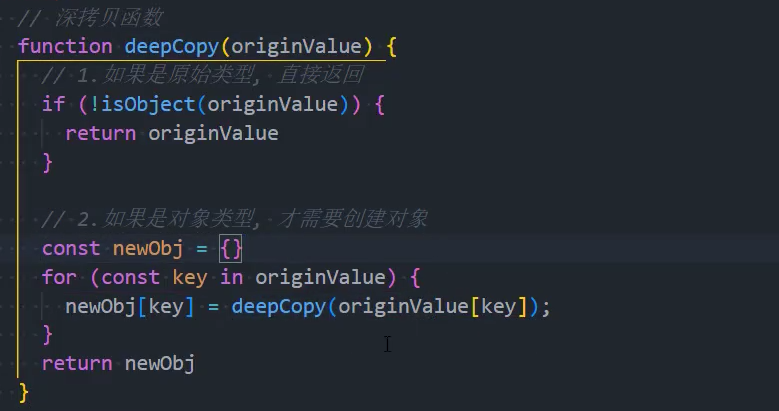
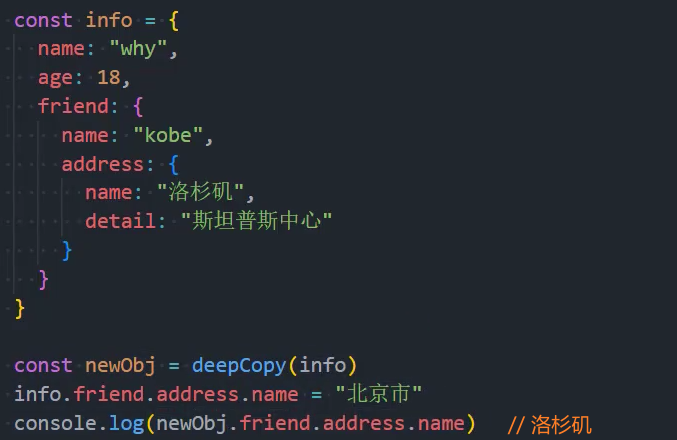
1、基本实现
2、优化:区分数组和对象
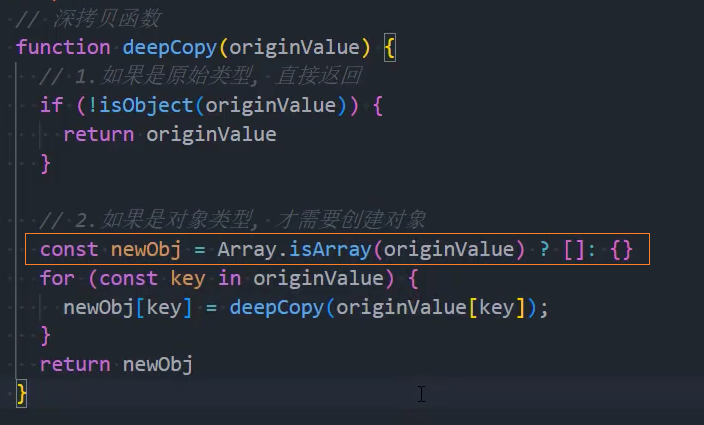

3、优化:其他类型-处理set
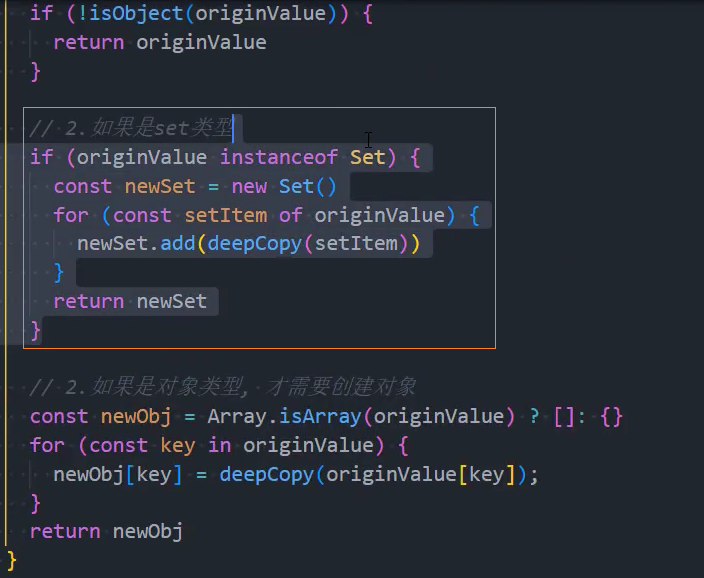
4、优化:其他类型-处理map
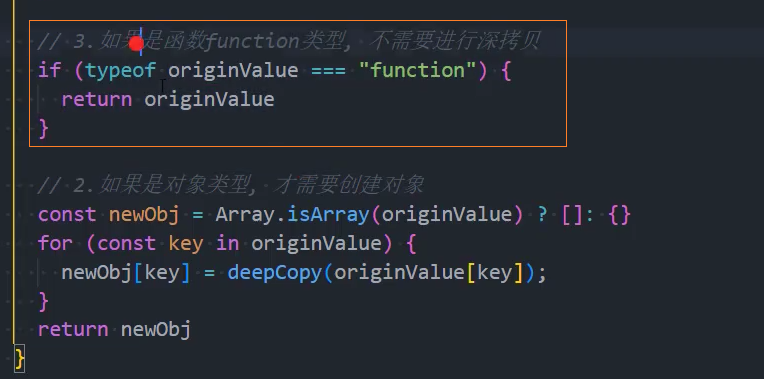
5、优化:其他类型-处理function
function: 不需要深拷贝
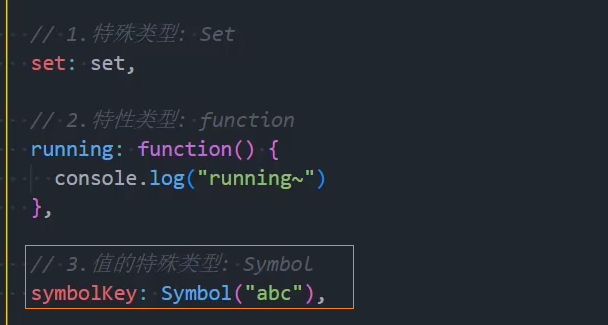
6、优化:其他类型-处理Symbol为值
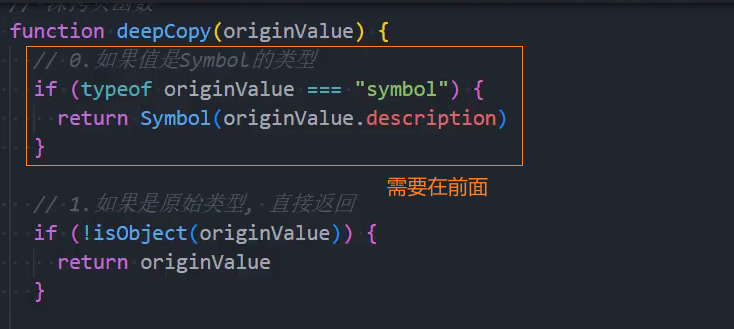
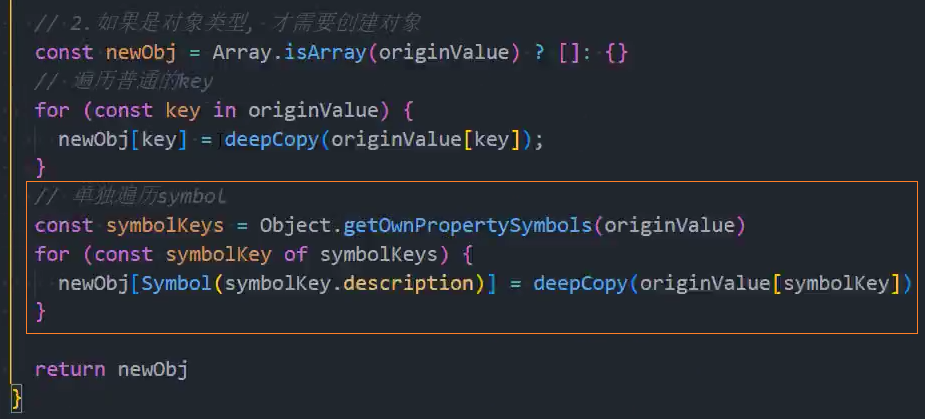
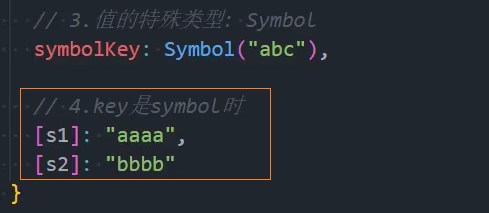
7、优化:其他类型-处理Symbol为key
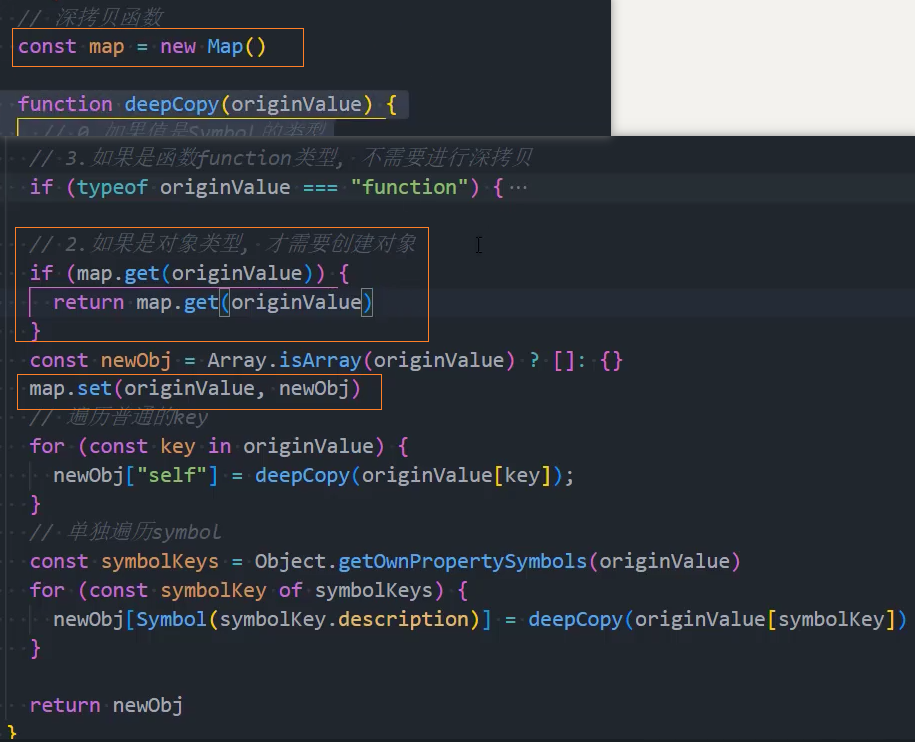
8、优化:处理循环引用
方案一:将每次新创建的对象保存到Map中,每次遍历前判断之前是否已经保存过了该对象
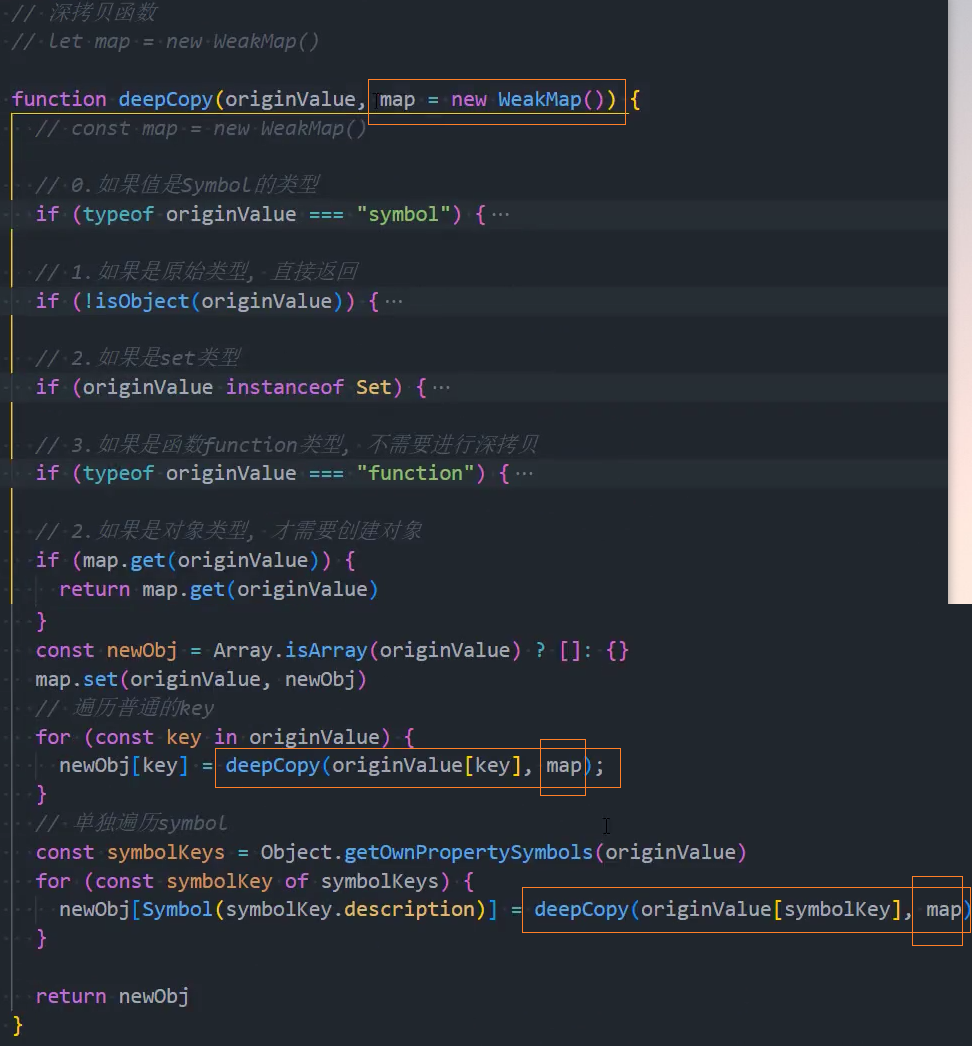
问题:需要在deeCopy外部定义一个map,并且每次拷贝完成后map依然会形成对对象的强引用,没有销毁
方案二(推荐):使用WeakMap替代Map;将map放入参数中并设置一个默认值new WeakMap()
手写-事件总线
自定义事件总线属于一种观察者模式,其中包括三个角色:
发布者(Publisher):发出事件(Event);
订阅者(Subscriber):订阅事件(Event),并且会进行响应(Handler);
事件总线(EventBus):无论是发布者还是订阅者都是通过事件总线作为中台的;
当然我们可以选择一些第三方库:
Vue2默认是带有事件总线的功能;
Vue3中推荐一些第三方库,比如mitt;
当然我们也可以实现自己的事件总线:
事件的监听方法on;
事件的发射方法emit;
事件的取消监听off;
1、基本实现
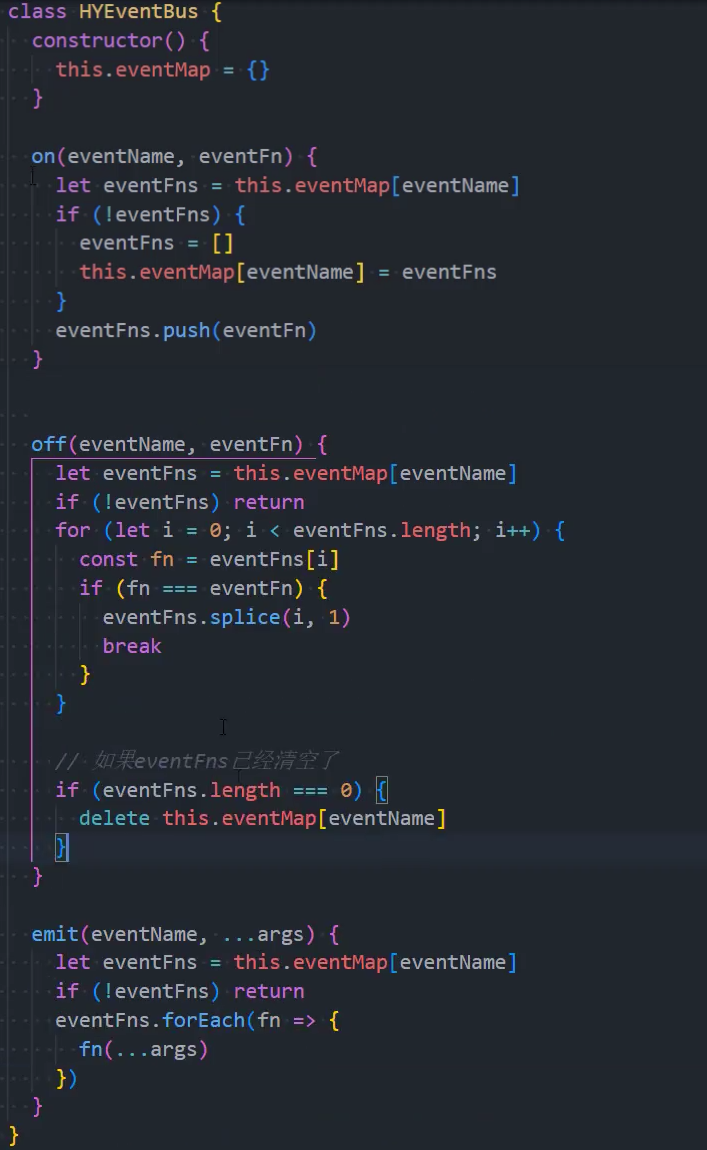
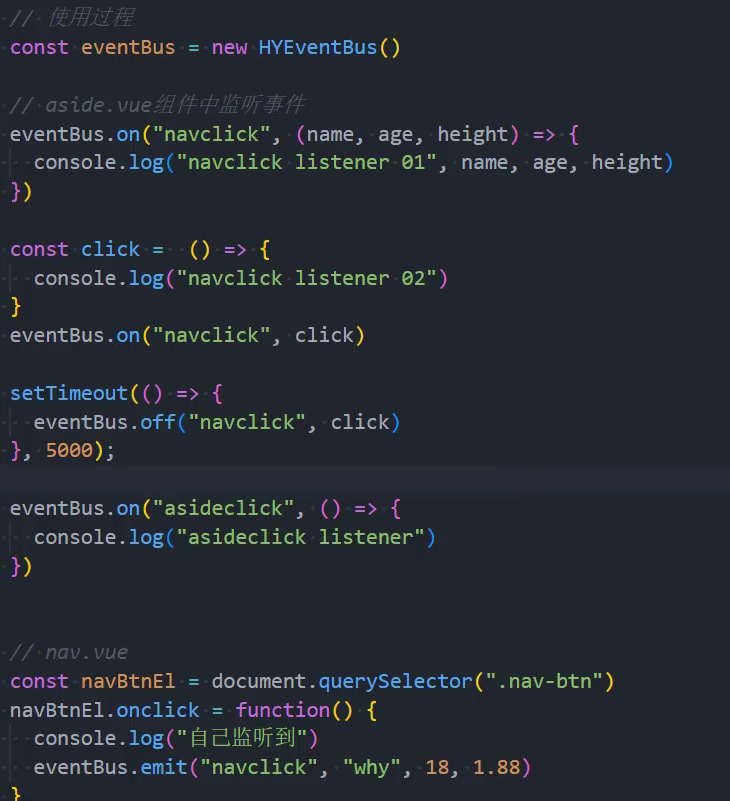
2、优化:绑定参数
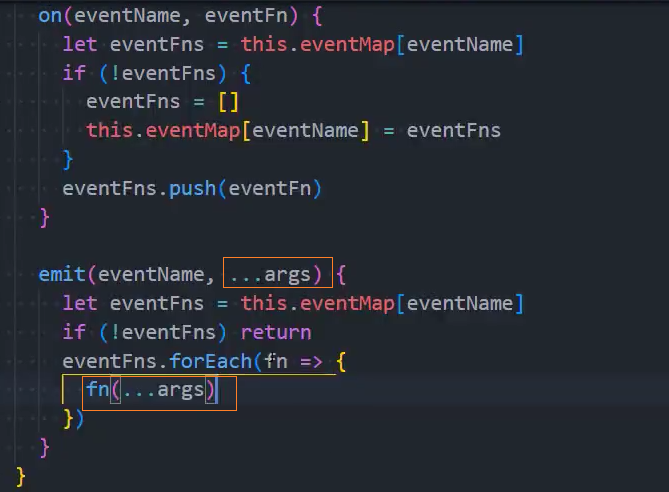
3、优化:移除监听
前后端分离
前后端分离的优势
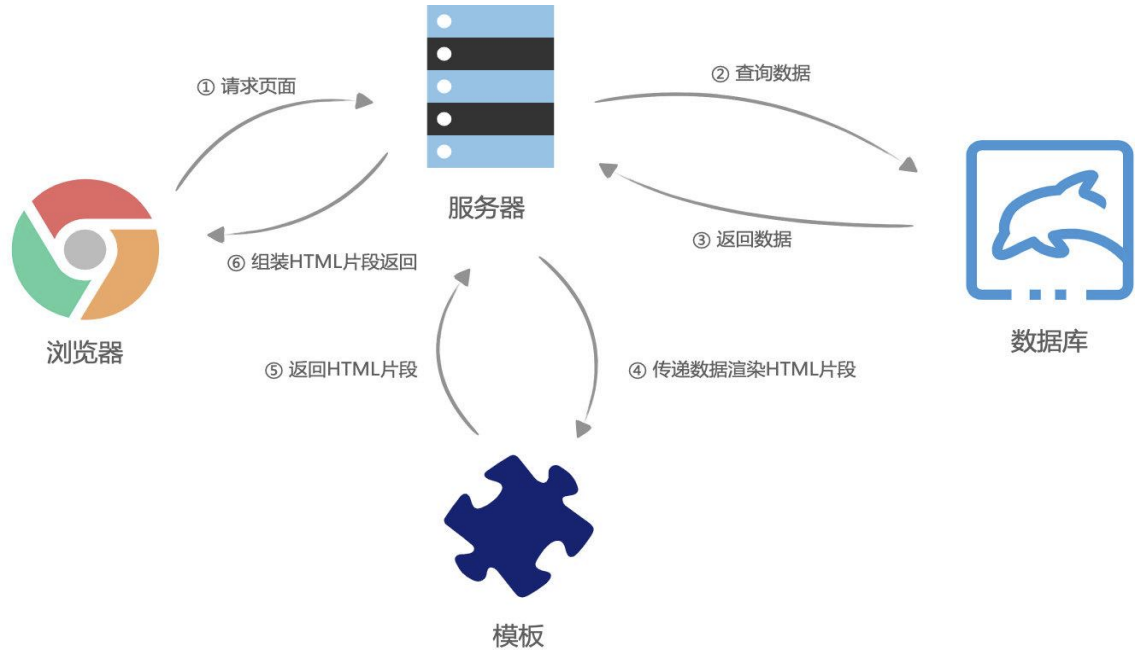
早期的网页都是通过后端渲染来完成的:服务器端渲染(SSR,server side render):
- 客户端发出请求 -> 服务端接收请求并返回相应HTML文档 -> 页面刷新,客户端加载新的HTML文档;
服务器端渲染的缺点:
当用户点击页面中的某个按钮向服务器发送请求时,页面本质上只是一些数据发生了变化,而此时服务器却要将重绘的整个页面再返回给浏览器加载,这显然有悖于程序员的“DRY( Don‘t repeat yourself )”原则;
而且明明只是一些数据的变化却迫使服务器要返回整个HTML文档,这本身也会给网络带宽带来不必要的开销。
有没有办法在页面数据变动时,只向服务器请求新的数据,并且在阻止页面刷新的情况下,动态的替换页面中展示的数据呢?
- 答案正是“AJAX”。
AJAX是“Asynchronous JavaScript And XML”的缩写(异步的JavaScript和XML),是一种实现 无页面刷新 获取服务器数据的技术。
- AJAX最吸引人的就是它的“异步”特性,也就是说它可以在不重新刷新页面的情况下与服务器通信,交换数据,或更新页面。
你可以使用AJAX最主要的两个特性做下列事:
在不重新加载页面的情况下发送请求给服务器;
接受并使用从服务器发来的数据。
网页的渲染过程 – 服务器端渲染
网页的渲染过程 – 前后端分离

HTTP
什么是HTTP?
什么是HTTP呢?我们来看一下维基百科的解释:
超文本传输协议(英语:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议;
HTTP是万维网的数据通信的基础,设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法;
通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识;
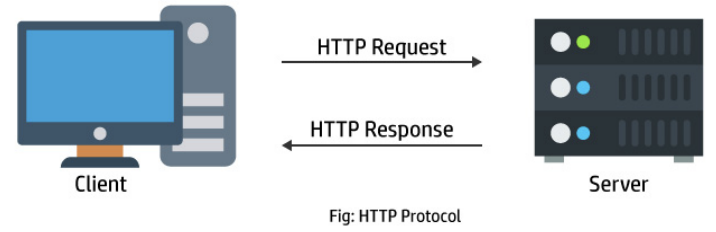
HTTP是一个客户端(用户)和服务端(网站)之间请求和响应的标准。
通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80);
- 我们称这个客户端为用户代理程序(user agent);
响应的服务器上存储着一些资源,比如HTML文件和图像。
- 我们称这个响应服务器为源服务器(origin server);
网页中资源的获取
我们网页中的资源通常是被放在Web资源服务器中,由浏览器自动发送HTTP请求来获取、解析、展示的。
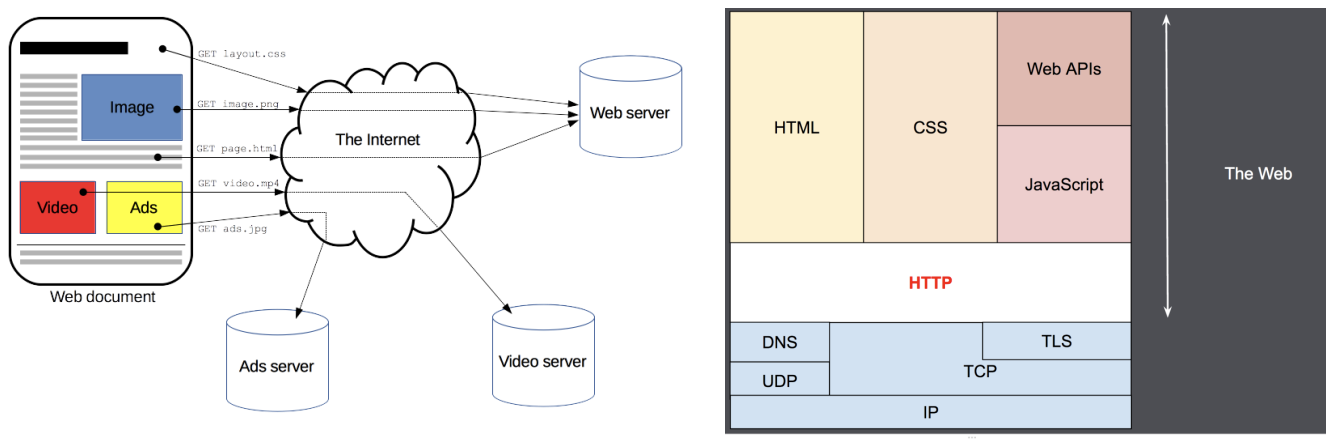
目前我们页面中很多数据是动态展示的:
- 比如页面中的数据展示、搜索数据、表单验证等等,也是通过在JavaScript中发送HTTP请求获取的;
HTTP的组成
一次HTTP请求主要包括:请求(Request)和响应(Response)
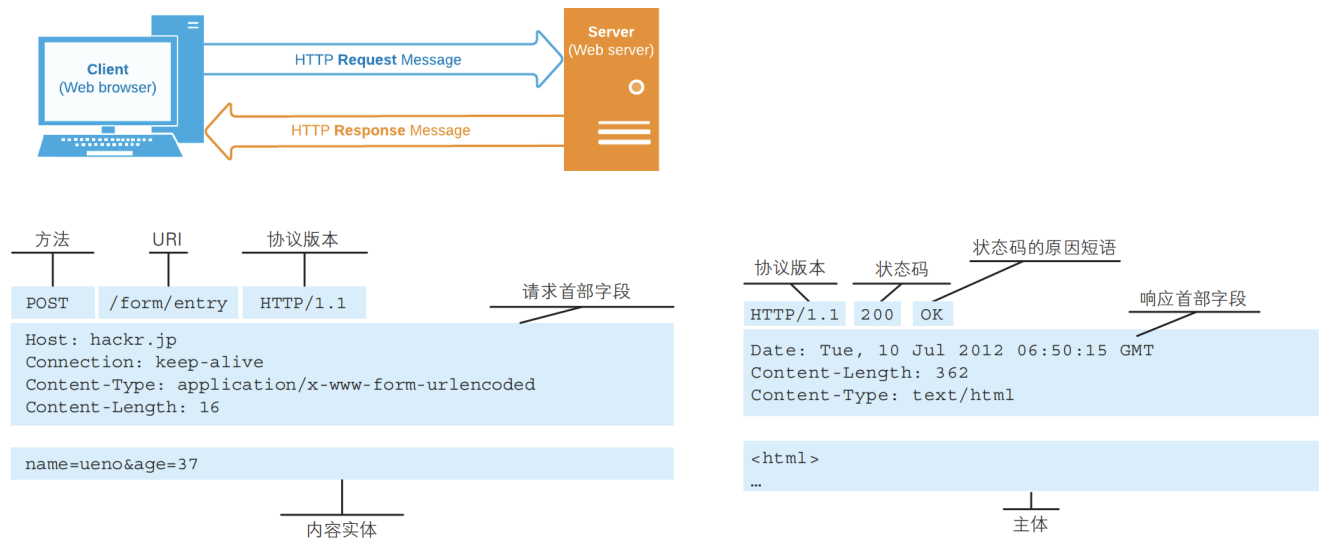
HTTP的版本
HTTP/0.9
发布于1991年;
只支持GET请求方法获取文本数据,当时主要是为了获取HTML页面内容;
HTTP/1.0
发布于1996年;
支持POST、HEAD等请求方法,支持请求头、响应头等,支持更多种数据类型(不再局限于文本数据) ;
但是浏览器的每次请求都需要与服务器建立一个TCP连接,请求处理完成后立即断开TCP连接,每次建立连接增加了性能损耗;
HTTP/1.1(目前使用最广泛的版本)
发布于1997年;
增加了PUT、DELETE等请求方法;
采用持久连接(Connection: keep-alive),多个请求可以共用同一个TCP连接;
2015年,HTTP/2.0
2018年,HTTP/3.0
HTTP的请求方式
在RFC中定义了一组请求方式,来表示要对给定资源执行的操作:
GET:GET 方法请求一个指定资源的表示形式,使用 GET 的请求应该只被用于获取数据。
HEAD:HEAD 方法请求一个与 GET 请求的响应相同的响应,但没有响应体。
- 比如在准备下载一个文件前,先获取文件的大小,再决定是否进行下载;
POST:POST 方法用于将实体提交到指定的资源。
PUT:PUT 方法用请求有效载荷(payload)替换目标资源的所有当前表示;
DELETE:DELETE 方法删除指定的资源;
PATC H:PATC H 方法用于对资源应部分修改;
CONNECT:CONNECT 方法建立一个到目标资源标识的服务器的隧道,通常用在代理服务器,网页开发很少用到。
TRACE:TRACE 方法沿着到目标资源的路径执行一个消息环回测试。
在开发中使用最多的是GET、POST请求;
- 在后续的后台管理项目中,我们也会使用PATC H、DELETE请求;
HTTPRequest Header(一)
在request对象的header中也包含很多有用的信息,客户端会默认传递过来一些信息:
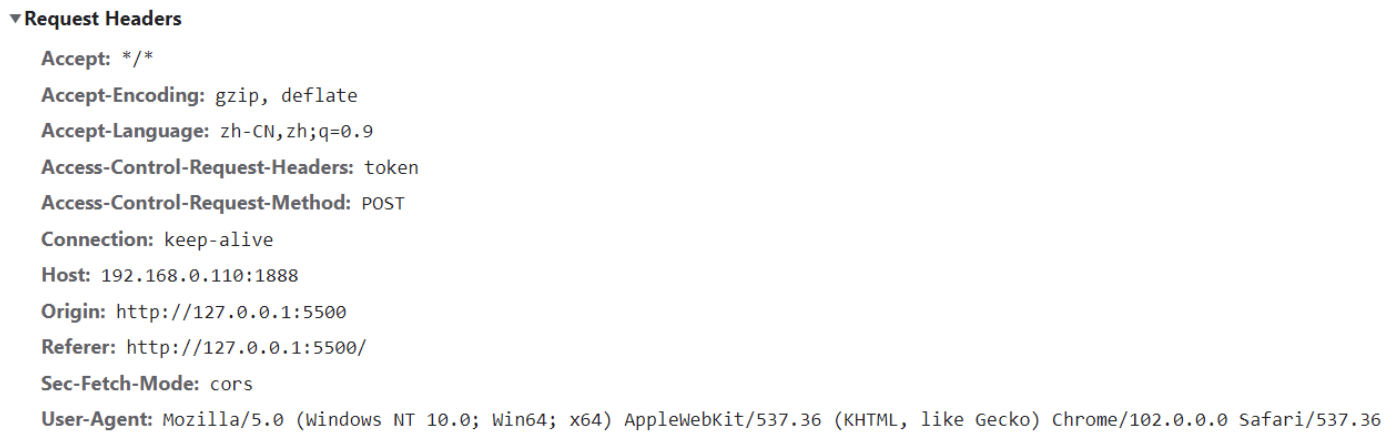
content-type是这次请求携带的数据的类型:
application/x-www-form-urlencoded:表示数据被编码成以 '&' 分隔的键 - 值对,同时以 '=' 分隔键和值
application/json:表示是一个json类型;
text/plain:表示是文本类型;
application/xml:表示是xml类型;
multipart/form-data:表示是上传文件;
HTTPRequest Header(二)
content-length:文件的大小长度
keep-alive:
http是基于TCP协议的,但是通常在进行一次请求和响应结束后会立刻中断;
在http1.0中,如果想要继续保持连接:
- 浏览器需要在请求头中添加 connection: keep-alive;
- 服务器需要在响应头中添加 connection:keey-alive;
- 当客户端再次放请求时,就会使用同一个连接,直接一方中断连接;
在http1.1中,所有连接默认是 connection: keep-alive的;
- 不同的Web服务器会有不同的保持 keep-alive的时间;
- Node中默认是5s中;
accept-encoding:告知服务器,客户端支持的文件压缩格式,比如js文件可以使用gzip编码,对应 .gz文件;
accept:告知服务器,客户端可接受文件的格式类型;
user-agent:客户端相关的信息;
HTTPResponse响应状态码
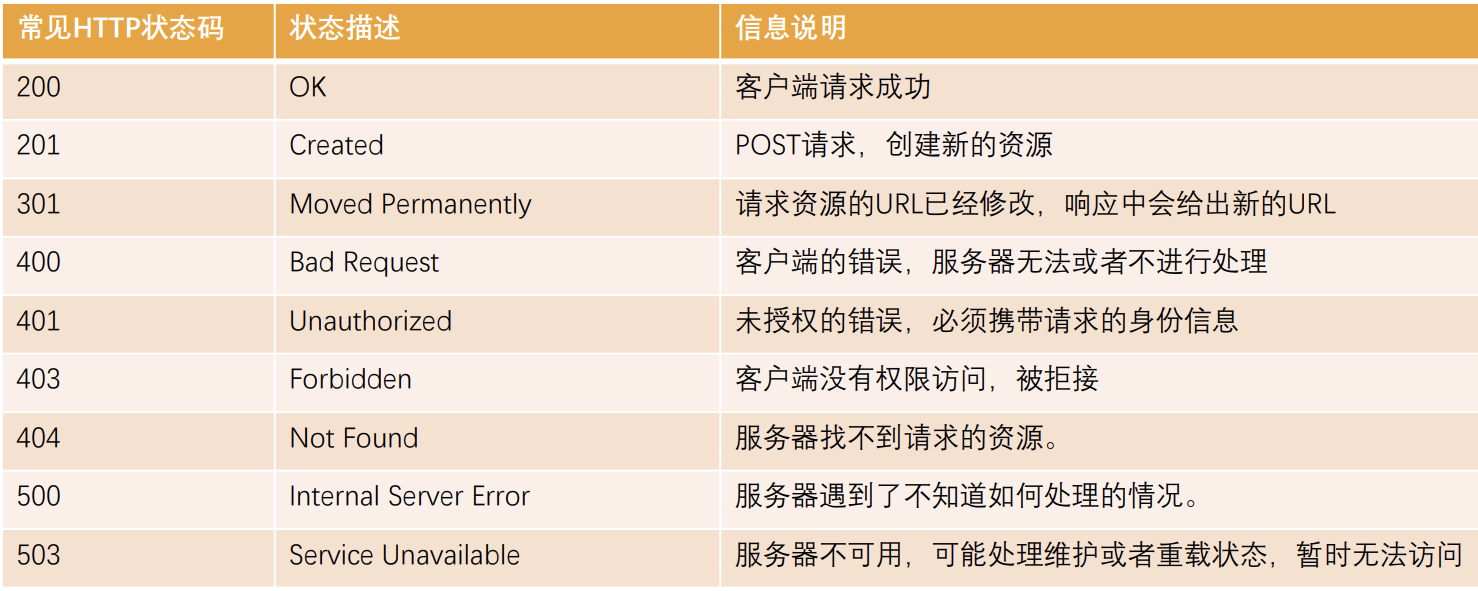
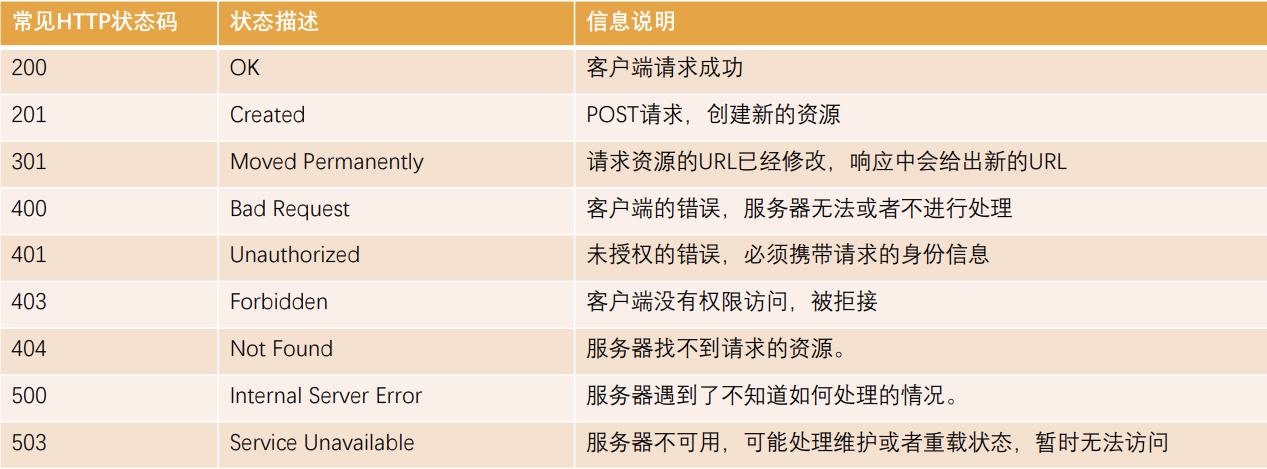
Http状态码(HttpStatus Code)是用来表示Http响应状态的数字代码:
Http状态码非常多,可以根据不同的情况,给客户端返回不同的状态码;
MDN响应码解析地址:https://developer.mozilla.org/zh-CN/docs/web/http/status
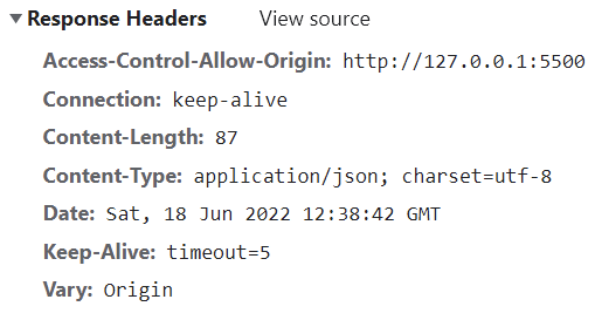
HTTPRequest Header
响应的header中包括一些服务器给客户端的信息:
Chrome安装插件 - FeHelper
为了之后查看数据更加的便捷、优雅,我们安装一个Chrome插件:
方式一:可以直接通过Chrome的扩展商店安装;
方式二:手动安装
Ajax
AJAX发送请求
AJAX 是异步的 JavaScript 和 XML(Asynchronous JavaScript And XML)
- 它可以使用 JSON,XML,HTML 和 text 文本等格式发送和接收数据;
如何来完成AJAX请求呢?
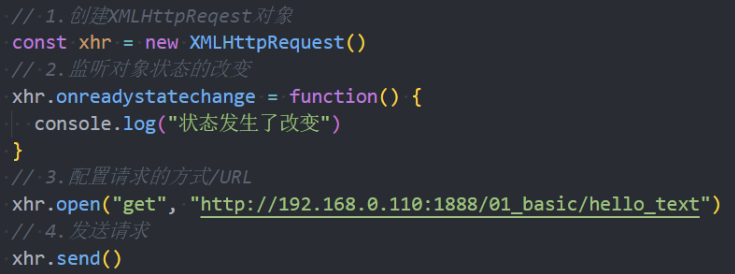
第一步:创建网络请求的AJAX对象(使用XMLHttpRequest)
第二步:监听XMLHttpRequest对象状态的变化,或者监听onload事件(请求完成时触发);
第三步:配置网络请求(通过open方法);
第四步:发送send网络请求;
XMLHttpRequest的state(状态)
事实上,我们在一次网络请求中看到状态发生了很多次变化,这是因为对于一次请求来说包括如下的状态:
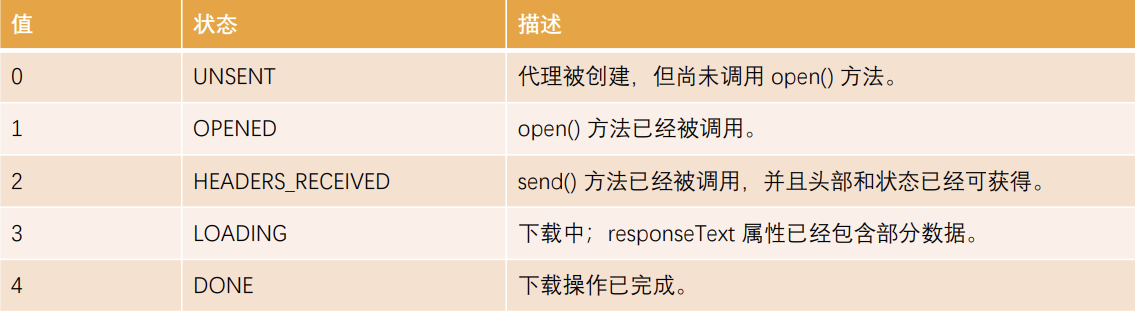
注意:这个状态并非是HTTP的相应状态,而是记录的XMLHttpRequest对象的状态变化。
- http响应状态通过status获取;
发送同步请求:
- 将open的第三个参数设置为false

XMLHttpRequest其他事件监听
除了onreadystatechange还有其他的事件可以监听
loadstart:请求开始。
progress: 一个响应数据包到达,此时整个 response body 都在 response 中。
abort:调用 xhr.abort() 取消了请求。
error:发生连接错误,例如,域错误。不会发生诸如 404 这类的 HTT- 错误。
load:请求成功完成。
timeout:由于请求超时而取消了该请求(仅发生在设置了 timeout 的情况下)。
loadend:在 load,error,timeout 或 abort 之后触发。
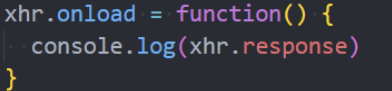
我们也可以使用load来获取数据:
响应数据和响应类型
发送了请求后,我们需要获取对应的结果:response属性
XMLHttpRequest response 属性返回响应的正文内容;
返回的类型取决于responseType的属性设置;
通过responseType可以设置获取数据的类型
- 如果将 responseType 的值设置为空字符串,则会使用 text 作为默认值。

和responseText、responseXML的区别:
早期通常服务器返回的数据是普通的文本和XML,所以我们通常会通过responseText、 responseXML来获取响应结果;
之后将它们转化成JavaScript对象形式;
目前服务器基本返回的都是json数据,直接设置为json即可;
HTTP响应的状态status
XMLHttpRequest的state是用于记录xhr对象本身的状态变化,并非针对于HTTP的网络请求状态。
如果我们希望获取HTTP响应的网络状态,可以通过status和statusText来获取:

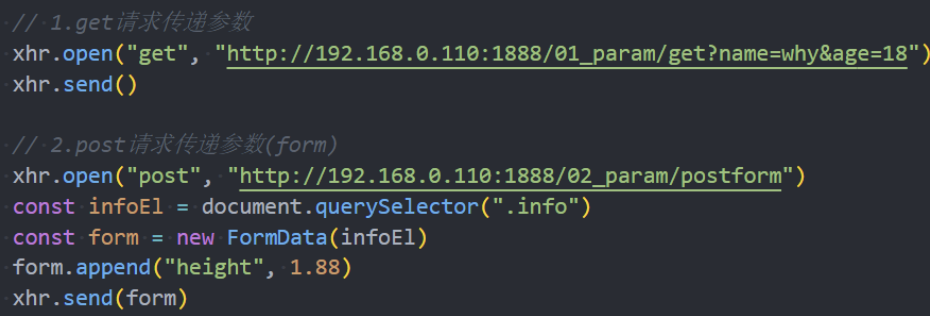
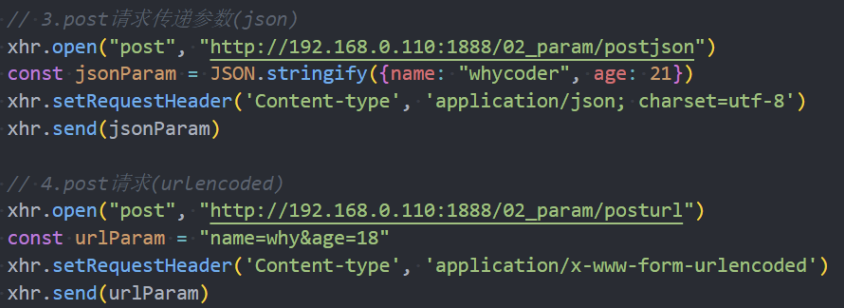
GET/POST请求传递参数
在开发中,我们使用最多的是GET和POST请求,在发送请求的过程中,我们也可以传递给服务器数据。
常见的传递给服务器数据的方式有如下几种:
方式一:GET请求的query参数
方式二:POST请求 x-www-form-urlencoded 格式
方式三:POST请求 FormData 格式
方式四:POST请求 JSON 格式
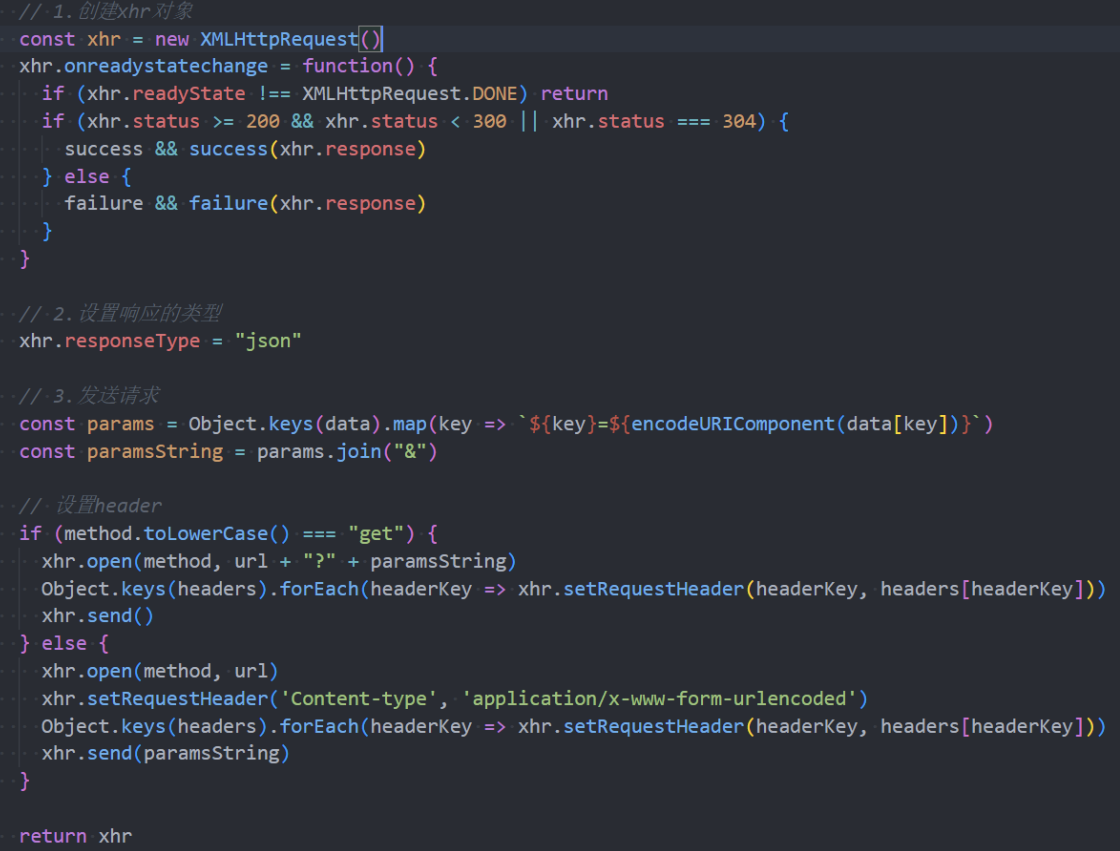
ajax网络请求封装
延迟时间timeout和取消请求
在网络请求的过程中,为了避免过长的时间服务器无法返回数据,通常我们会为请求设置一个超时时间:timeout。
当达到超时时间后依然没有获取到数据,那么这个请求会自动被取消掉;
默认值为0,表示没有设置超时时间;
我们也可以通过abort方法强制取消请求;
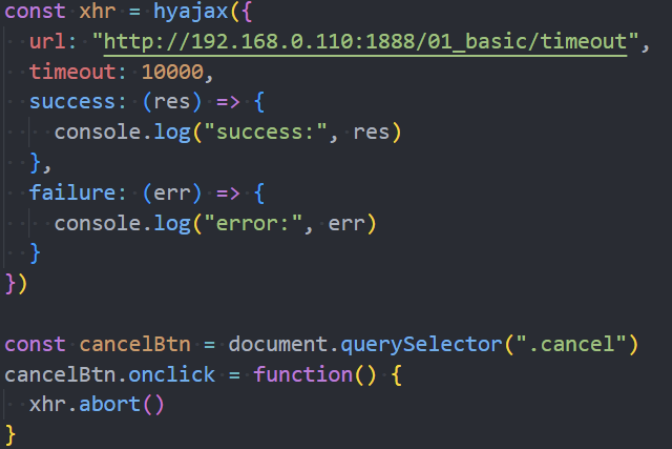
Fetch
认识Fetch和Fetch API
Fetch可以看做是早期的XMLHttpRequest的替代方案,它提供了一种更加现代的处理方案:
比如返回值是一个Promise,提供了一种更加优雅的处理结果方式
- 在请求发送成功时,调用resolve回调then;
- 在请求发送失败时,调用reject回调catch;
比如不像XMLHttpRequest一样,所有的操作都在一个对象上;
fetch函数的使用:

input:定义要获取的资源地址,可以是一个URL字符串,也可以使用一个Request对象(实验性特性)类型;
init:其他初始化参数
- method: 请求使用的方法,如 GET、POST;
- headers: 请求的头信息;
- body: 请求的 body 信息;
Fetch数据的响应(Response)
Fetch的数据响应主要分为两个阶段:
阶段一:当服务器返回了响应(response)
fetch 返回的 promise 就使用内建的 Response class 对象来对响应头进行解析;
在这个阶段,我们可以通过检查响应头,来检查 HTTP状态以确定请求是否成功;
如果 fetch 无法建立一个 HTTP请求,例如网络问题,亦或是请求的网址不存在,那么 promise 就会 reject;
异常的 HTTP状态,例如 404 或 500,不会导致出现 error;
我们可以在 response 的属性中看到 HTTP状态:
status:HTTP状态码,例如 200;
ok:布尔值,如果 HTTP状态码为 200-299,则为 true;
第二阶段,为了获取 response body,我们需要使用一个其他的方法调用。
response.text() —— 读取 response,并以文本形式返回 response;
response.json() —— 将 response 解析为 JSON;
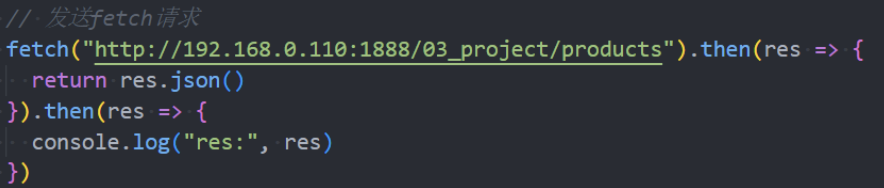
Fetch网络请求的演练
基于Promise的使用方案:
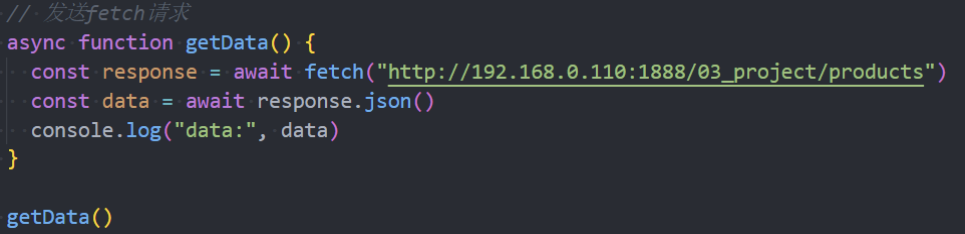
基于async、await的使用方案:
Fetch POST请求
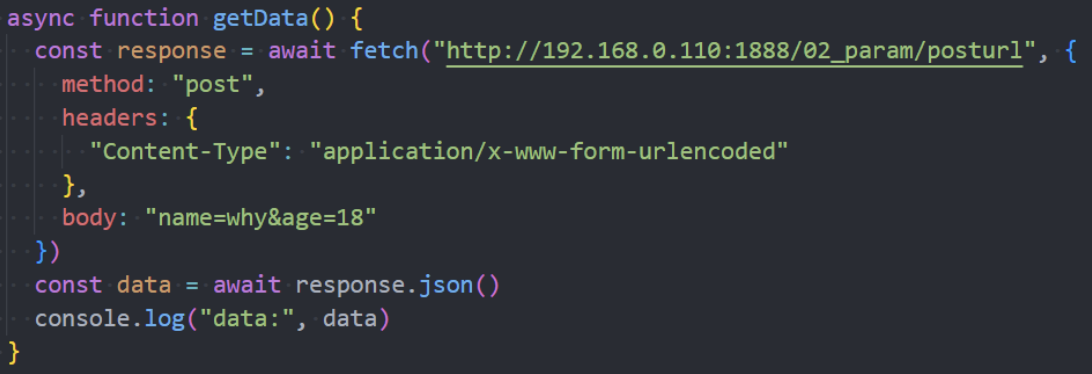
创建一个 POST 请求,或者其他方法的请求,我们需要使用 fetch 选项:
method:HTTP方法,例如 POST,
body:request body,其中之一:
- 字符串(例如 JSON 编码的),
- FormData 对象,以 multipart/form-data 形式发送数据,
文件上传
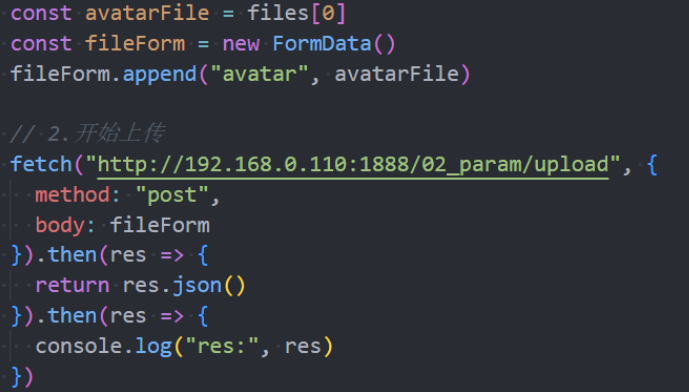
XMLHttpRequest文件上传
文件上传是开发中经常遇到的需求,比如头像上传、照片等。
- 要想真正理解文件上传,必须了解服务器如何处理上传的文件信息;
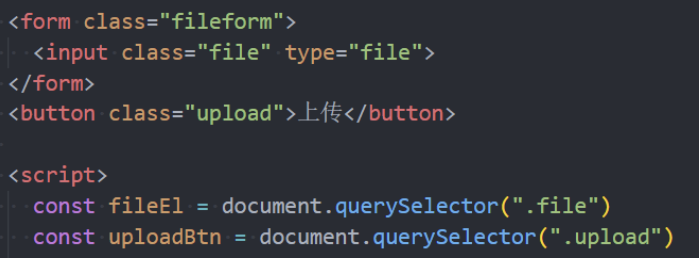
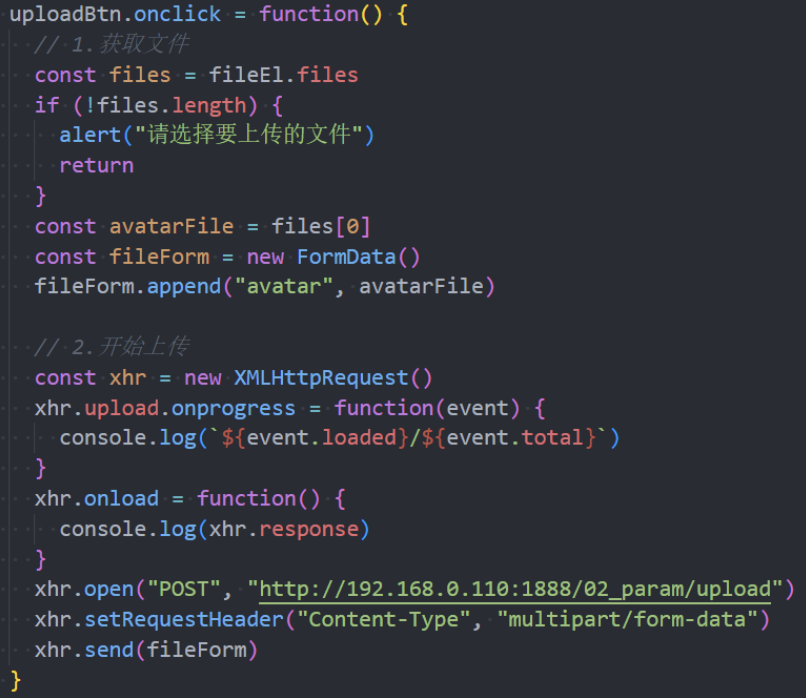
Fetch文件上传
Fetch也支持文件上传,但是Fetch没办法监听进度。